 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multimodality Learning for UAV Video Aesthetic Quality Assessment
Nov 04, 2020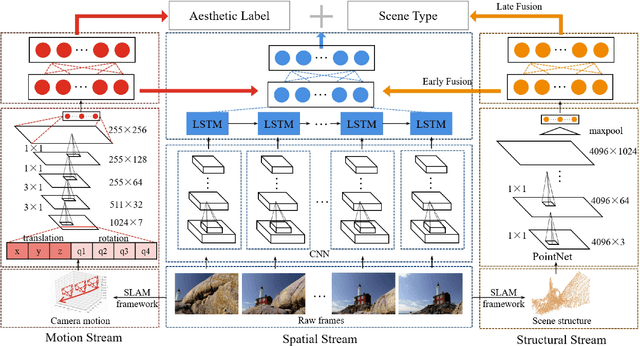


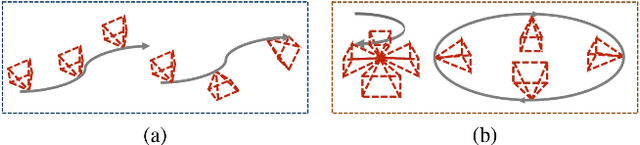
Despite the growing number of unmanned aerial vehicles (UAVs) and aerial videos, there is a paucity of studies focusing on the aesthetics of aerial videos that can provide valuable information for improving the aesthetic quality of aerial photography. In this article, we present a method of deep multimodality learning for UAV video aesthetic quality assessment. More specifically, a multistream framework is designed to exploit aesthetic attributes from multiple modalities, including spatial appearance, drone camera motion, and scene structure. A novel specially designed motion stream network is proposed for this new multistream framework. We construct a dataset with 6,000 UAV video shots captured by drone cameras. Our model can judge whether a UAV video was shot by professional photographers or amateurs together with the scene type classification. The experimental results reveal that our method outperforms the video classification methods and traditional SVM-based methods for video aesthetics. In addition, we present three application examples of UAV video grading, professional segment detection and aesthetic-based UAV path planning using the proposed method.
Joint Chromatic and Polarimetric Demosaicing via Sparse Coding
Dec 16, 2019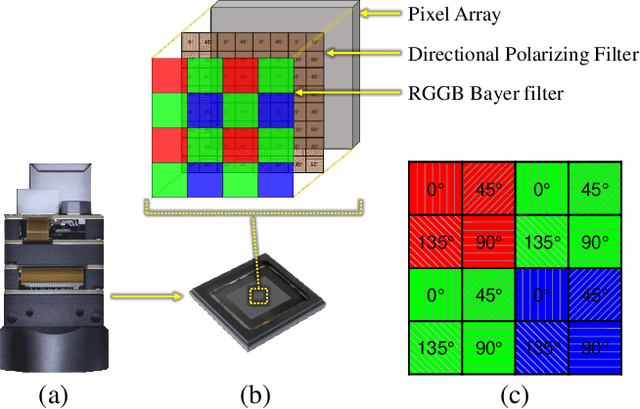
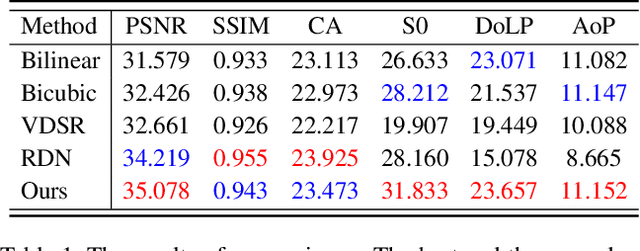
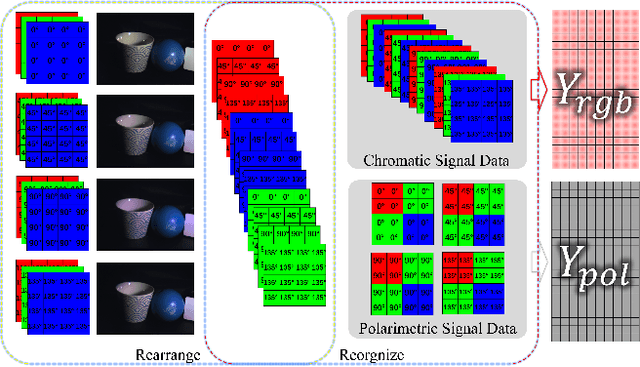

