 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Mamba for Hyperspectral Object Tracking
Sep 10, 2025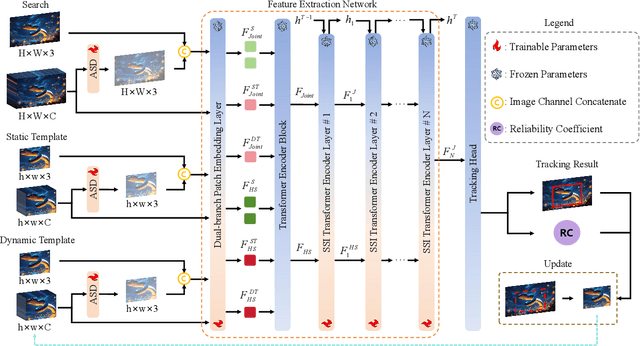
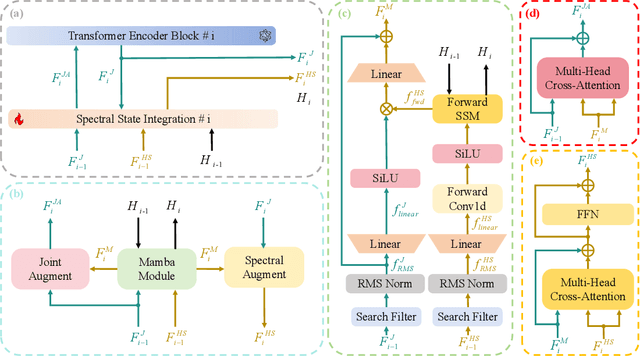
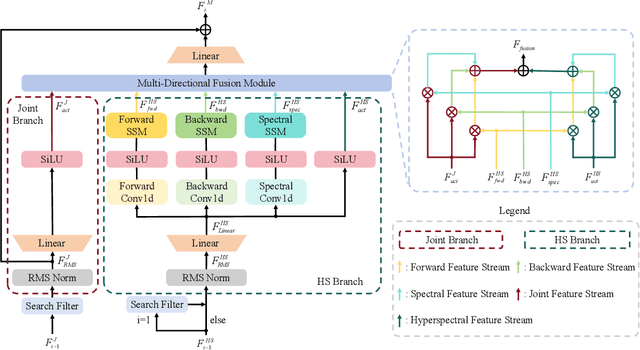
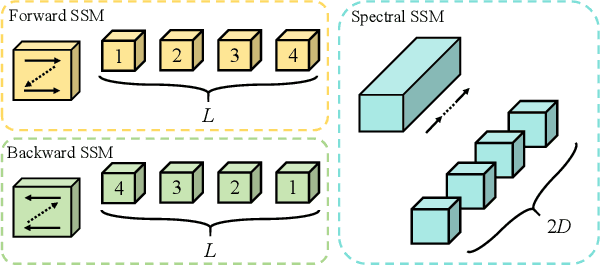
Hyperspectral object tracking holds great promise due to the rich spectral information and fine-grained material distinctions in hyperspectral images, which are beneficial in challenging scenarios. While existing hyperspectral trackers have made progress by either transforming hyperspectral data into false-color images or incorporating modality fusion strategies, they often fail to capture the intrinsic spectral information, temporal dependencies, and cross-depth interactions. To address these limitations, a new hyperspectral object tracking network equipped with Mamba (HyMamba), is proposed. It unifies spectral, cross-depth, and temporal modeling through state space modules (SSMs). The core of HyMamba lies in the Spectral State Integration (SSI) module, which enables progressive refinement and propagation of spectral features with cross-depth and temporal spectral information. Embedded within each SSI, the Hyperspectral Mamba (HSM) module is introduced to learn spatial and spectral information synchronously via three directional scanning SSMs. Based on SSI and HSM, HyMamba constructs joint features from false-color and hyperspectral inputs, and enhances them through interaction with original spectral features extracted from raw hyperspectral images. Extensive experiments conducted on seven benchmark datasets demonstrate that HyMamba achieves state-of-the-art performance. For instance, it achieves 73.0\% of the AUC score and 96.3\% of the DP@20 score on the HOTC2020 dataset. The code will be released at https://github.com/lgao001/HyMamba.
