 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Heterogeneity and Privacy in One-Shot Federated Learning with Diffusion Models
May 02, 2024



Federated learning (FL) enables multiple clients to train models collectively while preserving data privacy. However, FL faces challenges in terms of communication cost and data heterogeneity. One-shot federated learning has emerged as a solution by reducing communication rounds, improving efficiency, and providing better security against eavesdropping attacks. Nevertheless, data heterogeneity remains a significant challenge, impacting performance. This work explores the effectiveness of diffusion models in one-shot FL, demonstrating their applicability in addressing data heterogeneity and improving FL performance. Additionally, we investigate the utility of our diffusion model approach, FedDiff, compared to other one-shot FL methods under differential privacy (DP). Furthermore, to improve generated sample quality under DP settings, we propose a pragmatic Fourier Magnitude Filtering (FMF) method, enhancing the effectiveness of generated data for global model training.
Towards Multi-modal Transformers in Federated Learning
Apr 18, 2024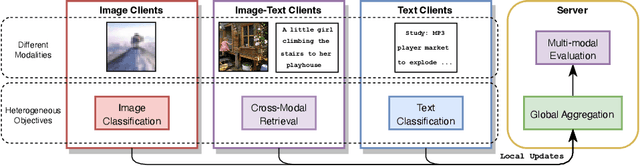
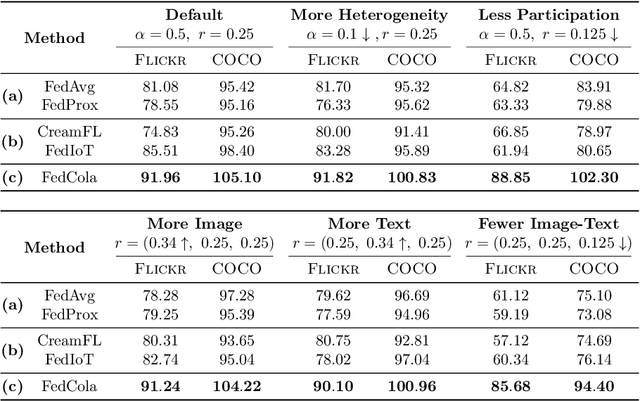
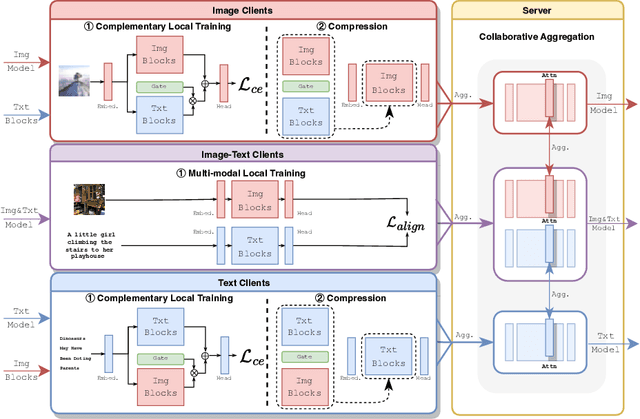
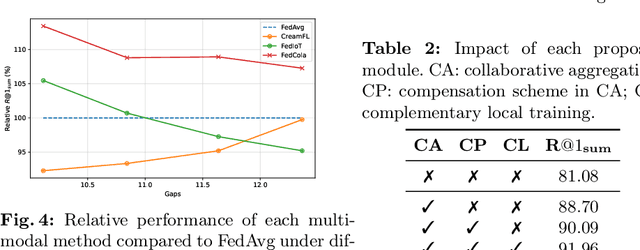
Multi-modal transformers mark significant progress in different domains, but siloed high-quality data hinders their further improvement. To remedy this, federated learning (FL) has emerged as a promising privacy-preserving paradigm for training models without direct access to the raw data held by different clients. Despite its potential, a considerable research direction regarding the unpaired uni-modal clients and the transformer architecture in FL remains unexplored. To fill this gap, this paper explores a transfer multi-modal federated learning (MFL) scenario within the vision-language domain, where clients possess data of various modalities distributed across different datasets. We systematically evaluate the performance of existing methods when a transformer architecture is utilized and introduce a novel framework called Federated modality complementary and collaboration (FedCola) by addressing the in-modality and cross-modality gaps among clients. Through extensive experiments across various FL settings, FedCola demonstrates superior performance over previous approaches, offering new perspectives on future federated training of multi-modal transformers.
