 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Episodic Memory in LLMs with Sequence Order Recall Tasks
Oct 10, 2024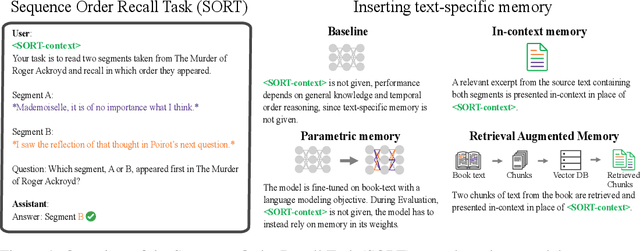
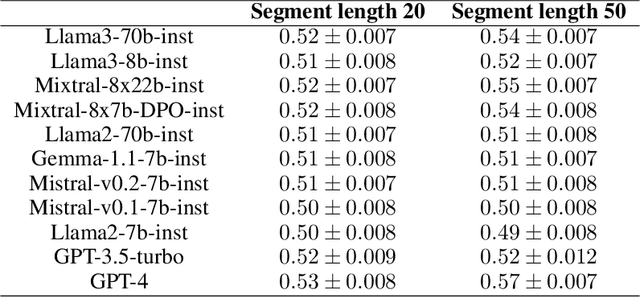
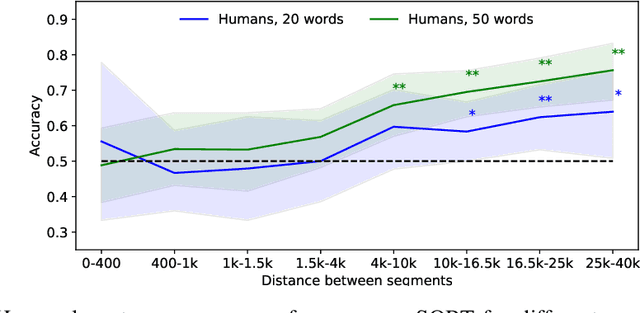
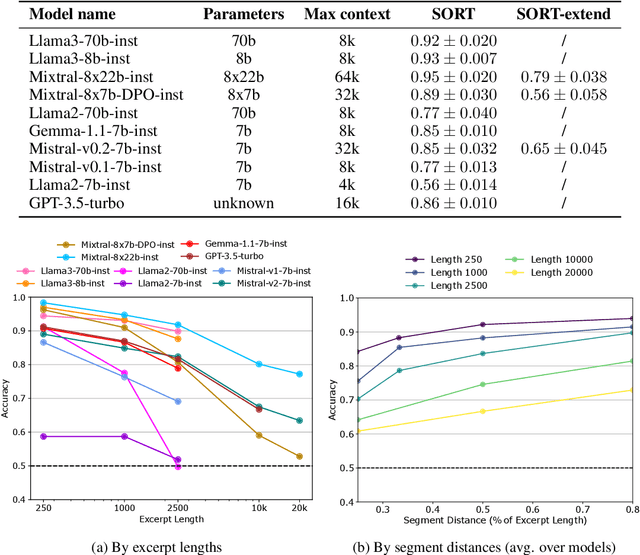
Current LLM benchmarks focus on evaluating models' memory of facts and semantic relations, primarily assessing semantic aspects of long-term memory. However, in humans, long-term memory also includes episodic memory, which links memories to their contexts, such as the time and place they occurred. The ability to contextualize memories is crucial for many cognitive tasks and everyday functions. This form of memory has not been evaluated in LLMs with existing benchmarks. To address the gap in evaluating memory in LLMs, we introduce Sequence Order Recall Tasks (SORT), which we adapt from tasks used to study episodic memory in cognitive psychology. SORT requires LLMs to recall the correct order of text segments, and provides a general framework that is both easily extendable and does not require any additional annotations. We present an initial evaluation dataset, Book-SORT, comprising 36k pairs of segments extracted from 9 books recently added to the public domain. Based on a human experiment with 155 participants, we show that humans can recall sequence order based on long-term memory of a book. We find that models can perform the task with high accuracy when relevant text is given in-context during the SORT evaluation. However, when presented with the book text only during training, LLMs' performance on SORT falls short. By allowing to evaluate more aspects of memory, we believe that SORT will aid in the emerging development of memory-augmented models.
MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
Mar 17, 2024Reconstructions of visual perception from brain activity have improved tremendously, but the practical utility of such methods has been limited. This is because such models are trained independently per subject where each subject requires dozens of hours of expensive fMRI training data to attain high-quality results. The present work showcases high-quality reconstructions using only 1 hour of fMRI training data. We pretrain our model across 7 subjects and then fine-tune on minimal data from a new subject. Our novel functional alignment procedure linearly maps all brain data to a shared-subject latent space, followed by a shared non-linear mapping to CLIP image space. We then map from CLIP space to pixel space by fine-tuning Stable Diffusion XL to accept CLIP latents as inputs instead of text. This approach improves out-of-subject generalization with limited training data and also attains state-of-the-art image retrieval and reconstruction metrics compared to single-subject approaches. MindEye2 demonstrates how accurate reconstructions of perception are possible from a single visit to the MRI facility. All code is available on GitHub.
Toward a More Biologically Plausible Neural Network Model of Latent Cause Inference
Dec 13, 2023Humans spontaneously perceive a continuous stream of experience as discrete events. It has been hypothesized that this ability is supported by latent cause inference (LCI). We implemented this hypothesis using Latent Cause Network (LCNet), a neural network model of LCI. LCNet interacts with a Bayesian LCI mechanism that activates a unique context vector for each inferred latent cause. This architecture makes LCNet more biologically plausible than existing models of LCI and supports extraction of shared structure across latent causes. Across three simulations, we found that LCNet could 1) extract shared structure across latent causes in a function-learning task while avoiding catastrophic interference, 2) capture human data on curriculum effects in schema learning, and 3) infer the underlying event structure when processing naturalistic videos of daily activities. Our work provides a biologically plausible computational model that can operate in both laboratory experiment settings and naturalistic settings, opening up the possibility of providing a unified model of event cognition.
Reconstructing the Mind's Eye: fMRI-to-Image with Contrastive Learning and Diffusion Priors
May 29, 2023
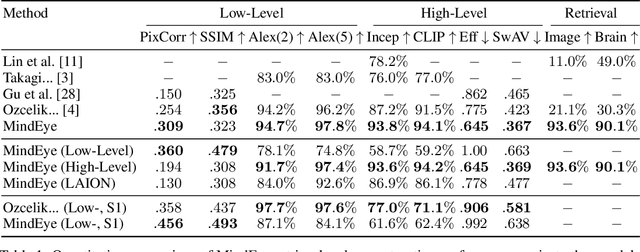
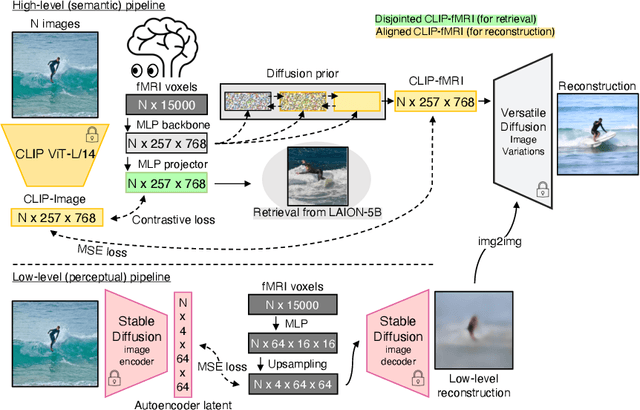
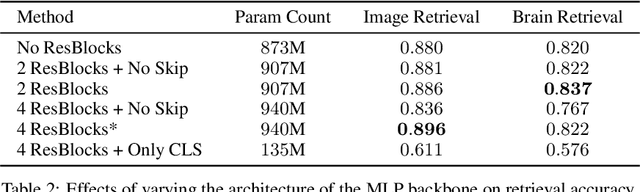
We present MindEye, a novel fMRI-to-image approach to retrieve and reconstruct viewed images from brain activity. Our model comprises two parallel submodules that are specialized for retrieval (using contrastive learning) and reconstruction (using a diffusion prior). MindEye can map fMRI brain activity to any high dimensional multimodal latent space, like CLIP image space, enabling image reconstruction using generative models that accept embeddings from this latent space. We comprehensively compare our approach with other existing methods, using both qualitative side-by-side comparisons and quantitative evaluations, and show that MindEye achieves state-of-the-art performance in both reconstruction and retrieval tasks. In particular, MindEye can retrieve the exact original image even among highly similar candidates indicating that its brain embeddings retain fine-grained image-specific information. This allows us to accurately retrieve images even from large-scale databases like LAION-5B. We demonstrate through ablations that MindEye's performance improvements over previous methods result from specialized submodules for retrieval and reconstruction, improved training techniques, and training models with orders of magnitude more parameters. Furthermore, we show that MindEye can better preserve low-level image features in the reconstructions by using img2img, with outputs from a separate autoencoder. All code is available on GitHub.
