 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-Brain-0: Spatial Intelligence as a Shared Scaffold for Universal Embodiments
Mar 03, 2026Universal embodied intelligence demands robust generalization across heterogeneous embodiments, such as autonomous driving, robotics, and unmanned aerial vehicles (UAVs). However, existing embodied brain in training a unified model over diverse embodiments frequently triggers long-tail data, gradient interference, and catastrophic forgetting, making it notoriously difficult to balance universal generalization with domain-specific proficiency. In this report, we introduce ACE-Brain-0, a generalist foundation brain that unifies spatial reasoning, autonomous driving, and embodied manipulation within a single multimodal large language model~(MLLM). Our key insight is that spatial intelligence serves as a universal scaffold across diverse physical embodiments: although vehicles, robots, and UAVs differ drastically in morphology, they share a common need for modeling 3D mental space, making spatial cognition a natural, domain-agnostic foundation for cross-embodiment transfer. Building on this insight, we propose the Scaffold-Specialize-Reconcile~(SSR) paradigm, which first establishes a shared spatial foundation, then cultivates domain-specialized experts, and finally harmonizes them through data-free model merging. Furthermore, we adopt Group Relative Policy Optimization~(GRPO) to strengthen the model's comprehensive capability. Extensive experiments demonstrate that ACE-Brain-0 achieves competitive and even state-of-the-art performance across 24 spatial and embodiment-related benchmarks.
Larger Hausdorff Dimension in Scanning Pattern Facilitates Mamba-Based Methods in Low-Light Image Enhancement
Oct 29, 2025We propose an innovative enhancement to the Mamba framework by increasing the Hausdorff dimension of its scanning pattern through a novel Hilbert Selective Scan mechanism. This mechanism explores the feature space more effectively, capturing intricate fine-scale details and improving overall coverage. As a result, it mitigates information inconsistencies while refining spatial locality to better capture subtle local interactions without sacrificing the model's ability to handle long-range dependencies. Extensive experiments on publicly available benchmarks demonstrate that our approach significantly improves both the quantitative metrics and qualitative visual fidelity of existing Mamba-based low-light image enhancement methods, all while reducing computational resource consumption and shortening inference time. We believe that this refined strategy not only advances the state-of-the-art in low-light image enhancement but also holds promise for broader applications in fields that leverage Mamba-based techniques.
UNIR-Net: A Novel Approach for Restoring Underwater Images with Non-Uniform Illumination Using Synthetic Data
Jan 15, 2025Enhancing underwater images with non-uniform illumination (NUI) is crucial for improving visibility and visual quality in marine environments, where image degradation is caused by significant absorption and scattering effects. However, traditional model-based methods are often ineffective at capturing the complex illumination variations present in such images, resulting in limited visual improvements. On the other hand, learning-based approaches have shown promising results but face challenges due to the lack of specific datasets designed to effectively address the non-uniform illumination problem. To overcome these challenges, the Underwater Non-uniform Illumination Restoration Network (UNIR-Net) is introduced, a novel method that integrates illumination enhancement and attention blocks, along with visual refinement and contrast correction modules. This approach is specifically designed to mitigate the scattering and absorption effects that cause light attenuation in underwater environments. Additionally, the Paired Underwater Non-uniform Illumination (PUNI) dataset is presented, a paired resource that facilitates the restoration of underwater images under non-uniform illumination conditions. Extensive experiments conducted on the PUNI dataset and the large-scale real-world Non-Uniform Illumination Dataset (NUID), which contains underwater images with non-uniform illumination, demonstrate the robust generalization ability of UNIR-Net. This method outperforms existing approaches in both quantitative metrics and qualitative evaluations. Furthermore, UNIR-Net not only significantly enhances the visual quality of images but also improves performance in advanced computer vision tasks, such as semantic segmentation in underwater environments, highlighting its broad applicability and potential impact. The code of this method is available at https://github.com/xingyumex/UNIR-Net
Just a Few Glances: Open-Set Visual Perception with Image Prompt Paradigm
Dec 14, 2024



To break through the limitations of pre-training models on fixed categories, Open-Set Object Detection (OSOD) and Open-Set Segmentation (OSS) have attracted a surge of interest from researchers. Inspired by large language models, mainstream OSOD and OSS methods generally utilize text as a prompt, achieving remarkable performance. Following SAM paradigm, some researchers use visual prompts, such as points, boxes, and masks that cover detection or segmentation targets. Despite these two prompt paradigms exhibit excellent performance, they also reveal inherent limitations. On the one hand, it is difficult to accurately describe characteristics of specialized category using textual description. On the other hand, existing visual prompt paradigms heavily rely on multi-round human interaction, which hinders them being applied to fully automated pipeline. To address the above issues, we propose a novel prompt paradigm in OSOD and OSS, that is, \textbf{Image Prompt Paradigm}. This brand new prompt paradigm enables to detect or segment specialized categories without multi-round human intervention. To achieve this goal, the proposed image prompt paradigm uses just a few image instances as prompts, and we propose a novel framework named \textbf{MI Grounding} for this new paradigm. In this framework, high-quality image prompts are automatically encoded, selected and fused, achieving the single-stage and non-interactive inference. We conduct extensive experiments on public datasets, showing that MI Grounding achieves competitive performance on OSOD and OSS benchmarks compared to text prompt paradigm methods and visual prompt paradigm methods. Moreover, MI Grounding can greatly outperform existing method on our constructed specialized ADR50K dataset.
