 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Mamba for Hyperspectral Object Tracking
Sep 10, 2025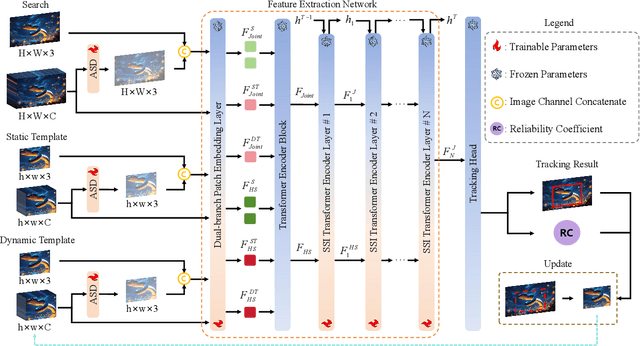
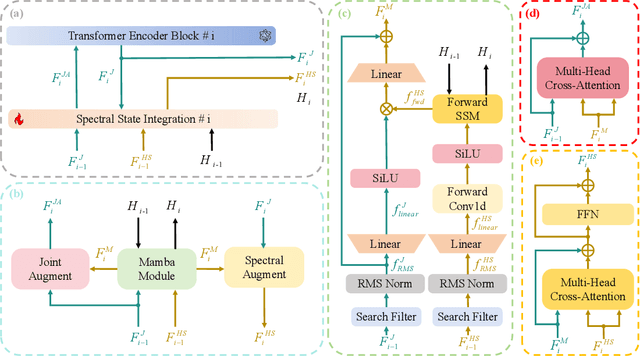
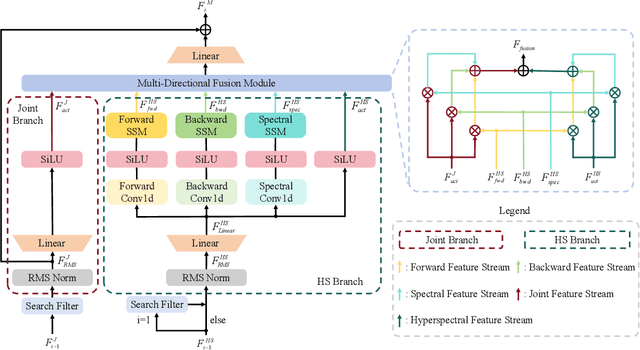
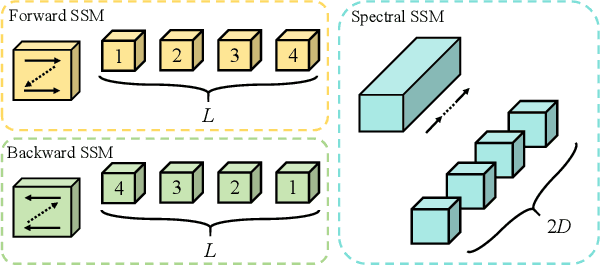
Hyperspectral object tracking holds great promise due to the rich spectral information and fine-grained material distinctions in hyperspectral images, which are beneficial in challenging scenarios. While existing hyperspectral trackers have made progress by either transforming hyperspectral data into false-color images or incorporating modality fusion strategies, they often fail to capture the intrinsic spectral information, temporal dependencies, and cross-depth interactions. To address these limitations, a new hyperspectral object tracking network equipped with Mamba (HyMamba), is proposed. It unifies spectral, cross-depth, and temporal modeling through state space modules (SSMs). The core of HyMamba lies in the Spectral State Integration (SSI) module, which enables progressive refinement and propagation of spectral features with cross-depth and temporal spectral information. Embedded within each SSI, the Hyperspectral Mamba (HSM) module is introduced to learn spatial and spectral information synchronously via three directional scanning SSMs. Based on SSI and HSM, HyMamba constructs joint features from false-color and hyperspectral inputs, and enhances them through interaction with original spectral features extracted from raw hyperspectral images. Extensive experiments conducted on seven benchmark datasets demonstrate that HyMamba achieves state-of-the-art performance. For instance, it achieves 73.0\% of the AUC score and 96.3\% of the DP@20 score on the HOTC2020 dataset. The code will be released at https://github.com/lgao001/HyMamba.