Thanks to the latest progress in image sensor manufacturing technology, the emergence of the single-chip polarized color sensor is likely to bring advantages to computer vision tasks. Despite the importance of the sensor, joint chromatic and polarimetric demosaicing is the key to obtaining the high-quality RGB-Polarization image for the sensor. Since the polarized color sensor is equipped with a new type of chip, the demosaicing problem cannot be currently well-addressed by former methods. In this paper, we propose a joint chromatic and polarimetric demosaicing model to address this challenging problem. To solve this non-convex problem, we further present a sparse representation-based optimization strategy that utilizes chromatic information and polarimetric information to jointly optimize the model. In addition, we build an optical data acquisition system to collect an RGB-Polarization dataset. Results of both qualitative and quantitative experiments have shown that our method is capable of faithfully recovering full 12-channel chromatic and polarimetric information for each pixel from a single mosaic input image. Moreover, we show that the proposed method can perform well not only on the synthetic data but the real captured data.
Shape2Motion: Joint Analysis of Motion Parts and Attributes from 3D Shapes
Mar 12, 2019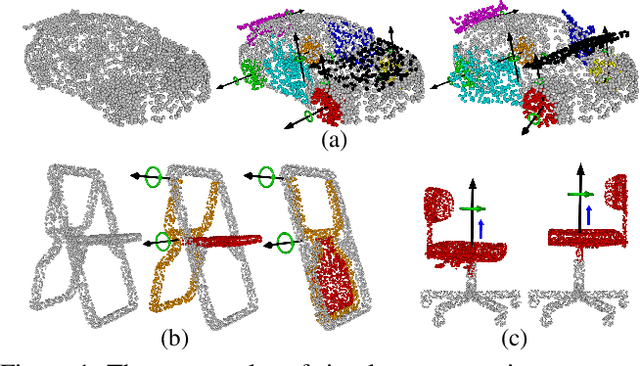
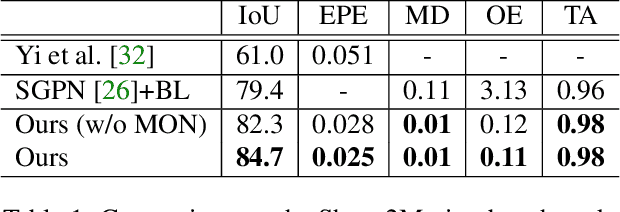
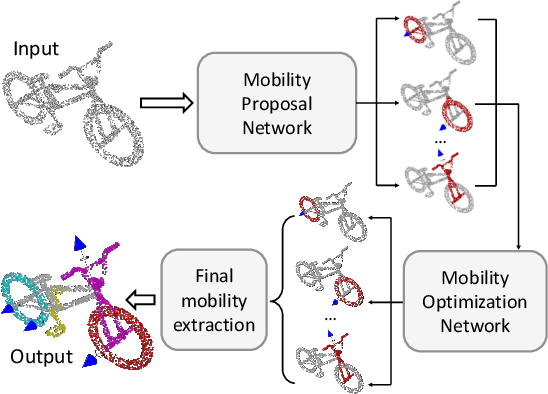
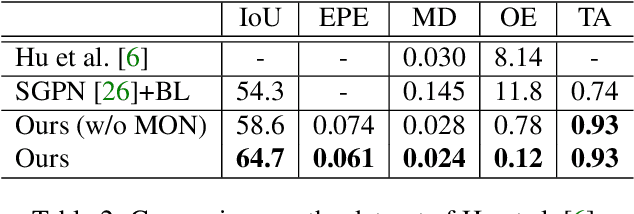
For the task of mobility analysis of 3D shapes, we propose joint analysis for simultaneous motion part segmentation and motion attribute estimation, taking a single 3D model as input. The problem is significantly different from those tackled in the existing works which assume the availability of either a pre-existing shape segmentation or multiple 3D models in different motion states. To that end, we develop Shape2Motion which takes a single 3D point cloud as input, and jointly computes a mobility-oriented segmentation and the associated motion attributes. Shape2Motion is comprised of two deep neural networks designed for mobility proposal generation and mobility optimization, respectively. The key contribution of these networks is the novel motion-driven features and losses used in both motion part segmentation and motion attribute estimation. This is based on the observation that the movement of a functional part preserves the shape structure. We evaluate Shape2Motion with a newly proposed benchmark for mobility analysis of 3D shapes. Results demonstrate that our method achieves the state-of-the-art performance both in terms of motion part segmentation and motion attribute estimation.
Learning to Group and Label Fine-Grained Shape Components
Sep 13, 2018
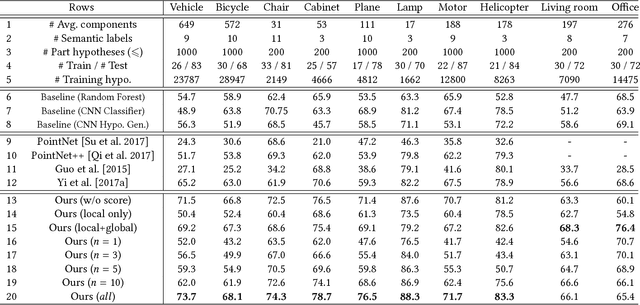


A majority of stock 3D models in modern shape repositories are assembled with many fine-grained components. The main cause of such data form is the component-wise modeling process widely practiced by human modelers. These modeling components thus inherently reflect some function-based shape decomposition the artist had in mind during modeling. On the other hand, modeling components represent an over-segmentation since a functional part is usually modeled as a multi-component assembly. Based on these observations, we advocate that labeled segmentation of stock 3D models should not overlook the modeling components and propose a learning solution to grouping and labeling of the fine-grained components. However, directly characterizing the shape of individual components for the purpose of labeling is unreliable, since they can be arbitrarily tiny and semantically meaningless. We propose to generate part hypotheses from the components based on a hierarchical grouping strategy, and perform labeling on those part groups instead of directly on the components. Part hypotheses are mid-level elements which are more probable to carry semantic information. A multiscale 3D convolutional neural network is trained to extract context-aware features for the hypotheses. To accomplish a labeled segmentation of the whole shape, we formulate higher-order conditional random fields (CRFs) to infer an optimal label assignment for all components. Extensive experiments demonstrate that our method achieves significantly robust labeling results on raw 3D models from public shape repositories. Our work also contributes the first benchmark for component-wise labeling.
* Accepted to SIGGRAPH Asia 2018. Corresponding Author: Kai Xu (kevin.kai.xu@gmail.com)