 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnot Forcing: Taming Autoregressive Video Diffusion Models for Real-time Infinite Interactive Portrait Animation
Dec 25, 2025Real-time portrait animation is essential for interactive applications such as virtual assistants and live avatars, requiring high visual fidelity, temporal coherence, ultra-low latency, and responsive control from dynamic inputs like reference images and driving signals. While diffusion-based models achieve strong quality, their non-causal nature hinders streaming deployment. Causal autoregressive video generation approaches enable efficient frame-by-frame generation but suffer from error accumulation, motion discontinuities at chunk boundaries, and degraded long-term consistency. In this work, we present a novel streaming framework named Knot Forcing for real-time portrait animation that addresses these challenges through three key designs: (1) a chunk-wise generation strategy with global identity preservation via cached KV states of the reference image and local temporal modeling using sliding window attention; (2) a temporal knot module that overlaps adjacent chunks and propagates spatio-temporal cues via image-to-video conditioning to smooth inter-chunk motion transitions; and (3) A "running ahead" mechanism that dynamically updates the reference frame's temporal coordinate during inference, keeping its semantic context ahead of the current rollout frame to support long-term coherence. Knot Forcing enables high-fidelity, temporally consistent, and interactive portrait animation over infinite sequences, achieving real-time performance with strong visual stability on consumer-grade GPUs.
SyncAnyone: Implicit Disentanglement via Progressive Self-Correction for Lip-Syncing in the wild
Dec 25, 2025High-quality AI-powered video dubbing demands precise audio-lip synchronization, high-fidelity visual generation, and faithful preservation of identity and background. Most existing methods rely on a mask-based training strategy, where the mouth region is masked in talking-head videos, and the model learns to synthesize lip movements from corrupted inputs and target audios. While this facilitates lip-sync accuracy, it disrupts spatiotemporal context, impairing performance on dynamic facial motions and causing instability in facial structure and background consistency. To overcome this limitation, we propose SyncAnyone, a novel two-stage learning framework that achieves accurate motion modeling and high visual fidelity simultaneously. In Stage 1, we train a diffusion-based video transformer for masked mouth inpainting, leveraging its strong spatiotemporal modeling to generate accurate, audio-driven lip movements. However, due to input corruption, minor artifacts may arise in the surrounding facial regions and the background. In Stage 2, we develop a mask-free tuning pipeline to address mask-induced artifacts. Specifically, on the basis of the Stage 1 model, we develop a data generation pipeline that creates pseudo-paired training samples by synthesizing lip-synced videos from the source video and random sampled audio. We further tune the stage 2 model on this synthetic data, achieving precise lip editing and better background consistency. Extensive experiments show that our method achieves state-of-the-art results in visual quality, temporal coherence, and identity preservation under in-the wild lip-syncing scenarios.
Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

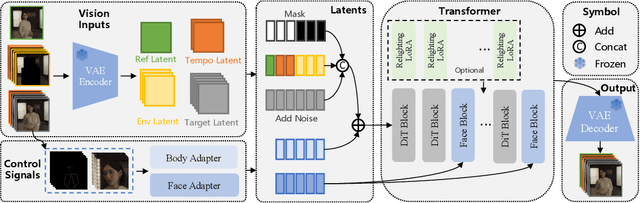
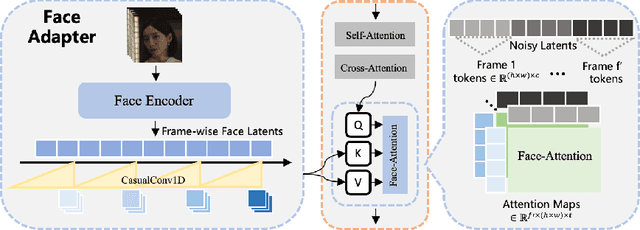
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
Animate Anyone 2: High-Fidelity Character Image Animation with Environment Affordance
Feb 10, 2025



Recent character image animation methods based on diffusion models, such as Animate Anyone, have made significant progress in generating consistent and generalizable character animations. However, these approaches fail to produce reasonable associations between characters and their environments. To address this limitation, we introduce Animate Anyone 2, aiming to animate characters with environment affordance. Beyond extracting motion signals from source video, we additionally capture environmental representations as conditional inputs. The environment is formulated as the region with the exclusion of characters and our model generates characters to populate these regions while maintaining coherence with the environmental context. We propose a shape-agnostic mask strategy that more effectively characterizes the relationship between character and environment. Furthermore, to enhance the fidelity of object interactions, we leverage an object guider to extract features of interacting objects and employ spatial blending for feature injection. We also introduce a pose modulation strategy that enables the model to handle more diverse motion patterns. Experimental results demonstrate the superior performance of the proposed method.
