 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSPM: Routing-Enabled Federated Learning under Dual Heterogeneity via Semiparametric Mixture
Jul 05, 2026Routing-prediction federated learning has emerged as a new paradigm that reframes inter-client heterogeneity as a resource for system-level intelligence: at inference time, the server routes each external query to the best-matched client for prediction. Existing approaches, however, typically treat each client as internally homogeneous, overlooking latent subpopulations within local data. For example, patients with the same diagnosis at one hospital may exhibit morphologically distinct disease subtypes. The coexistence of inter-client and intra-client heterogeneity, which we call dual heterogeneity, can impair both routing and prediction. To address this challenge, we propose FedSPM, a routing-enabled semiparametric mixture framework that represents each client using client-specific latent components. Each component combines a predictive distribution for classification with a feature distribution for routing. To flexibly model feature distributions while effectively sharing information across clients, FedSPM models their density ratios relative to a common nonparametric measure estimated via empirical likelihood. We develop a federated expectation-maximization algorithm that optimizes a tractable surrogate and prove convergence of the exact profiled objective at the standard $\mathcal{O}(1/\sqrt{T})$ rate when the surrogate errors are properly controlled. Experiments on controlled benchmarks and real-world medical data demonstrate consistent improvements in routing and prediction under dual heterogeneity. Code is available at https://github.com/zijianwang0510/FedSPM.
PFN-TS: Thompson Sampling for Contextual Bandits via Prior-Data Fitted Networks
May 11, 2026Thompson sampling is a widely used strategy for contextual bandits: at each round, it samples a reward function from a Bayesian posterior and acts greedily under that sample. Prior-data fitted networks (PFNs), such as TabPFN v2+ and TabICL v2, are attractive candidates for this purpose because they approximate Bayesian posterior predictive distributions in a single forward pass. However, PFNs predict noisy future rewards, while Thompson sampling requires uncertainty over the latent mean reward function. We propose PFN-TS, a Thompson sampling algorithm that converts PFN posterior predictives into mean-reward samples using a subsampled predictive central limit theorem. The method estimates posterior variance from a geometric grid of $O(\log n)$ dataset prefixes rather than the full $O(n)$ predictive sequence used in previous predictive-sequence approaches, and reuses TabICL's cached representations across rounds. We prove consistency of the subsampled variance estimator and give a Bayesian regret bound that decomposes PFN-TS regret into exact posterior-sampling regret under the PFN prior plus approximation terms. Empirically, PFN-TS achieves the best average rank across nonlinear synthetic and OpenML classification-to-bandit benchmarks, remains competitive on linear and BART-generated rewards, and attains the highest estimated policy value in an offline mobile-health evaluation. Code is available at https://anonymous.4open.science/r/PFN_TS-36ED/.
Verification Mirage: Mapping the Reliability Boundary of Self-Verification in Medical VQA
May 11, 2026Self-verification, re-invoking the same vision language model (VLM) in a fresh context to check its own generated answer, is increasingly used as a default safety layer for medical visual question answering (VQA). We argue that this practice is fundamentally unreliable. We introduce [METHOD NAME], a diagnostic framework for mapping the reliability boundary of medical VLM self-verification by decomposing verifier behavior into discrimination capability and agreement bias. Because the verifier and answer generator are capacity-coupled, the verifier can overly agree with the generator, creating a verification mirage: a regime with both high verifier error and high agreement bias, driven by false acceptance of incorrect answers. Evaluating six open-weight VLMs across five medical VQA datasets and seven medical tasks, we find that this boundary is strongly task-conditioned. Knowledge-intensive clinical tasks fall deepest into the mirage, simpler tasks are more resistant, and perceptual tasks lie in between. Verification also fails to provide an independent safety signal: logistic mixed-effects analysis shows that verifier error and agreement bias become more likely when the generator is wrong, while saliency analyses show that verifiers under-attend to image evidence relative to generators, a phenomenon we call the lazy verifier. Cross-verification reduces but does not eliminate the mirage. Moreover, when verification is reused in multi-turn actor-verifier loops, most initially wrong answers become locked in by false verification. Since our experiments use clean benchmarks, the observed reliability boundary likely underestimates failures in real clinical deployment.
Neyman-Pearson multiclass classification under label noise via empirical likelihood
Mar 23, 2026In many classification problems, the costs of misclassifying observations from different classes can be highly unequal. The Neyman-Pearson multiclass classification (NPMC) framework addresses this issue by minimizing a weighted misclassification risk while imposing upper bounds on class-specific error probabilities. Existing NPMC methods typically assume that training labels are correctly observed. In practice, however, labels are often corrupted due to measurement error or annotation, and the effect of such label noise on NPMC procedures remains largely unexplored. We study the NPMC problem when only noisy labels are available in the training data. We propose an empirical likelihood (EL)-based method that relates the distributions of noisy and true labels through an exponential tilting density ratio model. The resulting maximum EL estimators recover the class proportions and posterior probabilities of the clean labels required for error control. We establish consistency, asymptotic normality, and optimal convergence rates for these estimators. Under mild conditions, the resulting classifier satisfies NP oracle inequalities with respect to the true labels asymptotically. An expectation-maximization algorithm computes the maximum EL estimators. Simulations show that the proposed method performs comparably to the oracle classifier under clean labels and substantially improves over procedures that ignore label noise.