Hyperspectral Adapter for Object Tracking based on Hyperspectral Video
Mar 28, 2025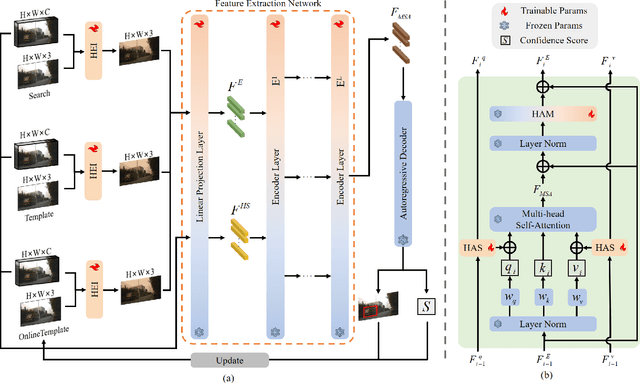
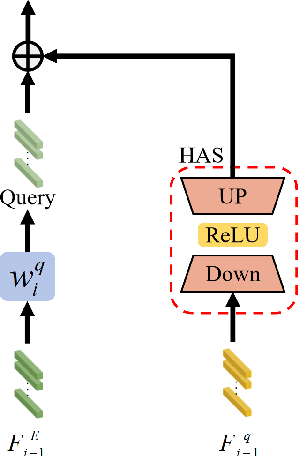
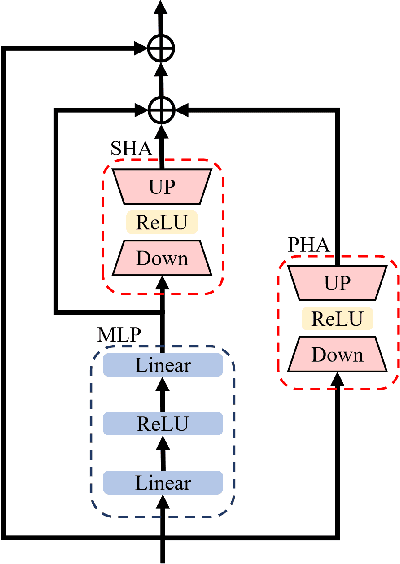
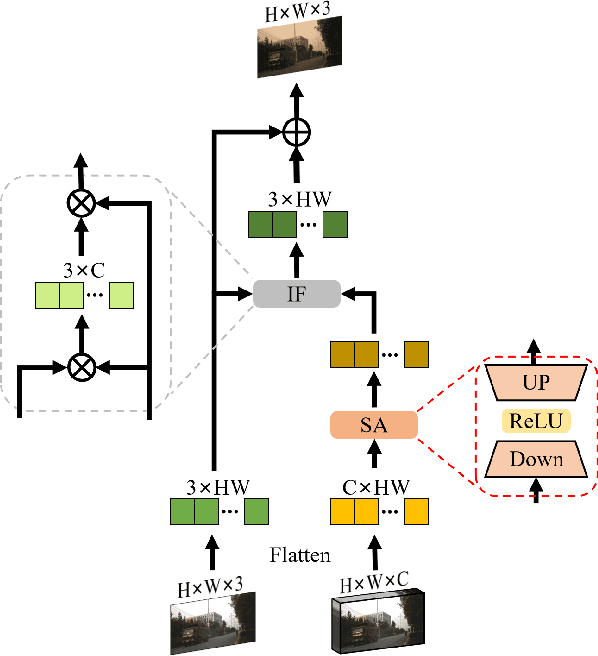
Object tracking based on hyperspectral video attracts increasing attention to the rich material and motion information in the hyperspectral videos. The prevailing hyperspectral methods adapt pretrained RGB-based object tracking networks for hyperspectral tasks by fine-tuning the entire network on hyperspectral datasets, which achieves impressive results in challenging scenarios. However, the performance of hyperspectral trackers is limited by the loss of spectral information during the transformation, and fine-tuning the entire pretrained network is inefficient for practical applications. To address the issues, a new hyperspectral object tracking method, hyperspectral adapter for tracking (HyA-T), is proposed in this work. The hyperspectral adapter for the self-attention (HAS) and the hyperspectral adapter for the multilayer perceptron (HAM) are proposed to generate the adaption information and to transfer the multi-head self-attention (MSA) module and the multilayer perceptron (MLP) in pretrained network for the hyperspectral object tracking task by augmenting the adaption information into the calculation of the MSA and MLP. Additionally, the hyperspectral enhancement of input (HEI) is proposed to augment the original spectral information into the input of the tracking network. The proposed methods extract spectral information directly from the hyperspectral images, which prevent the loss of the spectral information. Moreover, only the parameters in the proposed methods are fine-tuned, which is more efficient than the existing methods. Extensive experiments were conducted on four datasets with various spectral bands, verifing the effectiveness of the proposed methods. The HyA-T achieves state-of-the-art performance on all the datasets.