FedPerfix: Towards Partial Model Personalization of Vision Transformers in Federated Learning
Aug 17, 2023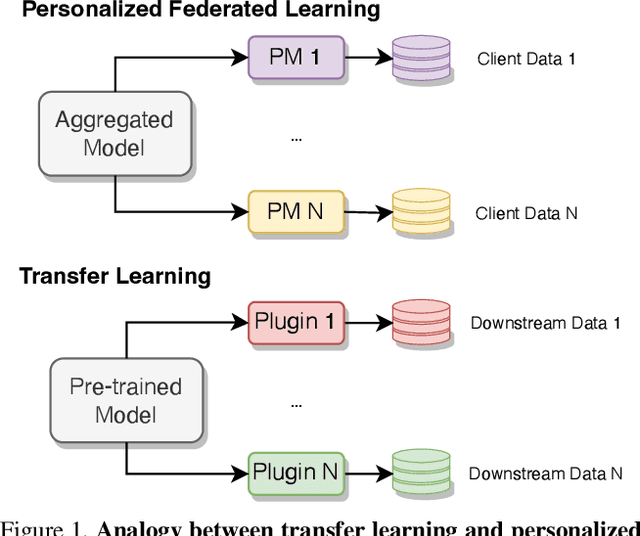

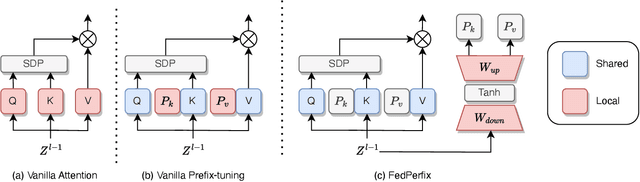
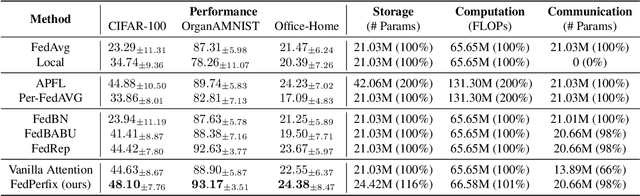
Personalized Federated Learning (PFL) represents a promising solution for decentralized learning in heterogeneous data environments. Partial model personalization has been proposed to improve the efficiency of PFL by selectively updating local model parameters instead of aggregating all of them. However, previous work on partial model personalization has mainly focused on Convolutional Neural Networks (CNNs), leaving a gap in understanding how it can be applied to other popular models such as Vision Transformers (ViTs). In this work, we investigate where and how to partially personalize a ViT model. Specifically, we empirically evaluate the sensitivity to data distribution of each type of layer. Based on the insights that the self-attention layer and the classification head are the most sensitive parts of a ViT, we propose a novel approach called FedPerfix, which leverages plugins to transfer information from the aggregated model to the local client as a personalization. Finally, we evaluate the proposed approach on CIFAR-100, OrganAMNIST, and Office-Home datasets and demonstrate its effectiveness in improving the model's performance compared to several advanced PFL methods.
GFM: Building Geospatial Foundation Models via Continual Pretraining
Feb 09, 2023Geospatial technologies are becoming increasingly essential in our world for a large range of tasks, such as earth monitoring and natural disaster response. To help improve the applicability and performance of deep learning models on these geospatial tasks, various works have pursued the idea of a geospatial foundation model, i.e., training networks from scratch on a large corpus of remote sensing imagery. However, this approach often requires a significant amount of data and training time to achieve suitable performance, especially when employing large state-of-the-art transformer models. In light of these challenges, we investigate a sustainable approach to building geospatial foundation models. In our investigations, we discover two important factors in the process. First, we find that the selection of pretraining data matters, even within the geospatial domain. We therefore gather a concise yet effective dataset for pretraining. Second, we find that available pretrained models on diverse datasets like ImageNet-22k should not be ignored when building geospatial foundation models, as their representations are still surprisingly effective. Rather, by leveraging their representations, we can build strong models for geospatial applications in a sustainable manner. To this end, we formulate a multi-objective continual pretraining approach for training sustainable geospatial foundation models. We experiment on a wide variety of downstream datasets and tasks, achieving strong performance across the board in comparison to ImageNet baselines and state-of-the-art geospatial pretrained models.