Hyperspectral Adapter for Object Tracking based on Hyperspectral Video
Mar 28, 2025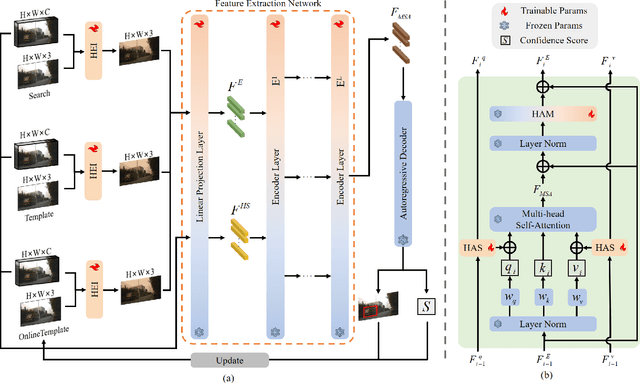
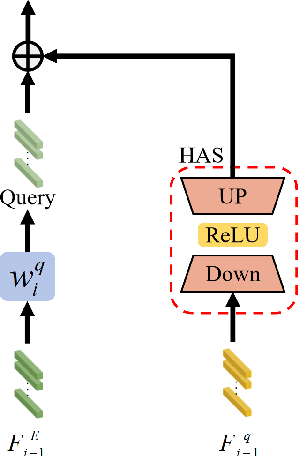
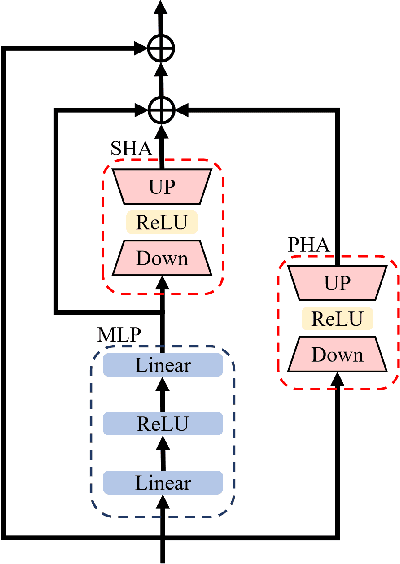
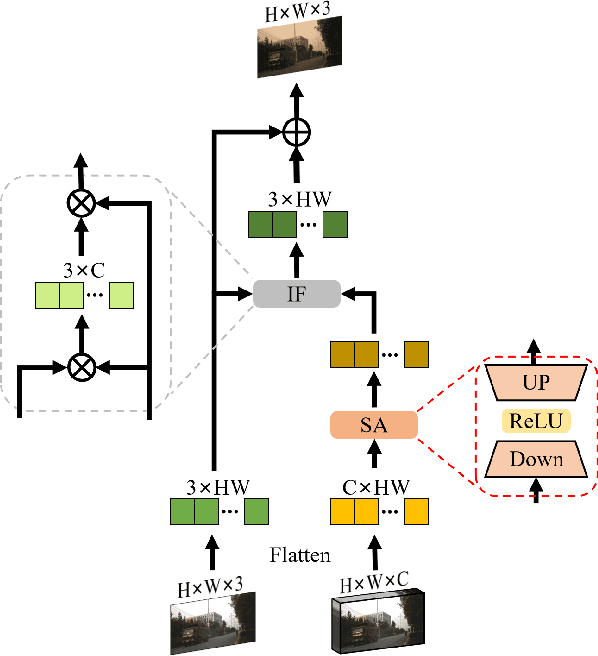
Object tracking based on hyperspectral video attracts increasing attention to the rich material and motion information in the hyperspectral videos. The prevailing hyperspectral methods adapt pretrained RGB-based object tracking networks for hyperspectral tasks by fine-tuning the entire network on hyperspectral datasets, which achieves impressive results in challenging scenarios. However, the performance of hyperspectral trackers is limited by the loss of spectral information during the transformation, and fine-tuning the entire pretrained network is inefficient for practical applications. To address the issues, a new hyperspectral object tracking method, hyperspectral adapter for tracking (HyA-T), is proposed in this work. The hyperspectral adapter for the self-attention (HAS) and the hyperspectral adapter for the multilayer perceptron (HAM) are proposed to generate the adaption information and to transfer the multi-head self-attention (MSA) module and the multilayer perceptron (MLP) in pretrained network for the hyperspectral object tracking task by augmenting the adaption information into the calculation of the MSA and MLP. Additionally, the hyperspectral enhancement of input (HEI) is proposed to augment the original spectral information into the input of the tracking network. The proposed methods extract spectral information directly from the hyperspectral images, which prevent the loss of the spectral information. Moreover, only the parameters in the proposed methods are fine-tuned, which is more efficient than the existing methods. Extensive experiments were conducted on four datasets with various spectral bands, verifing the effectiveness of the proposed methods. The HyA-T achieves state-of-the-art performance on all the datasets.