FGAD: Self-boosted Knowledge Distillation for An Effective Federated Graph Anomaly Detection Framework
Feb 20, 2024Graph anomaly detection (GAD) aims to identify anomalous graphs that significantly deviate from other ones, which has raised growing attention due to the broad existence and complexity of graph-structured data in many real-world scenarios. However, existing GAD methods usually execute with centralized training, which may lead to privacy leakage risk in some sensitive cases, thereby impeding collaboration among organizations seeking to collectively develop robust GAD models. Although federated learning offers a promising solution, the prevalent non-IID problems and high communication costs present significant challenges, particularly pronounced in collaborations with graph data distributed among different participants. To tackle these challenges, we propose an effective federated graph anomaly detection framework (FGAD). We first introduce an anomaly generator to perturb the normal graphs to be anomalous, and train a powerful anomaly detector by distinguishing generated anomalous graphs from normal ones. Then, we leverage a student model to distill knowledge from the trained anomaly detector (teacher model), which aims to maintain the personality of local models and alleviate the adverse impact of non-IID problems. Moreover, we design an effective collaborative learning mechanism that facilitates the personalization preservation of local models and significantly reduces communication costs among clients. Empirical results of the GAD tasks on non-IID graphs compared with state-of-the-art baselines demonstrate the superiority and efficiency of the proposed FGAD method.
Self-Discriminative Modeling for Anomalous Graph Detection
Oct 10, 2023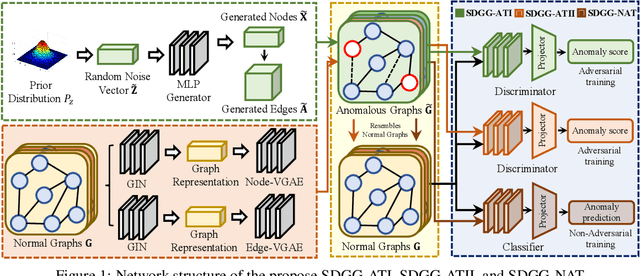
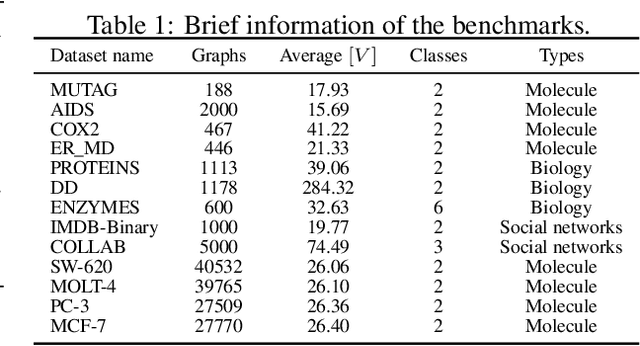
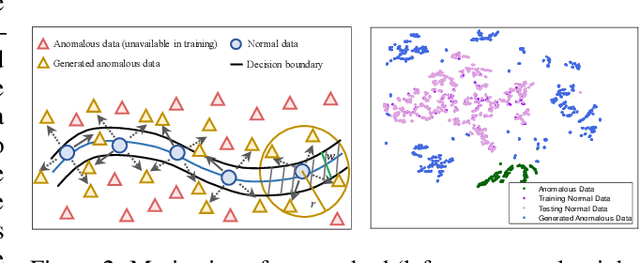
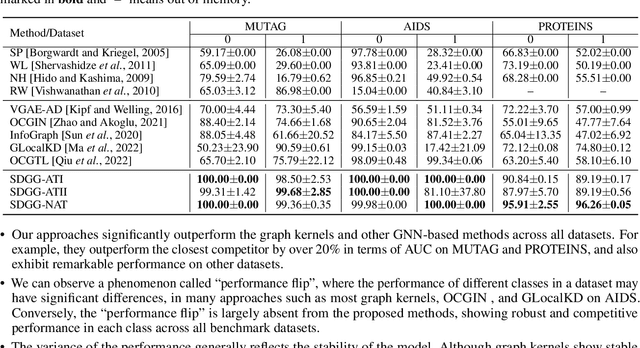
This paper studies the problem of detecting anomalous graphs using a machine learning model trained on only normal graphs, which has many applications in molecule, biology, and social network data analysis. We present a self-discriminative modeling framework for anomalous graph detection. The key idea, mathematically and numerically illustrated, is to learn a discriminator (classifier) from the given normal graphs together with pseudo-anomalous graphs