 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnostic Performance of Universal-Learning Ultrasound AI Across Multiple Organs and Tasks: the UUSIC25 Challenge
Dec 19, 2025IMPORTANCE: Current ultrasound AI remains fragmented into single-task tools, limiting clinical utility compared to versatile modern ultrasound systems. OBJECTIVE: To evaluate the diagnostic accuracy and efficiency of single general-purpose deep learning models for multi-organ classification and segmentation. DESIGN: The Universal UltraSound Image Challenge 2025 (UUSIC25) involved developing algorithms on 11,644 images (public/private). Evaluation used an independent, multi-center test set of 2,479 images, including data from a center completely unseen during training to assess generalization. OUTCOMES: Diagnostic performance (Dice Similarity Coefficient [DSC]; Area Under the Receiver Operating Characteristic Curve [AUC]) and computational efficiency (inference time, GPU memory). RESULTS: Of 15 valid algorithms, the top model (SMART) achieved a macro-averaged DSC of 0.854 across 5 segmentation tasks and AUC of 0.766 for binary classification. Models showed high capability in segmentation (e.g., fetal head DSC: 0.942) but variability in complex tasks subject to domain shift. Notably, in breast cancer molecular subtyping, the top model's performance dropped from AUC 0.571 (internal) to 0.508 (unseen external center), highlighting generalization challenges. CONCLUSIONS: General-purpose AI models achieve high accuracy and efficiency across multiple tasks using a single architecture. However, performance degradation on unseen data suggests domain generalization is critical for future clinical deployment.
$Δ$t-Mamba3D: A Time-Aware Spatio-Temporal State-Space Model for Breast Cancer Risk Prediction
Oct 21, 2025


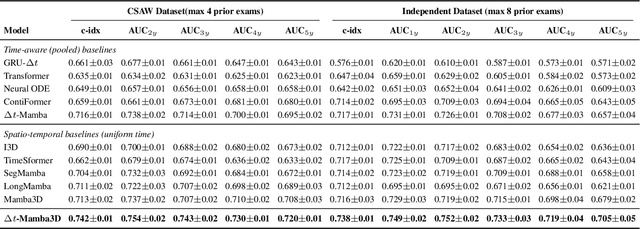
Longitudinal analysis of sequential radiological images is hampered by a fundamental data challenge: how to effectively model a sequence of high-resolution images captured at irregular time intervals. This data structure contains indispensable spatial and temporal cues that current methods fail to fully exploit. Models often compromise by either collapsing spatial information into vectors or applying spatio-temporal models that are computationally inefficient and incompatible with non-uniform time steps. We address this challenge with Time-Aware $\Delta$t-Mamba3D, a novel state-space architecture adapted for longitudinal medical imaging. Our model simultaneously encodes irregular inter-visit intervals and rich spatio-temporal context while remaining computationally efficient. Its core innovation is a continuous-time selective scanning mechanism that explicitly integrates the true time difference between exams into its state transitions. This is complemented by a multi-scale 3D neighborhood fusion module that robustly captures spatio-temporal relationships. In a comprehensive breast cancer risk prediction benchmark using sequential screening mammogram exams, our model shows superior performance, improving the validation c-index by 2-5 percentage points and achieving higher 1-5 year AUC scores compared to established variants of recurrent, transformer, and state-space models. Thanks to its linear complexity, the model can efficiently process long and complex patient screening histories of mammograms, forming a new framework for longitudinal image analysis.