BoT-Drive: Hierarchical Behavior and Trajectory Planning for Autonomous Driving using POMDPs
Sep 27, 2024

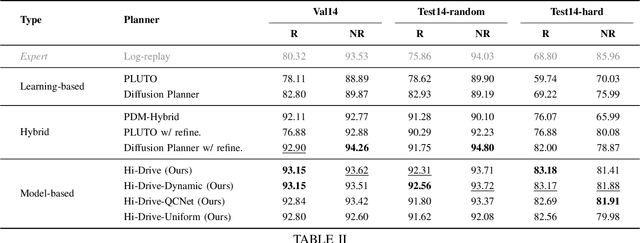
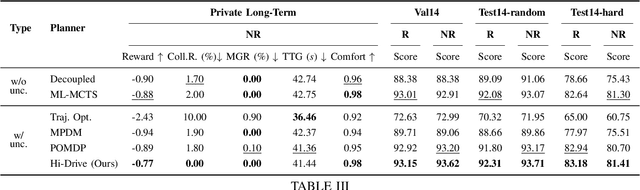
Uncertainties in dynamic road environments pose significant challenges for behavior and trajectory planning in autonomous driving. This paper introduces BoT-Drive, a planning algorithm that addresses uncertainties at both behavior and trajectory levels within a Partially Observable Markov Decision Process (POMDP) framework. BoT-Drive employs driver models to characterize unknown behavioral intentions and utilizes their model parameters to infer hidden driving styles. By also treating driver models as decision-making actions for the autonomous vehicle, BoT-Drive effectively tackles the exponential complexity inherent in POMDPs. To enhance safety and robustness, the planner further applies importance sampling to refine the driving trajectory conditioned on the planned high-level behavior. Evaluation on real-world data shows that BoT-Drive consistently outperforms both existing planning methods and learning-based methods in regular and complex urban driving scenes, demonstrating significant improvements in driving safety and reliability.
Safe Driving via Expert Guided Policy Optimization
Oct 30, 2021
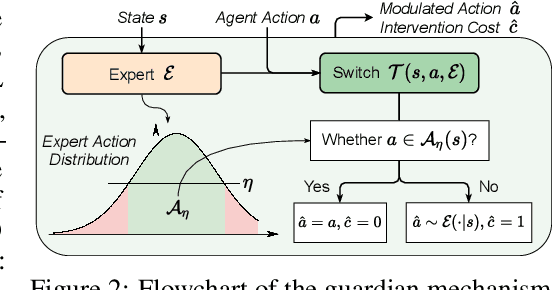
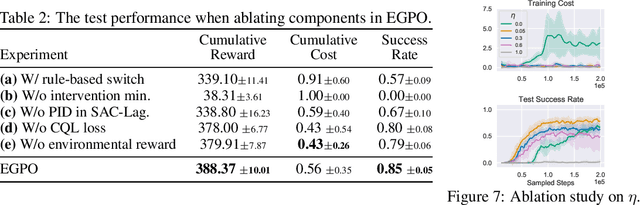

When learning common skills like driving, beginners usually have domain experts standing by to ensure the safety of the learning process. We formulate such learning scheme under the Expert-in-the-loop Reinforcement Learning where a guardian is introduced to safeguard the exploration of the learning agent. While allowing the sufficient exploration in the uncertain environment, the guardian intervenes under dangerous situations and demonstrates the correct actions to avoid potential accidents. Thus ERL enables both exploration and expert's partial demonstration as two training sources. Following such a setting, we develop a novel Expert Guided Policy Optimization (EGPO) method which integrates the guardian in the loop of reinforcement learning. The guardian is composed of an expert policy to generate demonstration and a switch function to decide when to intervene. Particularly, a constrained optimization technique is used to tackle the trivial solution that the agent deliberately behaves dangerously to deceive the expert into taking over. Offline RL technique is further used to learn from the partial demonstration generated by the expert. Safe driving experiments show that our method achieves superior training and test-time safety, outperforms baselines with a substantial margin in sample efficiency, and preserves the generalizabiliy to unseen environments in test-time. Demo video and source code are available at: https://decisionforce.github.io/EGPO/