Parsing-based View-aware Embedding Network for Vehicle Re-Identification
Apr 10, 2020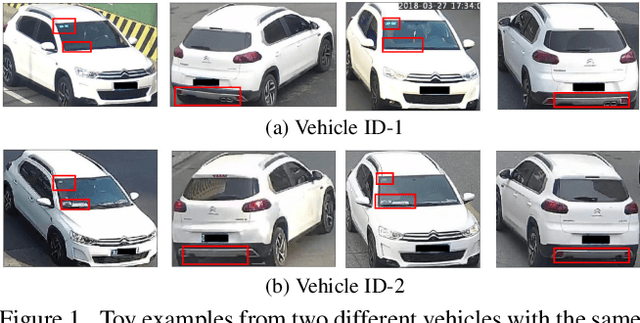
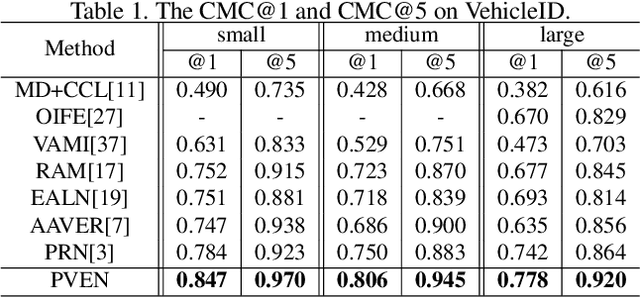
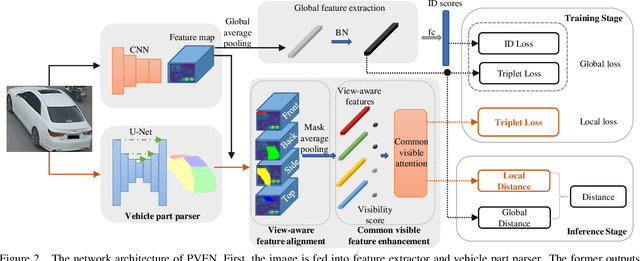
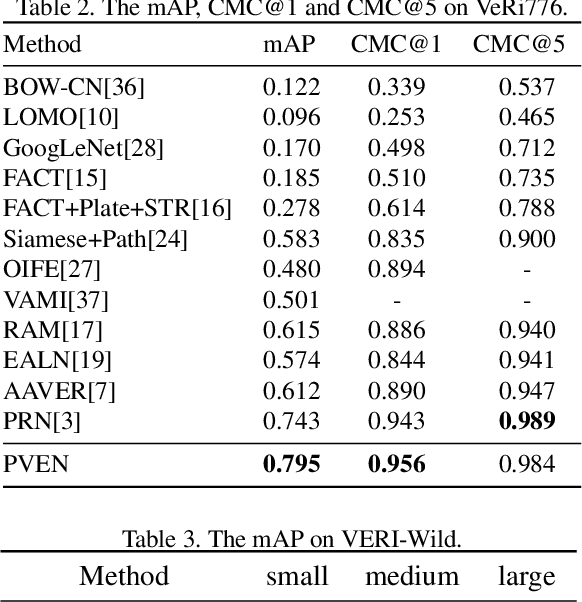
Vehicle Re-Identification is to find images of the same vehicle from various views in the cross-camera scenario. The main challenges of this task are the large intra-instance distance caused by different views and the subtle inter-instance discrepancy caused by similar vehicles. In this paper, we propose a parsing-based view-aware embedding network (PVEN) to achieve the view-aware feature alignment and enhancement for vehicle ReID. First, we introduce a parsing network to parse a vehicle into four different views, and then align the features by mask average pooling. Such alignment provides a fine-grained representation of the vehicle. Second, in order to enhance the view-aware features, we design a common-visible attention to focus on the common visible views, which not only shortens the distance among intra-instances, but also enlarges the discrepancy of inter-instances. The PVEN helps capture the stable discriminative information of vehicle under different views. The experiments conducted on three datasets show that our model outperforms state-of-the-art methods by a large margin.
