 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

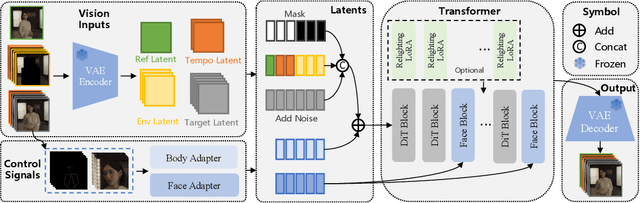
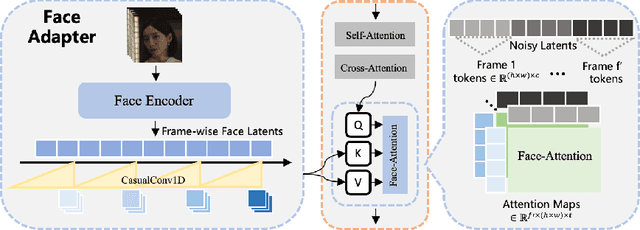
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
Channel-wise Alignment for Adaptive Object Detection
Sep 07, 2020


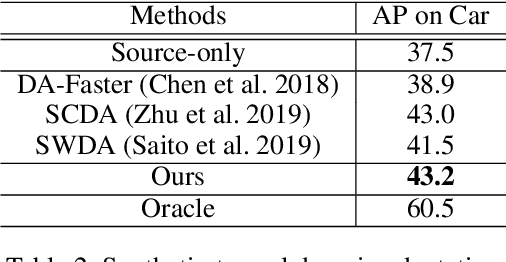
Generic object detection has been immensely promoted by the development of deep convolutional neural networks in the past decade. However, in the domain shift circumstance, the changes in weather, illumination, etc., often cause domain gap, and thus performance drops substantially when detecting objects from one domain to another. Existing methods on this task usually draw attention on the high-level alignment based on the whole image or object of interest, which naturally, cannot fully utilize the fine-grained channel information. In this paper, we realize adaptation from a thoroughly different perspective, i.e., channel-wise alignment. Motivated by the finding that each channel focuses on a specific pattern (e.g., on special semantic regions, such as car), we aim to align the distribution of source and target domain on the channel level, which is finer for integration between discrepant domains. Our method mainly consists of self channel-wise and cross channel-wise alignment. These two parts explore the inner-relation and cross-relation of attention regions implicitly from the view of channels. Further more, we also propose a RPN domain classifier module to obtain a domain-invariant RPN network. Extensive experiments show that the proposed method performs notably better than existing methods with about 5% improvement under various domain-shift settings. Experiments on different task (e.g. instance segmentation) also demonstrate its good scalability.
TSIT: A Simple and Versatile Framework for Image-to-Image Translation
Jul 25, 2020



We introduce a simple and versatile framework for image-to-image translation. We unearth the importance of normalization layers, and provide a carefully designed two-stream generative model with newly proposed feature transformations in a coarse-to-fine fashion. This allows multi-scale semantic structure information and style representation to be effectively captured and fused by the network, permitting our method to scale to various tasks in both unsupervised and supervised settings. No additional constraints (e.g., cycle consistency) are needed, contributing to a very clean and simple method. Multi-modal image synthesis with arbitrary style control is made possible. A systematic study compares the proposed method with several state-of-the-art task-specific baselines, verifying its effectiveness in both perceptual quality and quantitative evaluations.
Towards Instance-level Image-to-Image Translation
May 05, 2019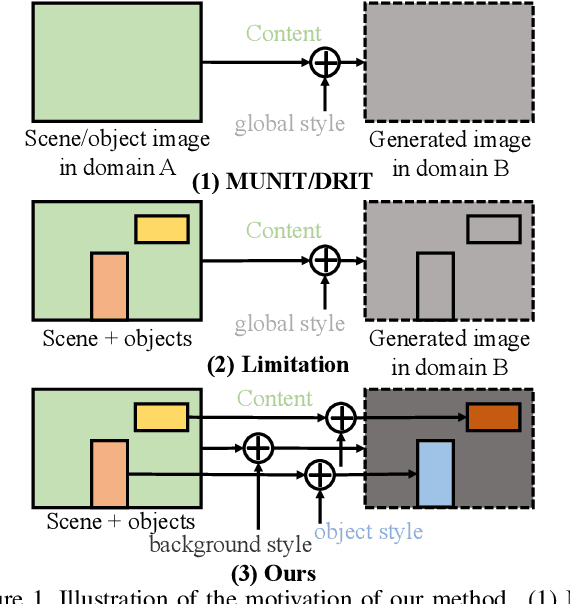
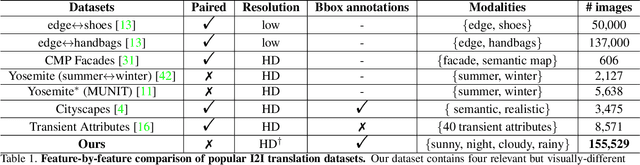
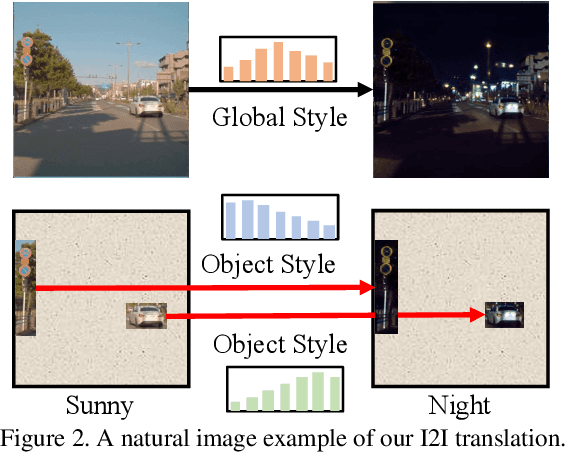

Unpaired Image-to-image Translation is a new rising and challenging vision problem that aims to learn a mapping between unaligned image pairs in diverse domains. Recent advances in this field like MUNIT and DRIT mainly focus on disentangling content and style/attribute from a given image first, then directly adopting the global style to guide the model to synthesize new domain images. However, this kind of approaches severely incurs contradiction if the target domain images are content-rich with multiple discrepant objects. In this paper, we present a simple yet effective instance-aware image-to-image translation approach (INIT), which employs the fine-grained local (instance) and global styles to the target image spatially. The proposed INIT exhibits three import advantages: (1) the instance-level objective loss can help learn a more accurate reconstruction and incorporate diverse attributes of objects; (2) the styles used for target domain of local/global areas are from corresponding spatial regions in source domain, which intuitively is a more reasonable mapping; (3) the joint training process can benefit both fine and coarse granularity and incorporates instance information to improve the quality of global translation. We also collect a large-scale benchmark for the new instance-level translation task. We observe that our synthetic images can even benefit real-world vision tasks like generic object detection.