Learning to Simulate Self-Driven Particles System with Coordinated Policy Optimization
Oct 26, 2021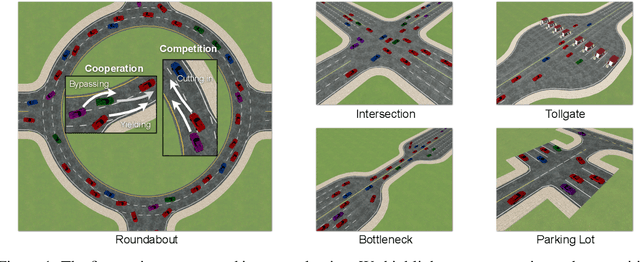
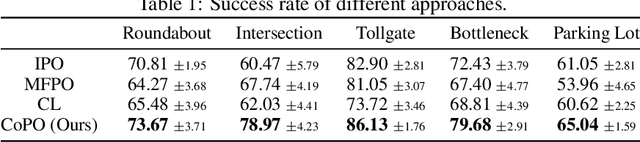
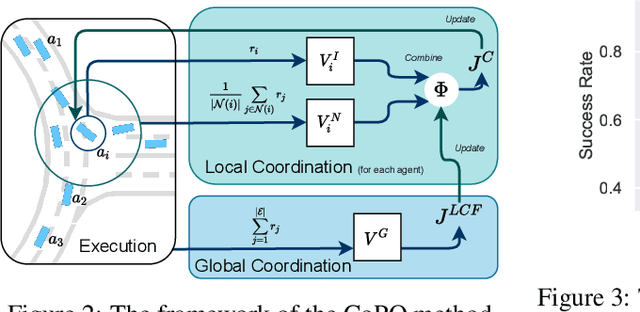

Self-Driven Particles (SDP) describe a category of multi-agent systems common in everyday life, such as flocking birds and traffic flows. In a SDP system, each agent pursues its own goal and constantly changes its cooperative or competitive behaviors with its nearby agents. Manually designing the controllers for such SDP system is time-consuming, while the resulting emergent behaviors are often not realistic nor generalizable. Thus the realistic simulation of SDP systems remains challenging. Reinforcement learning provides an appealing alternative for automating the development of the controller for SDP. However, previous multi-agent reinforcement learning (MARL) methods define the agents to be teammates or enemies before hand, which fail to capture the essence of SDP where the role of each agent varies to be cooperative or competitive even within one episode. To simulate SDP with MARL, a key challenge is to coordinate agents' behaviors while still maximizing individual objectives. Taking traffic simulation as the testing bed, in this work we develop a novel MARL method called Coordinated Policy Optimization (CoPO), which incorporates social psychology principle to learn neural controller for SDP. Experiments show that the proposed method can achieve superior performance compared to MARL baselines in various metrics. Noticeably the trained vehicles exhibit complex and diverse social behaviors that improve performance and safety of the population as a whole. Demo video and source code are available at: https://decisionforce.github.io/CoPO/
Autonomous Underwater Vehicle-Manipulator Systems Path Planning with RRTAUVMS Algorithm
Sep 11, 2021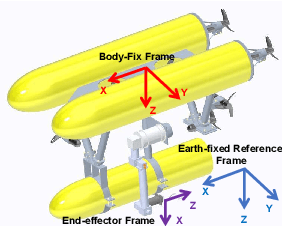

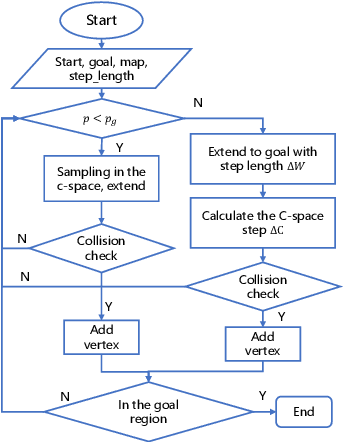

Autonomous Underwater Vehicle-Manipulator systems (AUVMS) is a new tool for ocean exploration, the AUVMS path planning problem is addressed in this paper. AUVMS is a high dimension system with a large difference in inertia distribution, also it works in a complex environment with obstacles. By integrating the rapidly-exploring random tree(RRT) algorithm with the AUVMS kinematics model, the proposed RRTAUVMS algorithm could randomly sample in the configuration space(C-Space), and also grow the tree directly towards the workspace goal in the task space. The RRTAUVMS can also deal with the redundant mapping of workspace planning goal and configuration space goal. Compared with the traditional RRT algorithm, the efficiency of the AUVMS path planning can be significantly improved.