JL1-CD: A New Benchmark for Remote Sensing Change Detection and a Robust Multi-Teacher Knowledge Distillation Framework
Feb 19, 2025

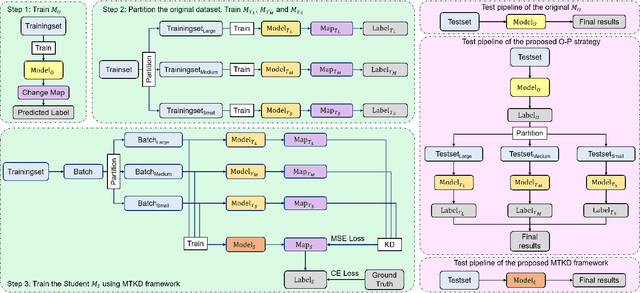

Deep learning has achieved significant success in the field of remote sensing image change detection (CD), yet two major challenges remain: the scarcity of sub-meter, all-inclusive open-source CD datasets, and the difficulty of achieving consistent and satisfactory detection results across images with varying change areas. To address these issues, we introduce the JL1-CD dataset, which contains 5,000 pairs of 512 x 512 pixel images with a resolution of 0.5 to 0.75 meters. Additionally, we propose a multi-teacher knowledge distillation (MTKD) framework for CD. Experimental results on the JL1-CD and SYSU-CD datasets demonstrate that the MTKD framework significantly improves the performance of CD models with various network architectures and parameter sizes, achieving new state-of-the-art results. The code is available at https://github.com/circleLZY/MTKD-CD.
Self-supervised Gait-based Emotion Representation Learning from Selective Strongly Augmented Skeleton Sequences
May 08, 2024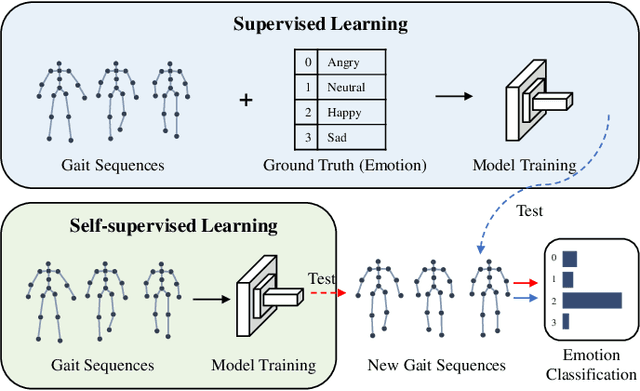
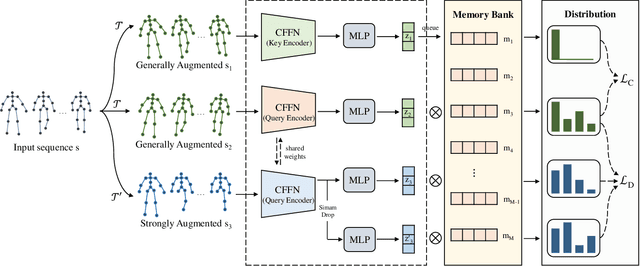
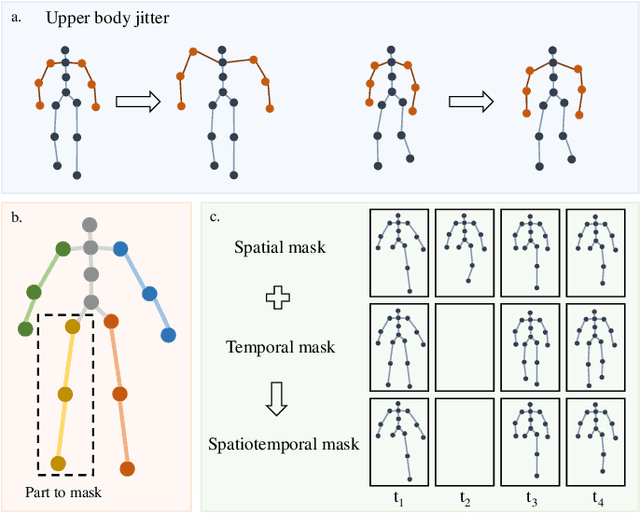
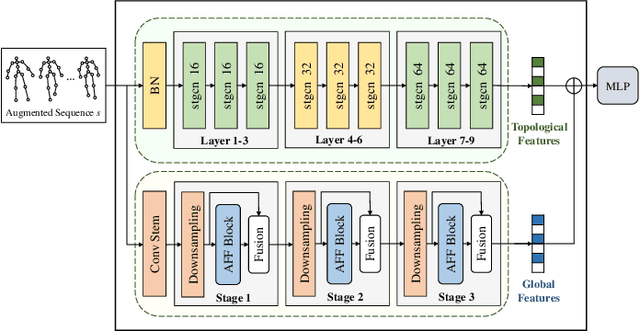
Emotion recognition is an important part of affective computing. Extracting emotional cues from human gaits yields benefits such as natural interaction, a nonintrusive nature, and remote detection. Recently, the introduction of self-supervised learning techniques offers a practical solution to the issues arising from the scarcity of labeled data in the field of gait-based emotion recognition. However, due to the limited diversity of gaits and the incompleteness of feature representations for skeletons, the existing contrastive learning methods are usually inefficient for the acquisition of gait emotions. In this paper, we propose a contrastive learning framework utilizing selective strong augmentation (SSA) for self-supervised gait-based emotion representation, which aims to derive effective representations from limited labeled gait data. First, we propose an SSA method for the gait emotion recognition task, which includes upper body jitter and random spatiotemporal mask. The goal of SSA is to generate more diverse and targeted positive samples and prompt the model to learn more distinctive and robust feature representations. Then, we design a complementary feature fusion network (CFFN) that facilitates the integration of cross-domain information to acquire topological structural and global adaptive features. Finally, we implement the distributional divergence minimization loss to supervise the representation learning of the generally and strongly augmented queries. Our approach is validated on the Emotion-Gait (E-Gait) and Emilya datasets and outperforms the state-of-the-art methods under different evaluation protocols.
