 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Gait-based Emotion Representation Learning from Selective Strongly Augmented Skeleton Sequences
May 08, 2024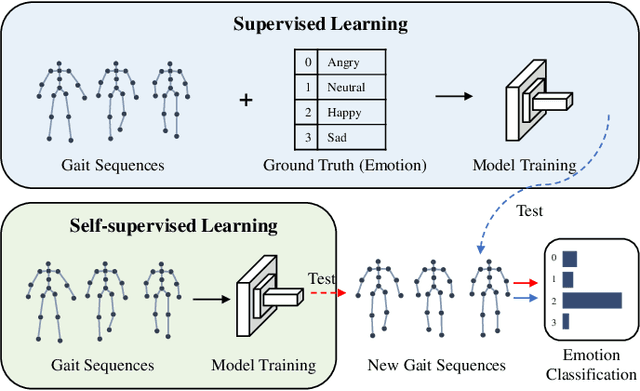
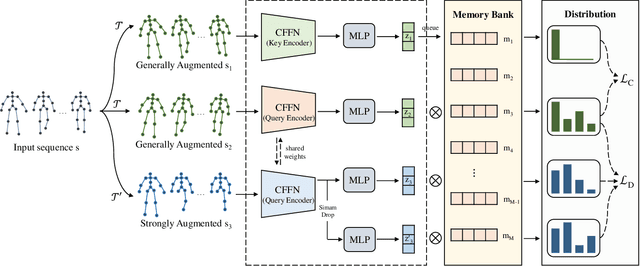
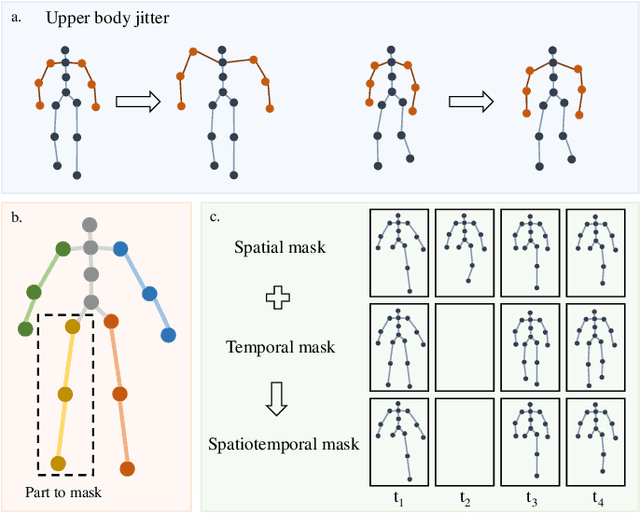
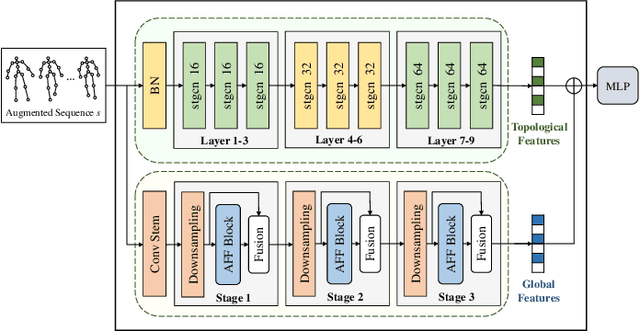
Emotion recognition is an important part of affective computing. Extracting emotional cues from human gaits yields benefits such as natural interaction, a nonintrusive nature, and remote detection. Recently, the introduction of self-supervised learning techniques offers a practical solution to the issues arising from the scarcity of labeled data in the field of gait-based emotion recognition. However, due to the limited diversity of gaits and the incompleteness of feature representations for skeletons, the existing contrastive learning methods are usually inefficient for the acquisition of gait emotions. In this paper, we propose a contrastive learning framework utilizing selective strong augmentation (SSA) for self-supervised gait-based emotion representation, which aims to derive effective representations from limited labeled gait data. First, we propose an SSA method for the gait emotion recognition task, which includes upper body jitter and random spatiotemporal mask. The goal of SSA is to generate more diverse and targeted positive samples and prompt the model to learn more distinctive and robust feature representations. Then, we design a complementary feature fusion network (CFFN) that facilitates the integration of cross-domain information to acquire topological structural and global adaptive features. Finally, we implement the distributional divergence minimization loss to supervise the representation learning of the generally and strongly augmented queries. Our approach is validated on the Emotion-Gait (E-Gait) and Emilya datasets and outperforms the state-of-the-art methods under different evaluation protocols.
