 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOSTER: A Pyramid Cross-Fusion Transformer Network for Facial Expression Recognition
Paper and Code

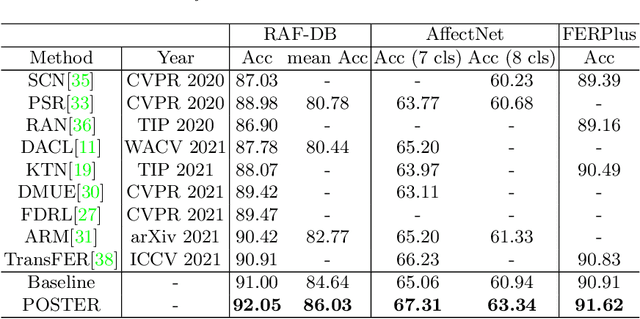
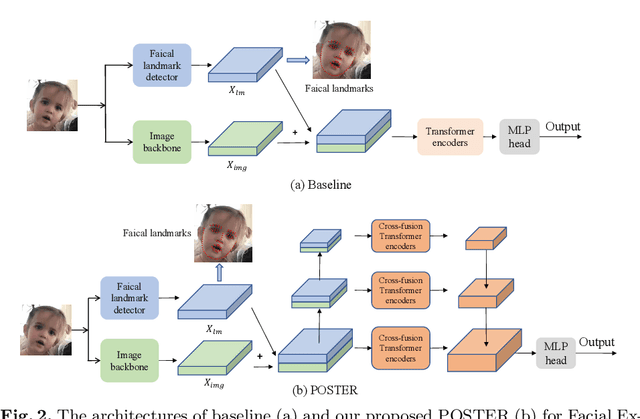
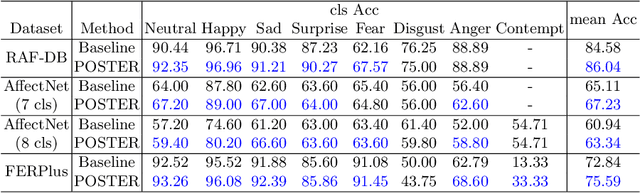
Facial Expression Recognition (FER) has received increasing interest in the computer vision community. As a challenging task, there are three key issues especially prevalent in FER: inter-class similarity, intra-class discrepancy, and scale sensitivity. Existing methods typically address some of these issues, but do not tackle them all in a unified framework. Therefore, in this paper, we propose a two-stream Pyramid crOss-fuSion TransformER network (POSTER) that aims to holistically solve these issues. Specifically, we design a transformer-based cross-fusion paradigm that enables effective collaboration of facial landmark and direct image features to maximize proper attention to salient facial regions. Furthermore, POSTER employs a pyramid structure to promote scale invariance. Extensive experimental results demonstrate that our POSTER outperforms SOTA methods on RAF-DB with 92.05%, FERPlus with 91.62%, AffectNet (7 cls) with 67.31%, and AffectNet (8 cls) with 63.34%, respectively.