Network Pruning via Resource Reallocation
Mar 02, 2021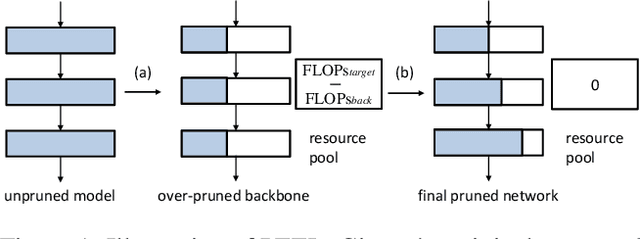
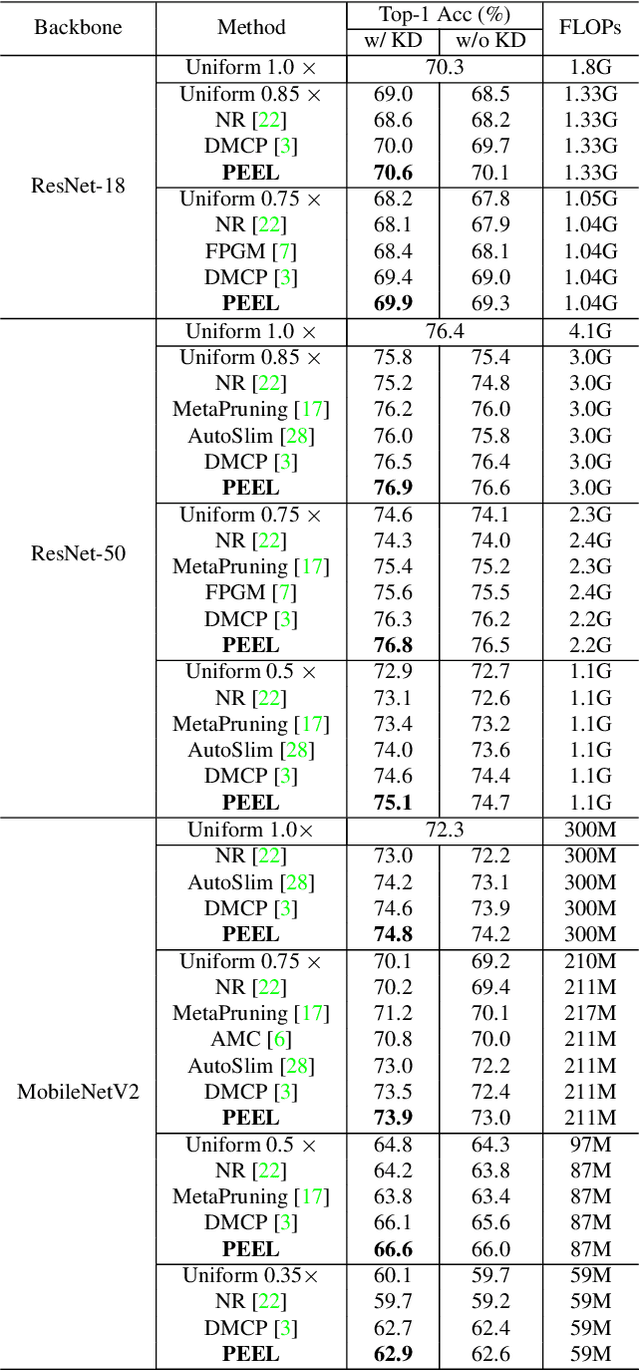
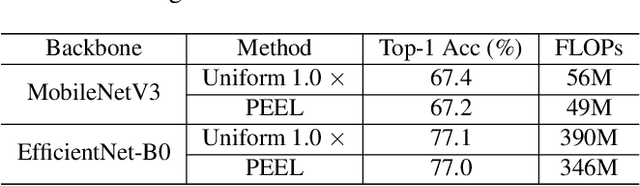
Channel pruning is broadly recognized as an effective approach to obtain a small compact model through eliminating unimportant channels from a large cumbersome network. Contemporary methods typically perform iterative pruning procedure from the original over-parameterized model, which is both tedious and expensive especially when the pruning is aggressive. In this paper, we propose a simple yet effective channel pruning technique, termed network Pruning via rEsource rEalLocation (PEEL), to quickly produce a desired slim model with negligible cost. Specifically, PEEL first constructs a predefined backbone and then conducts resource reallocation on it to shift parameters from less informative layers to more important layers in one round, thus amplifying the positive effect of these informative layers. To demonstrate the effectiveness of PEEL , we perform extensive experiments on ImageNet with ResNet-18, ResNet-50, MobileNetV2, MobileNetV3-small and EfficientNet-B0. Experimental results show that structures uncovered by PEEL exhibit competitive performance with state-of-the-art pruning algorithms under various pruning settings. Our code is available at https://github.com/cardwing/Codes-for-PEEL.
Improving the Generalization of End-to-End Driving through Procedural Generation
Dec 26, 2020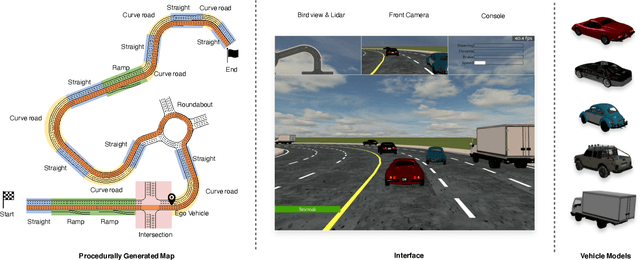