Pre-trained Model for Chinese Word Segmentation with Meta Learning
Oct 23, 2020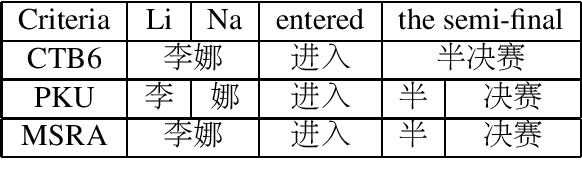
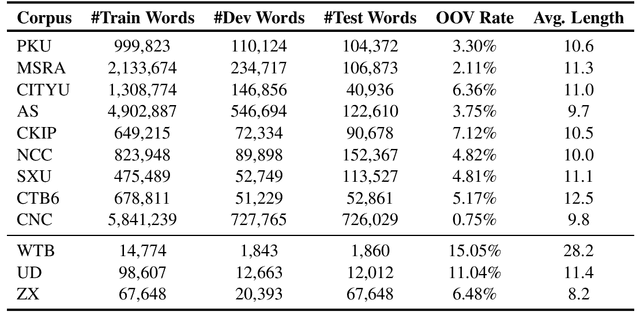
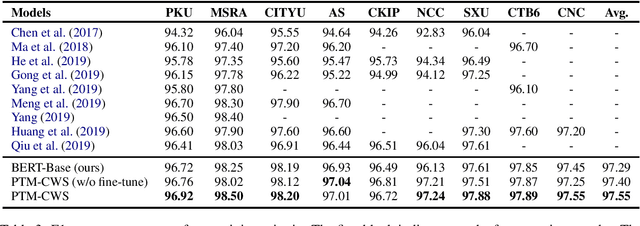
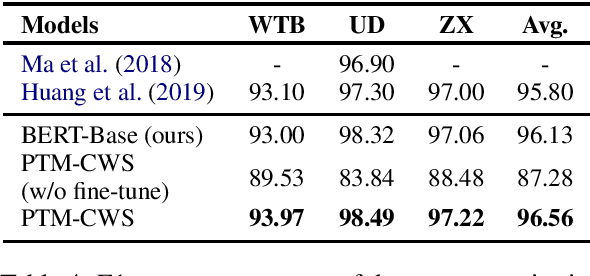
Recent researches show that pre-trained models such as BERT (Devlin et al., 2019) are beneficial for Chinese Word Segmentation tasks. However, existing approaches usually finetune pre-trained models directly on a separate downstream Chinese Word Segmentation corpus. These recent methods don't fully utilize the prior knowledge of existing segmentation corpora, and don't regard the discrepancy between the pre-training tasks and the downstream Chinese Word Segmentation tasks. In this work, we propose a Pre-Trained Model for Chinese Word Segmentation, which can be abbreviated as PTM-CWS. PTM-CWS model employs a unified architecture for different segmentation criteria, and is pre-trained on a joint multi-criteria corpus with meta learning algorithm. Empirical results show that our PTM-CWS model can utilize the existing prior segmentation knowledge, reduce the discrepancy between the pre-training tasks and the downstream Chinese Word Segmentation tasks, and achieve new state-of-the-art performance on twelve Chinese Word Segmentation corpora.
Unified Multi-Criteria Chinese Word Segmentation with BERT
Apr 13, 2020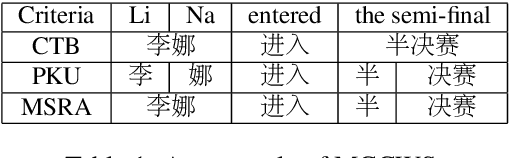
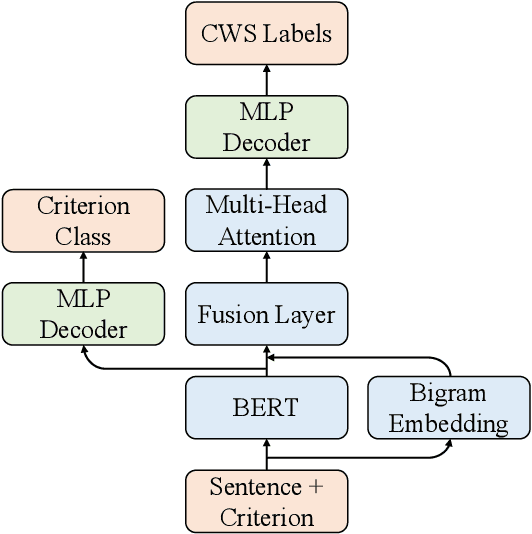
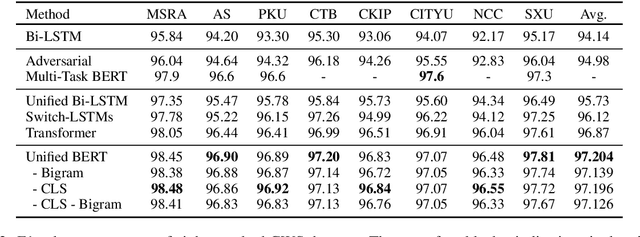
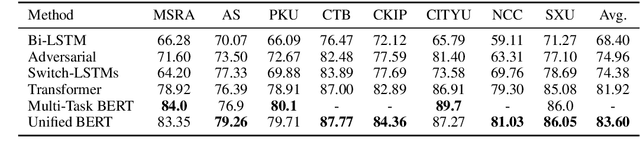
Multi-Criteria Chinese Word Segmentation (MCCWS) aims at finding word boundaries in a Chinese sentence composed of continuous characters while multiple segmentation criteria exist. The unified framework has been widely used in MCCWS and shows its effectiveness. Besides, the pre-trained BERT language model has been also introduced into the MCCWS task in a multi-task learning framework. In this paper, we combine the superiority of the unified framework and pretrained language model, and propose a unified MCCWS model based on BERT. Moreover, we augment the unified BERT-based MCCWS model with the bigram features and an auxiliary criterion classification task. Experiments on eight datasets with diverse criteria demonstrate that our methods could achieve new state-of-the-art results for MCCWS.