PGFed: Personalize Each Client's Global Objective for Federated Learning
Dec 02, 2022The mediocre performance of conventional federated learning (FL) over heterogeneous data has been facilitating personalized FL solutions, where, unlike conventional FL which trains a single global consensus model, different models are allowed for different clients. However, in most existing personalized FL algorithms, the collaborative knowledge across the federation was only implicitly passed to the clients in ways such as model aggregation or regularization. We observed that this implicit knowledge transfer fails to maximize the potential value of each client's empirical risk toward other clients. Based on our observation, in this work, we propose Personalized Global Federated Learning (PGFed), a novel personalized FL framework that enables each client to personalize its own global objective by explicitly and adaptively aggregating the empirical risks of itself and other clients. To avoid massive ($O(N^2)$) communication overhead and potential privacy leakage, each client's risk is estimated through a first-order approximation for other clients' adaptive risk aggregation. On top of PGFed, we develop a momentum upgrade, dubbed PGFedMo, to more efficiently utilize clients' empirical risks. Our extensive experiments under different federated settings with benchmark datasets show consistent improvements of PGFed over the compared state-of-the-art alternatives.
Exploring Parameter-Efficient Fine-tuning for Improving Communication Efficiency in Federated Learning
Oct 04, 2022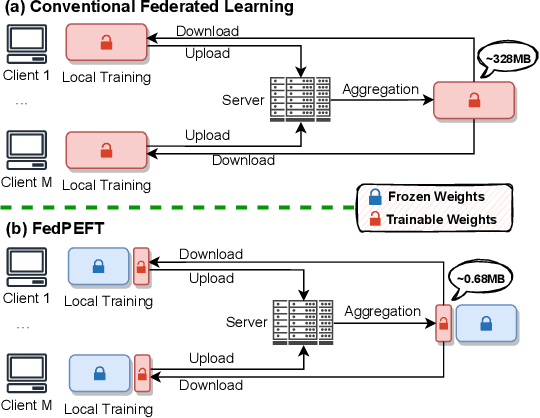
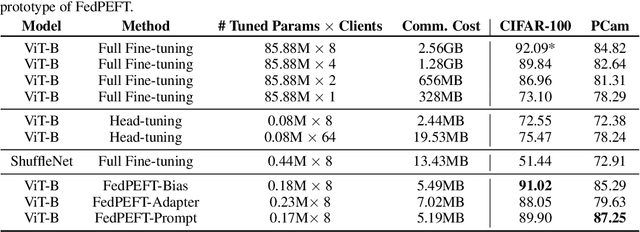
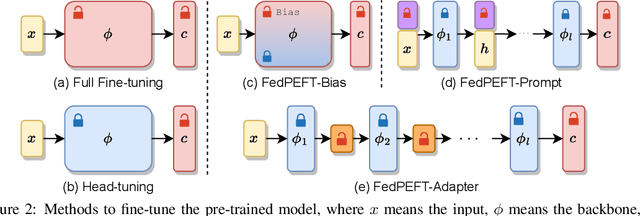

Federated learning (FL) has emerged as a promising paradigm for enabling the collaborative training of models without centralized access to the raw data on local devices. In the typical FL paradigm (e.g., FedAvg), model weights are sent to and from the server each round to participating clients. However, this can quickly put a massive communication burden on the system, especially if more capable models beyond very small MLPs are employed. Recently, the use of pre-trained models has been shown effective in federated learning optimization and improving convergence. This opens the door for new research questions. Can we adjust the weight-sharing paradigm in federated learning, leveraging strong and readily-available pre-trained models, to significantly reduce the communication burden while simultaneously achieving excellent performance? To this end, we investigate the use of parameter-efficient fine-tuning in federated learning. Specifically, we systemically evaluate the performance of several parameter-efficient fine-tuning methods across a variety of client stability, data distribution, and differential privacy settings. By only locally tuning and globally sharing a small portion of the model weights, significant reductions in the total communication overhead can be achieved while maintaining competitive performance in a wide range of federated learning scenarios, providing insight into a new paradigm for practical and effective federated systems.