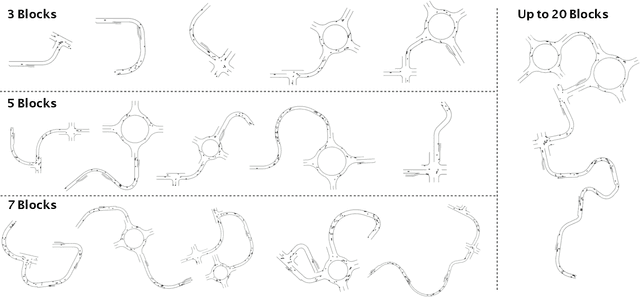
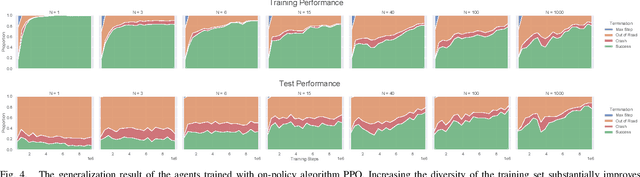
Recently there is a growing interest in the end-to-end training of autonomous driving where the entire driving pipeline from perception to control is modeled as a neural network and jointly optimized. The end-to-end driving is usually first developed and validated in simulators. However, most of the existing driving simulators only contain a fixed set of maps and a limited number of configurations. As a result the deep models are prone to overfitting training scenarios. Furthermore it is difficult to assess how well the trained models generalize to unseen scenarios. To better evaluate and improve the generalization of end-to-end driving, we introduce an open-ended and highly configurable driving simulator called PGDrive. PGDrive first defines multiple basic road blocks such as ramp, fork, and roundabout with configurable settings. Then a range of diverse maps can be assembled from those blocks with procedural generation, which are further turned into interactive environments. The experiments show that the driving agent trained by reinforcement learning on a small fixed set of maps generalizes poorly to unseen maps. We further validate that training with the increasing number of procedurally generated maps significantly improves the generalization of the agent across scenarios of different traffic densities and map structures. Code is available at: https://decisionforce.github.io/pgdrive