Adaptive Reconstruction Network for Weakly Supervised Referring Expression Grounding
Aug 28, 2019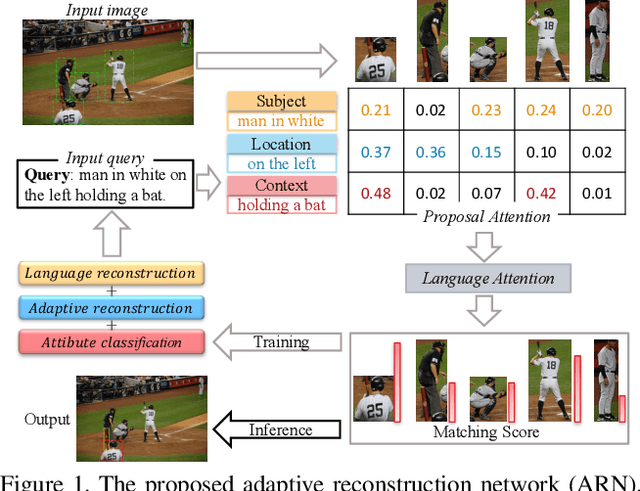
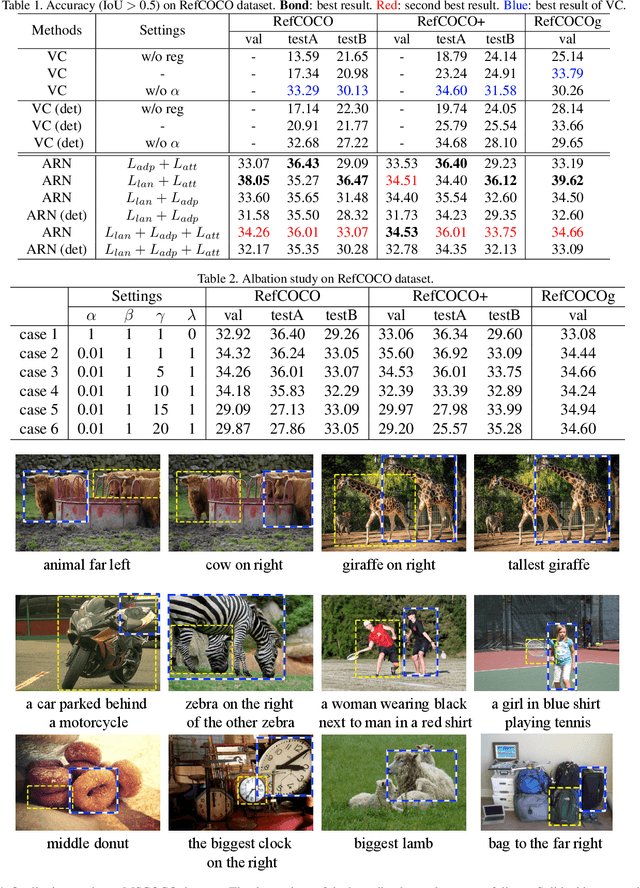
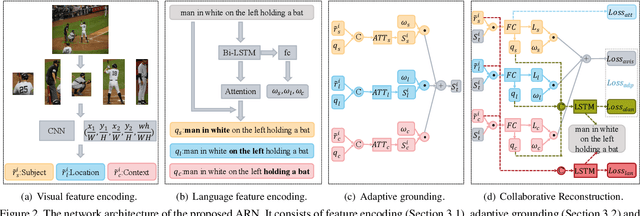
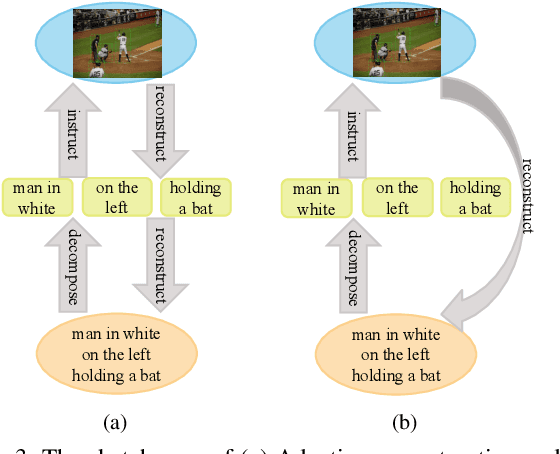
Weakly supervised referring expression grounding aims at localizing the referential object in an image according to the linguistic query, where the mapping between the referential object and query is unknown in the training stage. To address this problem, we propose a novel end-to-end adaptive reconstruction network (ARN). It builds the correspondence between image region proposal and query in an adaptive manner: adaptive grounding and collaborative reconstruction. Specifically, we first extract the subject, location and context features to represent the proposals and the query respectively. Then, we design the adaptive grounding module to compute the matching score between each proposal and query by a hierarchical attention model. Finally, based on attention score and proposal features, we reconstruct the input query with a collaborative loss of language reconstruction loss, adaptive reconstruction loss, and attribute classification loss. This adaptive mechanism helps our model to alleviate the variance of different referring expressions. Experiments on four large-scale datasets show ARN outperforms existing state-of-the-art methods by a large margin. Qualitative results demonstrate that the proposed ARN can better handle the situation where multiple objects of a particular category situated together.