 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytic Subspace Routing: How Recursive Least Squares Works in Continual Learning of Large Language Model
Mar 17, 2025



Large Language Models (LLMs) possess encompassing capabilities that can process diverse language-related tasks. However, finetuning on LLMs will diminish this general skills and continual finetuning will further cause severe degradation on accumulated knowledge. Recently, Continual Learning (CL) in Large Language Models (LLMs) arises which aims to continually adapt the LLMs to new tasks while maintaining previously learned knowledge and inheriting general skills. Existing techniques either leverage previous data to replay, leading to extra computational costs, or utilize a single parameter-efficient module to learn the downstream task, constraining new knowledge absorption with interference between different tasks. Toward these issues, this paper proposes Analytic Subspace Routing(ASR) to address these challenges. For each task, we isolate the learning within a subspace of deep layers' features via low-rank adaptation, eliminating knowledge interference between different tasks. Additionally, we propose an analytic routing mechanism to properly utilize knowledge learned in different subspaces. Our approach employs Recursive Least Squares to train a multi-task router model, allowing the router to dynamically adapt to incoming data without requiring access to historical data. Also, the router effectively assigns the current task to an appropriate subspace and has a non-forgetting property of previously learned tasks with a solid theoretical guarantee. Experimental results demonstrate that our method achieves near-perfect retention of prior knowledge while seamlessly integrating new information, effectively overcoming the core limitations of existing methods. Our code will be released after acceptance.
Just a Few Glances: Open-Set Visual Perception with Image Prompt Paradigm
Dec 14, 2024



To break through the limitations of pre-training models on fixed categories, Open-Set Object Detection (OSOD) and Open-Set Segmentation (OSS) have attracted a surge of interest from researchers. Inspired by large language models, mainstream OSOD and OSS methods generally utilize text as a prompt, achieving remarkable performance. Following SAM paradigm, some researchers use visual prompts, such as points, boxes, and masks that cover detection or segmentation targets. Despite these two prompt paradigms exhibit excellent performance, they also reveal inherent limitations. On the one hand, it is