STA-Risk: A Deep Dive of Spatio-Temporal Asymmetries for Breast Cancer Risk Prediction
May 27, 2025Predicting the risk of developing breast cancer is an important clinical tool to guide early intervention and tailoring personalized screening strategies. Early risk models have limited performance and recently machine learning-based analysis of mammogram images showed encouraging risk prediction effects. These models however are limited to the use of a single exam or tend to overlook nuanced breast tissue evolvement in spatial and temporal details of longitudinal imaging exams that are indicative of breast cancer risk. In this paper, we propose STA-Risk (Spatial and Temporal Asymmetry-based Risk Prediction), a novel Transformer-based model that captures fine-grained mammographic imaging evolution simultaneously from bilateral and longitudinal asymmetries for breast cancer risk prediction. STA-Risk is innovative by the side encoding and temporal encoding to learn spatial-temporal asymmetries, regulated by a customized asymmetry loss. We performed extensive experiments with two independent mammogram datasets and achieved superior performance than four representative SOTA models for 1- to 5-year future risk prediction. Source codes will be released upon publishing of the paper.
Longitudinal Mammogram Exam-based Breast Cancer Diagnosis Models: Vulnerability to Adversarial Attacks
Oct 29, 2024



In breast cancer detection and diagnosis, the longitudinal analysis of mammogram images is crucial. Contemporary models excel in detecting temporal imaging feature changes, thus enhancing the learning process over sequential imaging exams. Yet, the resilience of these longitudinal models against adversarial attacks remains underexplored. In this study, we proposed a novel attack method that capitalizes on the feature-level relationship between two sequential mammogram exams of a longitudinal model, guided by both cross-entropy loss and distance metric learning, to achieve significant attack efficacy, as implemented using attack transferring in a black-box attacking manner. We performed experiments on a cohort of 590 breast cancer patients (each has two sequential mammogram exams) in a case-control setting. Results showed that our proposed method surpassed several state-of-the-art adversarial attacks in fooling the diagnosis models to give opposite outputs. Our method remained effective even if the model was trained with the common defending method of adversarial training.
Mixture of Experts Made Personalized: Federated Prompt Learning for Vision-Language Models
Oct 14, 2024



Prompt learning for pre-trained Vision-Language Models (VLMs) like CLIP has demonstrated potent applicability across diverse downstream tasks. This lightweight approach has quickly gained traction from federated learning (FL) researchers who seek to efficiently adapt VLMs to heterogeneous scenarios. However, current federated prompt learning methods are habitually restricted to the traditional FL paradigm, where the participating clients are generally only allowed to download a single globally aggregated model from the server. While justifiable for training full-sized models under federated settings, in this work, we argue that this paradigm is ill-suited for lightweight prompts. By facilitating the clients to download multiple pre-aggregated prompts as fixed non-local experts, we propose Personalized Federated Mixture of Adaptive Prompts (pFedMoAP), a novel FL framework that personalizes the prompt learning process through the lens of Mixture of Experts (MoE). pFedMoAP implements a local attention-based gating network that learns to generate enhanced text features for better alignment with local image data on the client, benefiting from both local and downloaded non-local adaptive prompt experts. The non-local experts are sparsely selected from a server-maintained pool, fostering collaborative learning across clients. To evaluate the proposed algorithm, we conduct extensive experiments across 9 datasets under various heterogeneous federated settings. The results show that pFedMoAP consistently outperforms the state-of-the-art alternatives, underscoring its efficacy in personalizing prompt learning for CLIP within the federated learning paradigm.
Adversarially Robust Feature Learning for Breast Cancer Diagnosis
Feb 13, 2024Adversarial data can lead to malfunction of deep learning applications. It is essential to develop deep learning models that are robust to adversarial data while accurate on standard, clean data. In this study, we proposed a novel adversarially robust feature learning (ARFL) method for a real-world application of breast cancer diagnosis. ARFL facilitates adversarial training using both standard data and adversarial data, where a feature correlation measure is incorporated as an objective function to encourage learning of robust features and restrain spurious features. To show the effects of ARFL in breast cancer diagnosis, we built and evaluated diagnosis models using two independent clinically collected breast imaging datasets, comprising a total of 9,548 mammogram images. We performed extensive experiments showing that our method outperformed several state-of-the-art methods and that our method can enhance safer breast cancer diagnosis against adversarial attacks in clinical settings.