HeatER: An Efficient and Unified Network for Human Reconstruction via Heatmap-based TransformER
May 30, 2022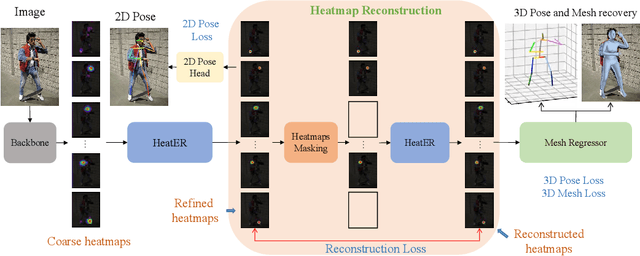
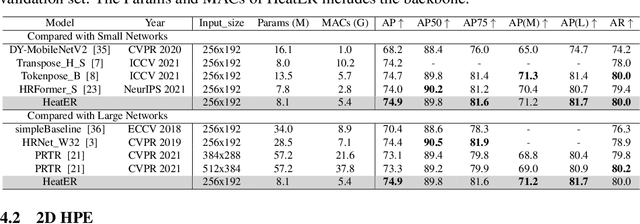
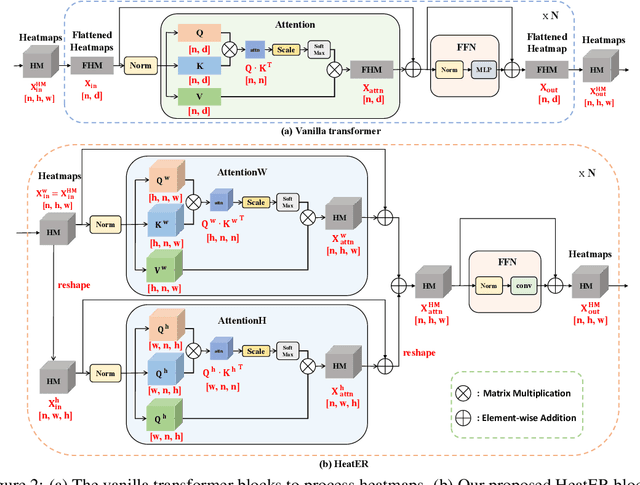
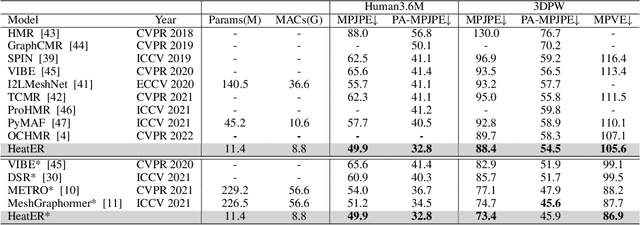
Recently, vision transformers have shown great success in 2D human pose estimation (2D HPE), 3D human pose estimation (3D HPE), and human mesh reconstruction (HMR) tasks. In these tasks, heatmap representations of the human structural information are often extracted first from the image by a CNN, and then further processed with a transformer architecture to provide the final HPE or HMR estimation. However, existing transformer architectures are not able to process these heatmap inputs directly, forcing an unnatural flattening of the features prior to input. Furthermore, much of the performance benefit in recent HPE and HMR methods has come at the cost of ever-increasing computation and memory needs. Therefore, to simultaneously address these problems, we propose HeatER, a novel transformer design which preserves the inherent structure of heatmap representations when modeling attention while reducing the memory and computational costs. Taking advantage of HeatER, we build a unified and efficient network for 2D HPE, 3D HPE, and HMR tasks. A heatmap reconstruction module is applied to improve the robustness of the estimated human pose and mesh. Extensive experiments demonstrate the effectiveness of HeatER on various human pose and mesh datasets. For instance, HeatER outperforms the SOTA method MeshGraphormer by requiring 5% of Params and 16% of MACs on Human3.6M and 3DPW datasets. Code will be publicly available.