TabClustPFN: A Prior-Fitted Network for Tabular Data Clustering
Jan 29, 2026Clustering tabular data is a fundamental yet challenging problem due to heterogeneous feature types, diverse data-generating mechanisms, and the absence of transferable inductive biases across datasets. Prior-fitted networks (PFNs) have recently demonstrated strong generalization in supervised tabular learning by amortizing Bayesian inference under a broad synthetic prior. Extending this paradigm to clustering is nontrivial: clustering is unsupervised, admits a combinatorial and permutation-invariant output space, and requires inferring the number of clusters. We introduce TabClustPFN, a prior-fitted network for tabular data clustering that performs amortized Bayesian inference over both cluster assignments and cluster cardinality. Pretrained on synthetic datasets drawn from a flexible clustering prior, TabClustPFN clusters unseen datasets in a single forward pass, without dataset-specific retraining or hyperparameter tuning. The model naturally handles heterogeneous numerical and categorical features and adapts to a wide range of clustering structures. Experiments on synthetic data and curated real-world tabular benchmarks show that TabClustPFN outperforms classical, deep, and amortized clustering baselines, while exhibiting strong robustness in out-of-the-box exploratory settings. Code is available at https://github.com/Tianqi-Zhao/TabClustPFN.
Gaussian Herding across Pens: An Optimal Transport Perspective on Global Gaussian Reduction for 3DGS
Jun 11, 2025



3D Gaussian Splatting (3DGS) has emerged as a powerful technique for radiance field rendering, but it typically requires millions of redundant Gaussian primitives, overwhelming memory and rendering budgets. Existing compaction approaches address this by pruning Gaussians based on heuristic importance scores, without global fidelity guarantee. To bridge this gap, we propose a novel optimal transport perspective that casts 3DGS compaction as global Gaussian mixture reduction. Specifically, we first minimize the composite transport divergence over a KD-tree partition to produce a compact geometric representation, and then decouple appearance from geometry by fine-tuning color and opacity attributes with far fewer Gaussian primitives. Experiments on benchmark datasets show that our method (i) yields negligible loss in rendering quality (PSNR, SSIM, LPIPS) compared to vanilla 3DGS with only 10% Gaussians; and (ii) consistently outperforms state-of-the-art 3DGS compaction techniques. Notably, our method is applicable to any stage of vanilla or accelerated 3DGS pipelines, providing an efficient and agnostic pathway to lightweight neural rendering.
TabPFN: One Model to Rule Them All?
May 26, 2025Hollmann et al. (Nature 637 (2025) 319-326) recently introduced TabPFN, a transformer-based deep learning model for regression and classification on tabular data, which they claim "outperforms all previous methods on datasets with up to 10,000 samples by a wide margin, using substantially less training time." Furthermore, they have called TabPFN a "foundation model" for tabular data, as it can support "data generation, density estimation, learning reusable embeddings and fine-tuning". If these statements are well-supported, TabPFN may have the potential to supersede existing modeling approaches on a wide range of statistical tasks, mirroring a similar revolution in other areas of artificial intelligence that began with the advent of large language models. In this paper, we provide a tailored explanation of how TabPFN works for a statistics audience, by emphasizing its interpretation as approximate Bayesian inference. We also provide more evidence of TabPFN's "foundation model" capabilities: We show that an out-of-the-box application of TabPFN vastly outperforms specialized state-of-the-art methods for semi-supervised parameter estimation, prediction under covariate shift, and heterogeneous treatment effect estimation. We further show that TabPFN can outperform LASSO at sparse regression and can break a robustness-efficiency trade-off in classification. All experiments can be reproduced using the code provided at https://github.com/qinglong-tian/tabpfn_study (https://github.com/qinglong-tian/tabpfn_study).