difficult to accurately describe characteristics of specialized category using textual description. On the other hand, existing visual prompt paradigms heavily rely on multi-round human interaction, which hinders them being applied to fully automated pipeline. To address the above issues, we propose a novel prompt paradigm in OSOD and OSS, that is, \textbf{Image Prompt Paradigm}. This brand new prompt paradigm enables to detect or segment specialized categories without multi-round human intervention. To achieve this goal, the proposed image prompt paradigm uses just a few image instances as prompts, and we propose a novel framework named \textbf{MI Grounding} for this new paradigm. In this framework, high-quality image prompts are automatically encoded, selected and fused, achieving the single-stage and non-interactive inference. We conduct extensive experiments on public datasets, showing that MI Grounding achieves competitive performance on OSOD and OSS benchmarks compared to text prompt paradigm methods and visual prompt paradigm methods. Moreover, MI Grounding can greatly outperform existing method on our constructed specialized ADR50K dataset.
Reinforced Structured State-Evolution for Vision-Language Navigation
Apr 20, 2022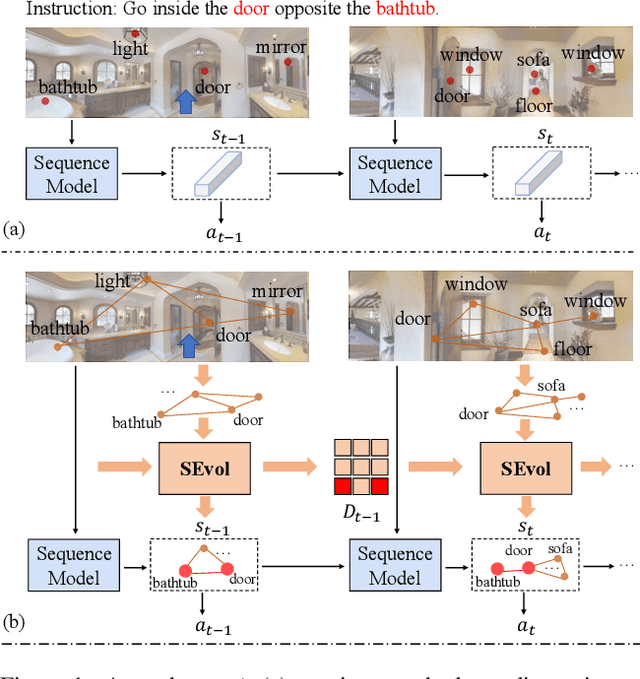
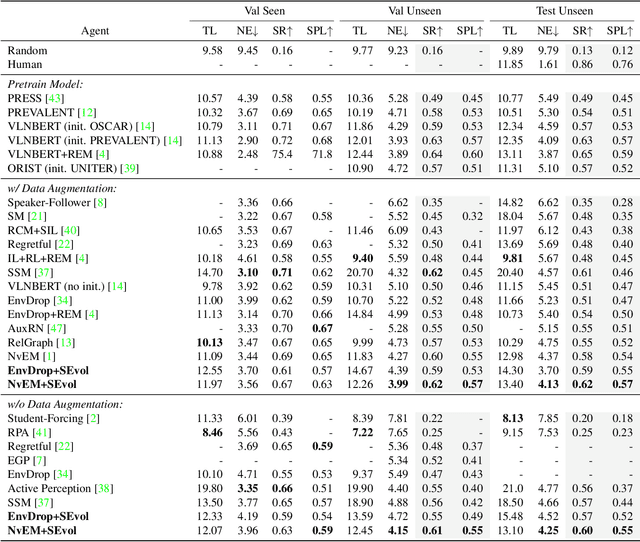
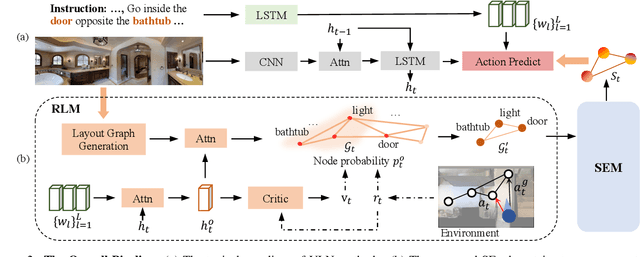
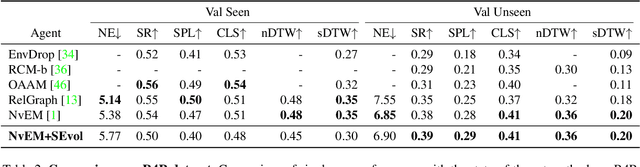
Vision-and-language Navigation (VLN) task requires an embodied agent to navigate to a remote location following a natural language instruction. Previous methods usually adopt a sequence model (e.g., Transformer and LSTM) as the navigator. In such a paradigm, the sequence model predicts action at each step through a maintained navigation state, which is generally represented as a one-dimensional vector. However, the crucial navigation clues (i.e., object-level environment layout) for embodied navigation task is discarded since the maintained vector is essentially unstructured. In this paper, we propose a novel Structured state-Evolution (SEvol) model to effectively maintain the environment layout clues for VLN. Specifically, we utilise the graph-based feature to represent the navigation state instead of the vector-based state. Accordingly, we devise a Reinforced Layout clues Miner (RLM) to mine and detect the most crucial layout graph for long-term navigation via a customised reinforcement learning strategy. Moreover, the Structured Evolving Module (SEM) is proposed to maintain the structured graph-based state during navigation, where the state is gradually evolved to learn the object-level spatial-temporal relationship. The experiments on the R2R and R4R datasets show that the proposed SEvol model improves VLN models' performance by large margins, e.g., +3% absolute SPL accuracy for NvEM and +8% for EnvDrop on the R2R test set.