generated by a model jointly trained, where we never use any true anomalous graphs and we hope that the generated pseudo-anomalous graphs interpolate between normal ones and (real) anomalous ones. Under the framework, we provide three algorithms with different computational efficiencies and stabilities for anomalous graph detection. The three algorithms are compared with several state-of-the-art graph-level anomaly detection baselines on nine popular graph datasets (four with small size and five with moderate size) and show significant improvement in terms of AUC. The success of our algorithms stems from the integration of the discriminative classifier and the well-posed pseudo-anomalous graphs, which provide new insights for anomaly detection. Moreover, we investigate our algorithms for large-scale imbalanced graph datasets. Surprisingly, our algorithms, though fully unsupervised, are able to significantly outperform supervised learning algorithms of anomalous graph detection. The corresponding reason is also analyzed.
Deep Graph-Level Orthogonal Hypersphere Compression for Anomaly Detection
Feb 13, 2023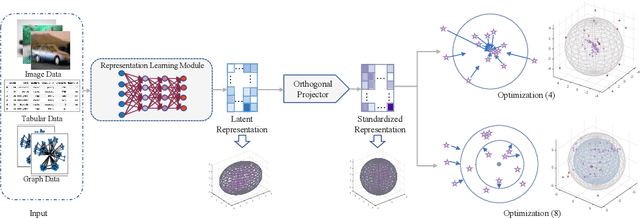
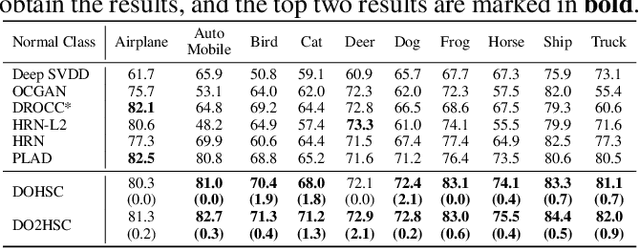
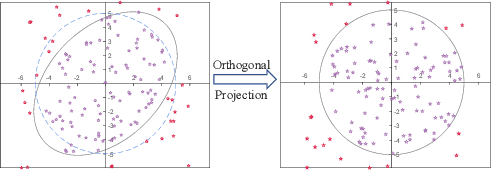
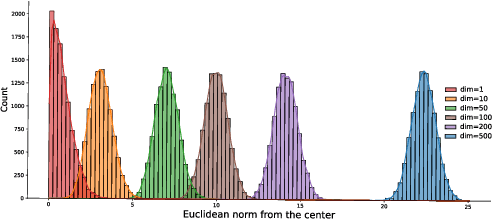
Graph-level anomaly detection aims to identify anomalous graphs from a collection of graphs in an unsupervised manner. A common assumption of anomaly detection is that a reasonable decision boundary has a hypersphere shape, but may appear some non-conforming phenomena in high dimensions. Towards this end, we firstly propose a novel deep graph-level anomaly detection model, which learns the graph representation with maximum mutual information between substructure and global structure features while exploring a hypersphere anomaly decision boundary. The idea is to ensure the training data distribution consistent with the decision hypersphere via an orthogonal projection layer. Moreover, we further perform the bi-hypersphere compression to emphasize the discrimination of anomalous graphs from normal graphs. Note that our method is not confined to graph data and is applicable to anomaly detection of other data such as images. The numerical and visualization results on benchmark datasets demonstrate the effectiveness and superiority of our methods in comparison to many baselines and state-of-the-arts.