CliniChat: A Multi-Source Knowledge-Driven Framework for Clinical Interview Dialogue Reconstruction and Evaluation
Apr 14, 2025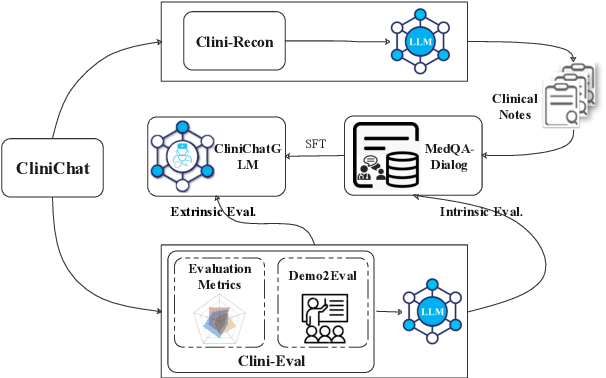

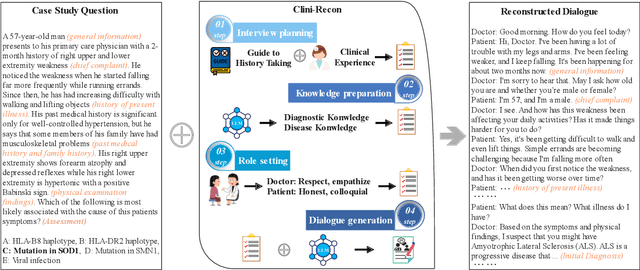
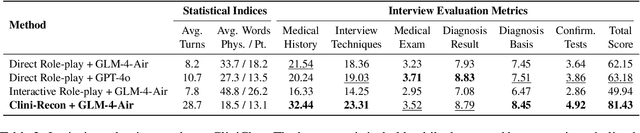
Large language models (LLMs) hold great promise for assisting clinical interviews due to their fluent interactive capabilities and extensive medical knowledge. However, the lack of high-quality interview dialogue data and widely accepted evaluation methods has significantly impeded this process. So we propose CliniChat, a framework that integrates multi-source knowledge to enable LLMs to simulate real-world clinical interviews. It consists of two modules: Clini-Recon and Clini-Eval, each responsible for reconstructing and evaluating interview dialogues, respectively. By incorporating three sources of knowledge, Clini-Recon transforms clinical notes into systematic, professional, and empathetic interview dialogues. Clini-Eval combines a comprehensive evaluation metric system with a two-phase automatic evaluation approach, enabling LLMs to assess interview performance like experts. We contribute MedQA-Dialog, a high-quality synthetic interview dialogue dataset, and CliniChatGLM, a model specialized for clinical interviews. Experimental results demonstrate that CliniChatGLM's interview capabilities undergo a comprehensive upgrade, particularly in history-taking, achieving state-of-the-art performance.
Just a Few Glances: Open-Set Visual Perception with Image Prompt Paradigm
Dec 14, 2024



To break through the limitations of pre-training models on fixed categories, Open-Set Object Detection (OSOD) and Open-Set Segmentation (OSS) have attracted a surge of interest from researchers. Inspired by large language models, mainstream OSOD and OSS methods generally utilize text as a prompt, achieving remarkable performance. Following SAM paradigm, some researchers use visual prompts, such as points, boxes, and masks that cover detection or segmentation targets. Despite these two prompt paradigms exhibit excellent performance, they also reveal inherent limitations. On the one hand, it is difficult to accurately describe characteristics of specialized category using textual description. On the other hand, existing visual prompt paradigms heavily rely on multi-round human interaction, which hinders them being applied to fully automated pipeline. To address the above issues, we propose a novel prompt paradigm in OSOD and OSS, that is, \textbf{Image Prompt Paradigm}. This brand new prompt paradigm enables to detect or segment specialized categories without multi-round human intervention. To achieve this goal, the proposed image prompt paradigm uses just a few image instances as prompts, and we propose a novel framework named \textbf{MI Grounding} for this new paradigm. In this framework, high-quality image prompts are automatically encoded, selected and fused, achieving the single-stage and non-interactive inference. We conduct extensive experiments on public datasets, showing that MI Grounding achieves competitive performance on OSOD and OSS benchmarks compared to text prompt paradigm methods and visual prompt paradigm methods. Moreover, MI Grounding can greatly outperform existing method on our constructed specialized ADR50K dataset.
Byzantine-tolerant distributed learning of finite mixture models
Jul 19, 2024



This paper proposes two split-and-conquer (SC) learning estimators for finite mixture models that are tolerant to Byzantine failures. In SC learning, individual machines obtain local estimates, which are then transmitted to a central server for aggregation. During this communication, the server may receive malicious or incorrect information from some local machines, a scenario known as Byzantine failures. While SC learning approaches have been devised to mitigate Byzantine failures in statistical models with Euclidean parameters, developing Byzantine-tolerant methods for finite mixture models with non-Euclidean parameters requires a distinct strategy. Our proposed distance-based methods are hyperparameter tuning free, unlike existing methods, and are resilient to Byzantine failures while achieving high statistical efficiency. We validate the effectiveness of our methods both theoretically and empirically via experiments on simulated and real data from machine learning applications for digit recognition. The code for the experiment can be found at https://github.com/SarahQiong/RobustSCGMM.