Medical Knowledge-Guided Deep Learning for Imbalanced Medical Image Classification
Nov 20, 2021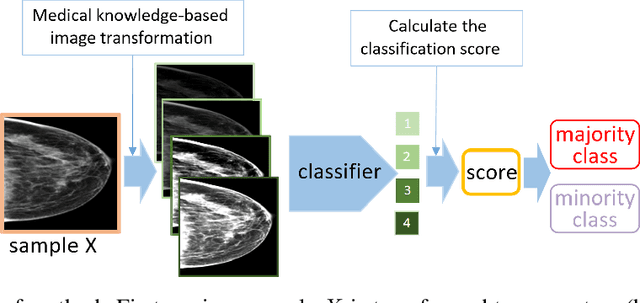
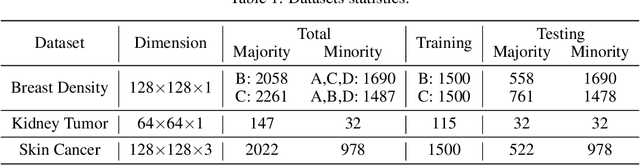
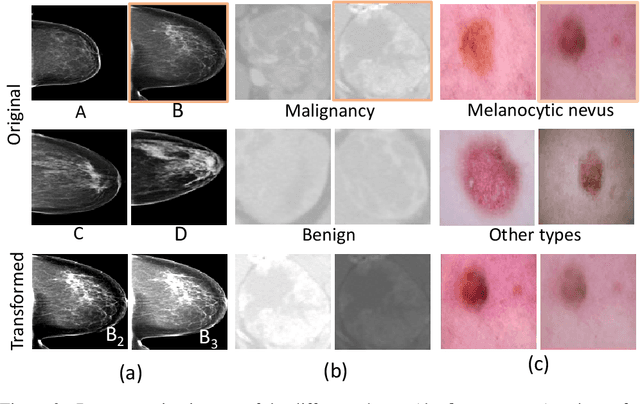

Deep learning models have gained remarkable performance on a variety of image classification tasks. However, many models suffer from limited performance in clinical or medical settings when data are imbalanced. To address this challenge, we propose a medical-knowledge-guided one-class classification approach that leverages domain-specific knowledge of classification tasks to boost the model's performance. The rationale behind our approach is that some existing prior medical knowledge can be incorporated into data-driven deep learning to facilitate model learning. We design a deep learning-based one-class classification pipeline for imbalanced image classification, and demonstrate in three use cases how we take advantage of medical knowledge of each specific classification task by generating additional middle classes to achieve higher classification performances. We evaluate our approach on three different clinical image classification tasks (a total of 8459 images) and show superior model performance when compared to six state-of-the-art methods. All codes of this work will be publicly available upon acceptance of the paper.
Constrained Deep One-Class Feature Learning For Classifying Imbalanced Medical Images
Nov 20, 2021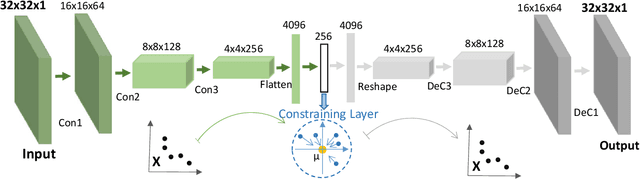

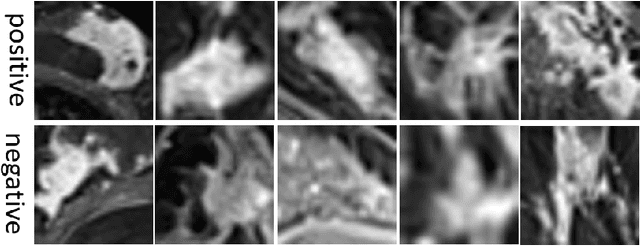
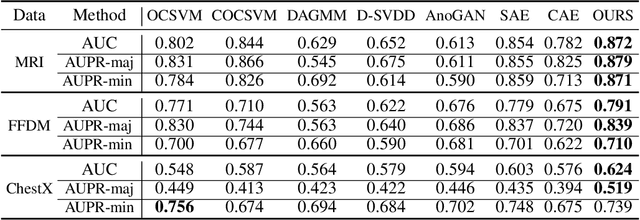
Medical image data are usually imbalanced across different classes. One-class classification has attracted increasing attention to address the data imbalance problem by distinguishing the samples of the minority class from the majority class. Previous methods generally aim to either learn a new feature space to map training samples together or to fit training samples by autoencoder-like models. These methods mainly focus on capturing either compact or descriptive features, where the information of the samples of a given one class is not sufficiently utilized. In this paper, we propose a novel deep learning-based method to learn compact features by adding constraints on the bottleneck features, and to preserve descriptive features by training an autoencoder at the same time. Through jointly optimizing the constraining loss and the autoencoder's reconstruction loss, our method can learn more relevant features associated with the given class, making the majority and minority samples more distinguishable. Experimental results on three clinical datasets (including the MRI breast images, FFDM breast images and chest X-ray images) obtains state-of-art performance compared to previous methods.