POSTER: A Pyramid Cross-Fusion Transformer Network for Facial Expression Recognition
Apr 08, 2022
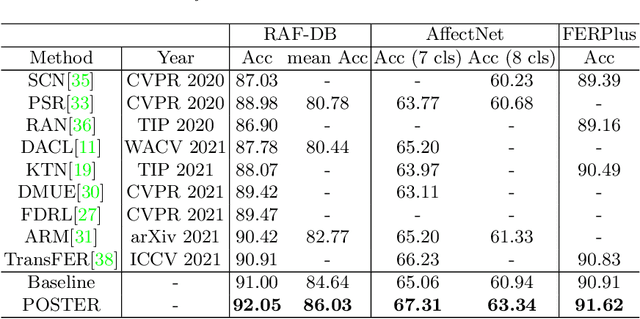
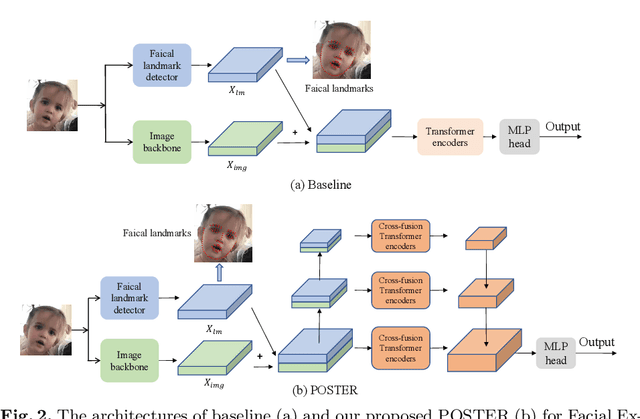
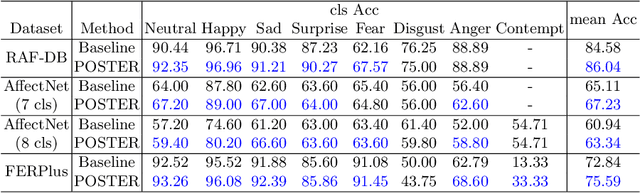
Facial Expression Recognition (FER) has received increasing interest in the computer vision community. As a challenging task, there are three key issues especially prevalent in FER: inter-class similarity, intra-class discrepancy, and scale sensitivity. Existing methods typically address some of these issues, but do not tackle them all in a unified framework. Therefore, in this paper, we propose a two-stream Pyramid crOss-fuSion TransformER network (POSTER) that aims to holistically solve these issues. Specifically, we design a transformer-based cross-fusion paradigm that enables effective collaboration of facial landmark and direct image features to maximize proper attention to salient facial regions. Furthermore, POSTER employs a pyramid structure to promote scale invariance. Extensive experimental results demonstrate that our POSTER outperforms SOTA methods on RAF-DB with 92.05%, FERPlus with 91.62%, AffectNet (7 cls) with 67.31%, and AffectNet (8 cls) with 63.34%, respectively.
Local Learning Matters: Rethinking Data Heterogeneity in Federated Learning
Nov 28, 2021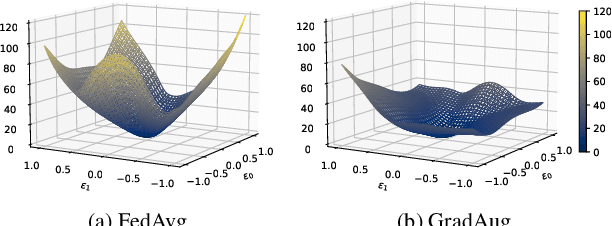
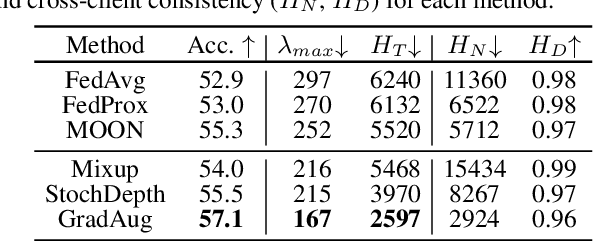
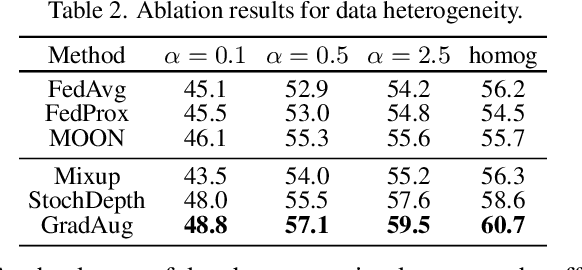
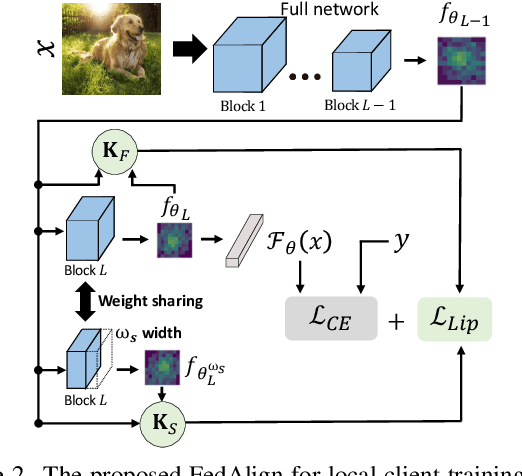
Federated learning (FL) is a promising strategy for performing privacy-preserving, distributed learning with a network of clients (i.e., edge devices). However, the data distribution among clients is often non-IID in nature, making efficient optimization difficult. To alleviate this issue, many FL algorithms focus on mitigating the effects of data heterogeneity across clients by introducing a variety of proximal terms, some incurring considerable compute and/or memory overheads, to restrain local updates with respect to the global model. Instead, we consider