FedPerfix: Towards Partial Model Personalization of Vision Transformers in Federated Learning
Aug 17, 2023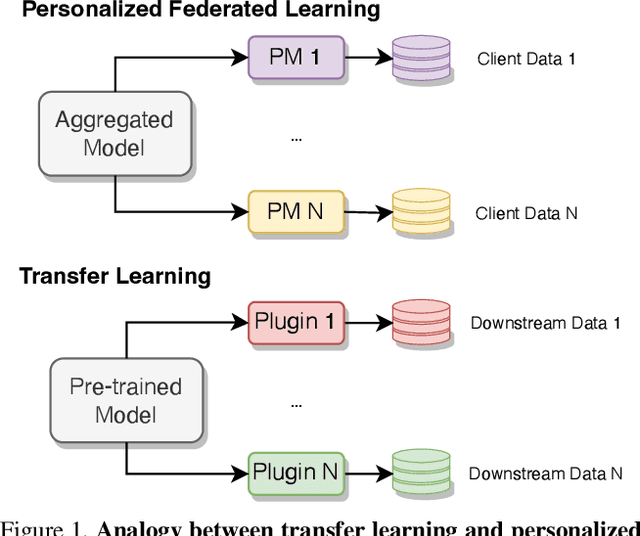

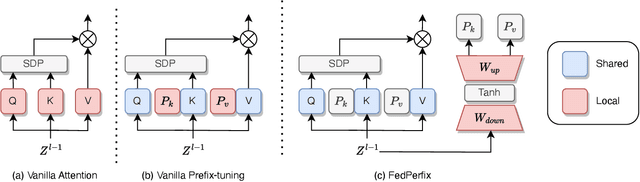
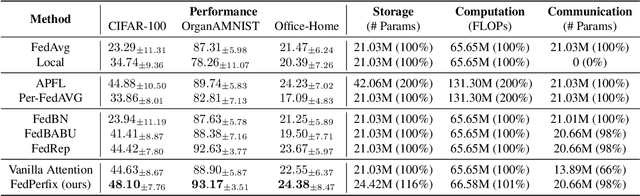
Personalized Federated Learning (PFL) represents a promising solution for decentralized learning in heterogeneous data environments. Partial model personalization has been proposed to improve the efficiency of PFL by selectively updating local model parameters instead of aggregating all of them. However, previous work on partial model personalization has mainly focused on Convolutional Neural Networks (CNNs), leaving a gap in understanding how it can be applied to other popular models such as Vision Transformers (ViTs). In this work, we investigate where and how to partially personalize a ViT model. Specifically, we empirically evaluate the sensitivity to data distribution of each type of layer. Based on the insights that the self-attention layer and the classification head are the most sensitive parts of a ViT, we propose a novel approach called FedPerfix, which leverages plugins to transfer information from the aggregated model to the local client as a personalization. Finally, we evaluate the proposed approach on CIFAR-100, OrganAMNIST, and Office-Home datasets and demonstrate its effectiveness in improving the model's performance compared to several advanced PFL methods.