Pre-trained Model for Chinese Word Segmentation with Meta Learning
Oct 23, 2020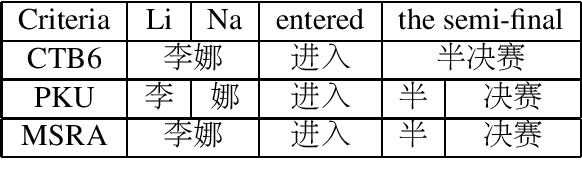
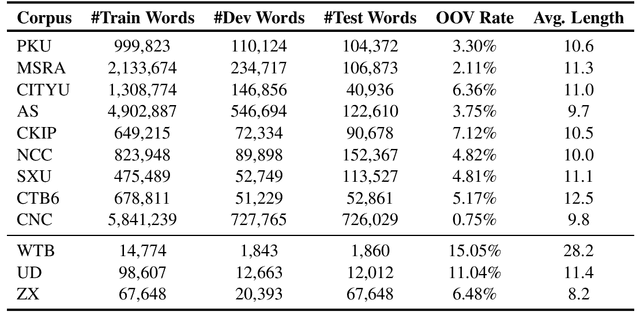
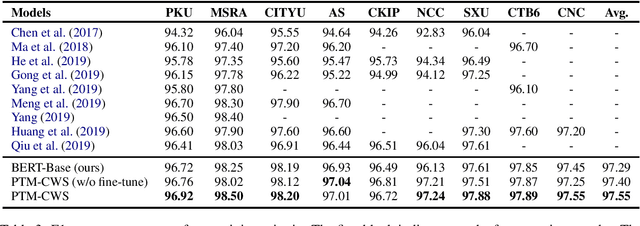
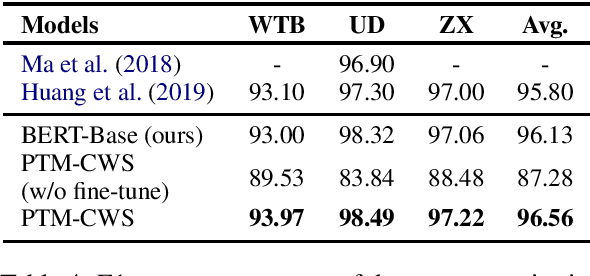
Recent researches show that pre-trained models such as BERT (Devlin et al., 2019) are beneficial for Chinese Word Segmentation tasks. However, existing approaches usually finetune pre-trained models directly on a separate downstream Chinese Word Segmentation corpus. These recent methods don't fully utilize the prior knowledge of existing segmentation corpora, and don't regard the discrepancy between the pre-training tasks and the downstream Chinese Word Segmentation tasks. In this work, we propose a Pre-Trained Model for Chinese Word Segmentation, which can be abbreviated as PTM-CWS. PTM-CWS model employs a unified architecture for different segmentation criteria, and is pre-trained on a joint multi-criteria corpus with meta learning algorithm. Empirical results show that our PTM-CWS model can utilize the existing prior segmentation knowledge, reduce the discrepancy between the pre-training tasks and the downstream Chinese Word Segmentation tasks, and achieve new state-of-the-art performance on twelve Chinese Word Segmentation corpora.
Unified Multi-Criteria Chinese Word Segmentation with BERT
Apr 13, 2020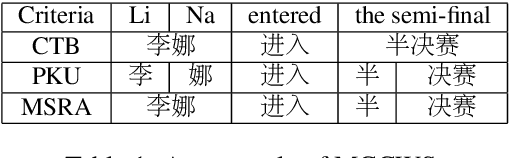
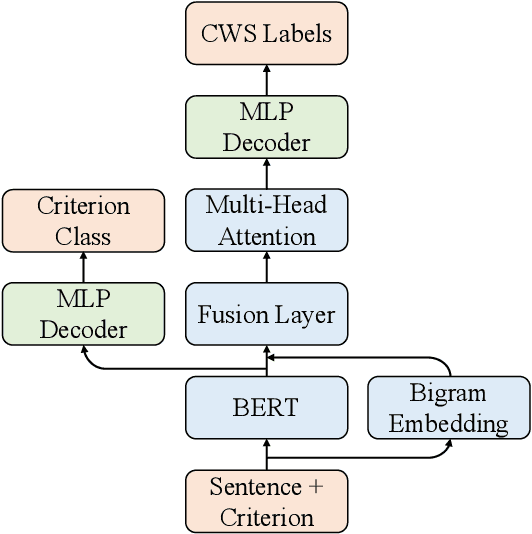
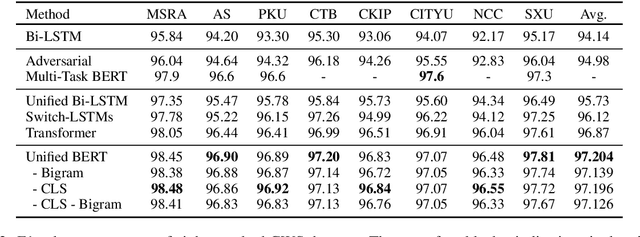
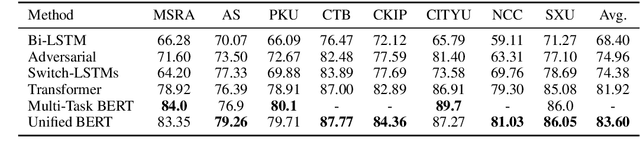
Multi-Criteria Chinese Word Segmentation (MCCWS) aims at finding word boundaries in a Chinese sentence composed of continuous characters while multiple segmentation criteria exist. The unified framework has been widely used in MCCWS and shows its effectiveness. Besides, the pre-trained BERT language model has been also introduced into the MCCWS task in a multi-task learning framework. In this paper, we combine the superiority of the unified framework and pretrained language model, and propose a unified MCCWS model based on BERT. Moreover, we augment the unified BERT-based MCCWS model with the bigram features and an auxiliary criterion classification task. Experiments on eight datasets with diverse criteria demonstrate that our methods could achieve new state-of-the-art results for MCCWS.