rethinking solutions to data heterogeneity in FL with a focus on local learning generality rather than proximal restriction. To this end, we first present a systematic study informed by second-order indicators to better understand algorithm effectiveness in FL. Interestingly, we find that standard regularization methods are surprisingly strong performers in mitigating data heterogeneity effects. Based on our findings, we further propose a simple and effective method, FedAlign, to overcome data heterogeneity and the pitfalls of previous methods. FedAlign achieves competitive accuracy with state-of-the-art FL methods across a variety of settings while minimizing computation and memory overhead. Code will be publicly available.
A Lightweight Graph Transformer Network for Human Mesh Reconstruction from 2D Human Pose
Nov 24, 2021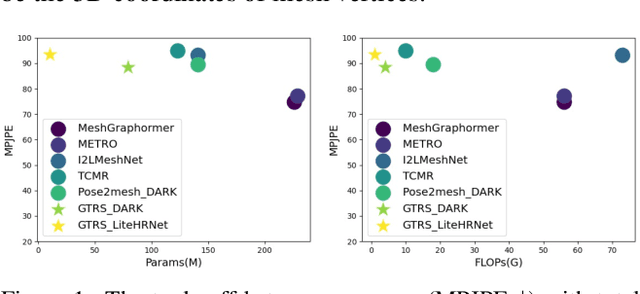
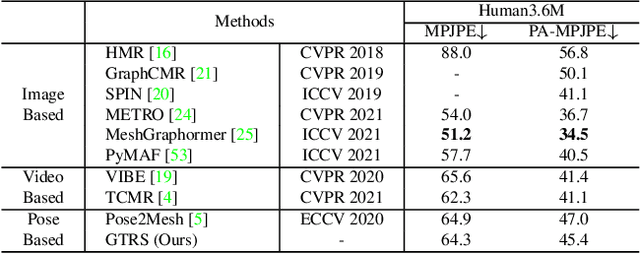
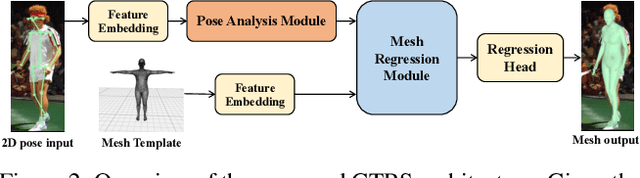
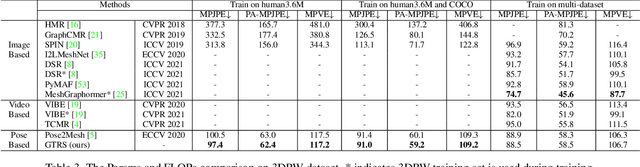
Existing deep learning-based human mesh reconstruction approaches have a tendency to build larger networks in order to achieve higher accuracy. Computational complexity and model size are often neglected, despite being key characteristics for practical use of human mesh reconstruction models (e.g. virtual try-on systems). In this paper, we present GTRS, a lightweight pose-based method that can reconstruct human mesh from 2D human pose. We propose a pose analysis module that uses graph transformers to exploit structured and implicit joint correlations, and a mesh regression module that combines the extracted pose feature with the mesh template to reconstruct the final human mesh. We demonstrate the efficiency and generalization of GTRS by extensive evaluations on the Human3.6M and 3DPW datasets. In particular, GTRS achieves better accuracy than the SOTA pose-based method Pose2Mesh while only using 10.2% of the parameters (Params) and 2.5% of the FLOPs on the challenging in-the-wild 3DPW dataset. Code will be publicly available.