Human not in the loop: objective sample difficulty measures for Curriculum Learning
Feb 02, 2023
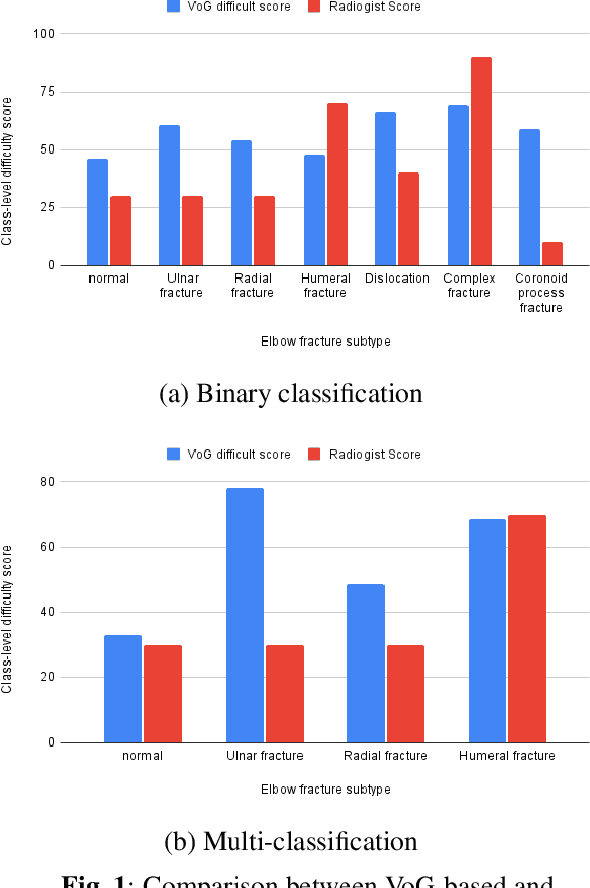


Curriculum learning is a learning method that trains models in a meaningful order from easier to harder samples. A key here is to devise automatic and objective difficulty measures of samples. In the medical domain, previous work applied domain knowledge from human experts to qualitatively assess classification difficulty of medical images to guide curriculum learning, which requires extra annotation efforts, relies on subjective human experience, and may introduce bias. In this work, we propose a new automated curriculum learning technique using the variance of gradients (VoG) to compute an objective difficulty measure of samples and evaluated its effects on elbow fracture classification from X-ray images. Specifically, we used VoG as a metric to rank each sample in terms of the classification difficulty, where high VoG scores indicate more difficult cases for classification, to guide the curriculum training process We compared the proposed technique to a baseline (without curriculum learning), a previous method that used human annotations on classification difficulty, and anti-curriculum learning. Our experiment results showed comparable and higher performance for the binary and multi-class bone fracture classification tasks.
PGFed: Personalize Each Client's Global Objective for Federated Learning
Dec 02, 2022The mediocre performance of conventional federated learning (FL) over heterogeneous data has been facilitating personalized FL solutions, where, unlike conventional FL which trains a single global consensus model, different models are allowed for different clients. However, in most existing personalized FL algorithms, the collaborative knowledge across the federation was only implicitly passed to the clients in ways such as model aggregation or regularization. We observed that this implicit knowledge transfer fails to maximize the potential value of each client's empirical risk toward other clients. Based on our observation, in this work, we propose Personalized Global Federated Learning (PGFed), a novel personalized FL framework that enables each client to personalize its own global objective by explicitly and adaptively aggregating the empirical risks of itself and other clients. To avoid massive ($O(N^2)$) communication overhead and potential privacy leakage, each client's risk is estimated through a first-order approximation for other clients' adaptive risk aggregation. On top of PGFed, we develop a momentum upgrade, dubbed PGFedMo, to more efficiently utilize clients' empirical risks. Our extensive experiments under different federated settings with benchmark datasets show consistent improvements of PGFed over the compared state-of-the-art alternatives.
Cross-Domain Self-Supervised Deep Learning for Robust Alzheimer's Disease Progression Modeling
Nov 15, 2022Developing successful artificial intelligence systems in practice depends both on robust deep learning models as well as large high quality data. Acquiring and labeling data can become prohibitively expensive and time-consuming in many real-world applications such as clinical disease models. Self-supervised learning has demonstrated great potential in increasing model accuracy and robustness in small data regimes. In addition, many clinical imaging and disease modeling applications rely heavily on regression of continuous quantities. However, the applicability of self-supervised learning for these medical-imaging regression tasks has not been extensively studied. In this study, we develop a cross-domain self-supervised learning approach for disease prognostic modeling as a regression problem using 3D images as input. We demonstrate that self-supervised pre-training can improve the prediction of Alzheimer's Disease progression from brain MRI. We also show that pre-training on extended (but not labeled) brain MRI data outperforms pre-training on natural images. We further observe that the highest performance is achieved when both natural images and extended brain-MRI data are used for pre-training.