Large language models can segment narrative events similarly to humans
Jan 24, 2023Humans perceive discrete events such as "restaurant visits" and "train rides" in their continuous experience. One important prerequisite for studying human event perception is the ability of researchers to quantify when one event ends and another begins. Typically, this information is derived by aggregating behavioral annotations from several observers. Here we present an alternative computational approach where event boundaries are derived using a large language model, GPT-3, instead of using human annotations. We demonstrate that GPT-3 can segment continuous narrative text into events. GPT-3-annotated events are significantly correlated with human event annotations. Furthermore, these GPT-derived annotations achieve a good approximation of the "consensus" solution (obtained by averaging across human annotations); the boundaries identified by GPT-3 are closer to the consensus, on average, than boundaries identified by individual human annotators. This finding suggests that GPT-3 provides a feasible solution for automated event annotations, and it demonstrates a further parallel between human cognition and prediction in large language models. In the future, GPT-3 may thereby help to elucidate the principles underlying human event perception.
Shared Representational Geometry Across Neural Networks
Nov 28, 2018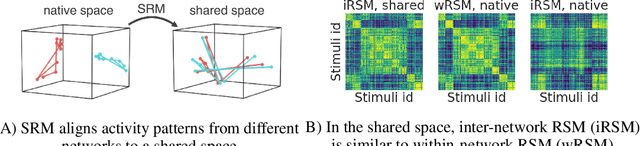
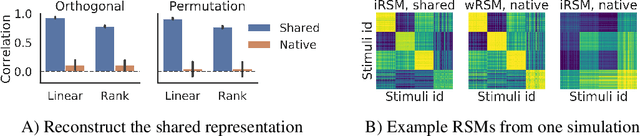
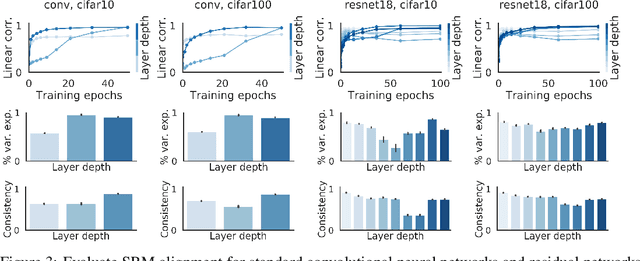
Different neural networks trained on the same dataset often learn similar input-output mappings with very different weights. Is there some correspondence between these neural network solutions? For linear networks, it has been shown that different instances of the same network architecture encode the same representational similarity matrix, and their neural activity patterns are connected by orthogonal transformations. However, it is unclear if this holds for non-linear networks. Using a shared response model, we show that different neural networks encode the same input examples as different orthogonal transformations of an underlying shared representation. We test this claim using both standard convolutional neural networks and residual networks on CIFAR10 and CIFAR100.
Leabra7: a Python package for modeling recurrent, biologically-realistic neural networks
Sep 19, 2018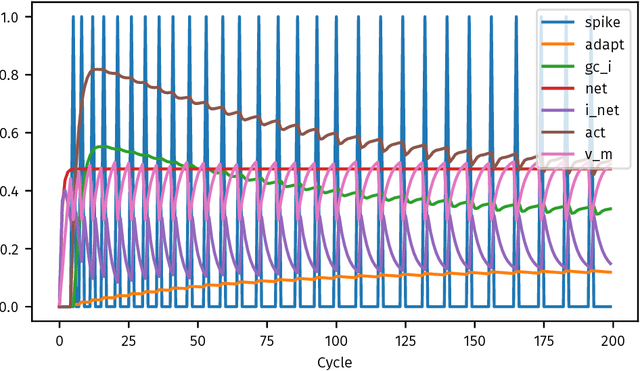



Emergent is a software package that uses the AdEx neural dynamics model and LEABRA learning algorithm to simulate and train arbitrary recurrent neural network architectures in a biologically-realistic manner. We present Leabra7, a complementary Python library that implements these same algorithms. Leabra7 is developed and distributed using modern software development principles, and integrates tightly with Python's scientific stack. We demonstrate recurrent Leabra7 networks using traditional pattern-association tasks and a standard machine learning task, classifying the IRIS dataset.
Enabling Factor Analysis on Thousand-Subject Neuroimaging Datasets
Aug 18, 2016
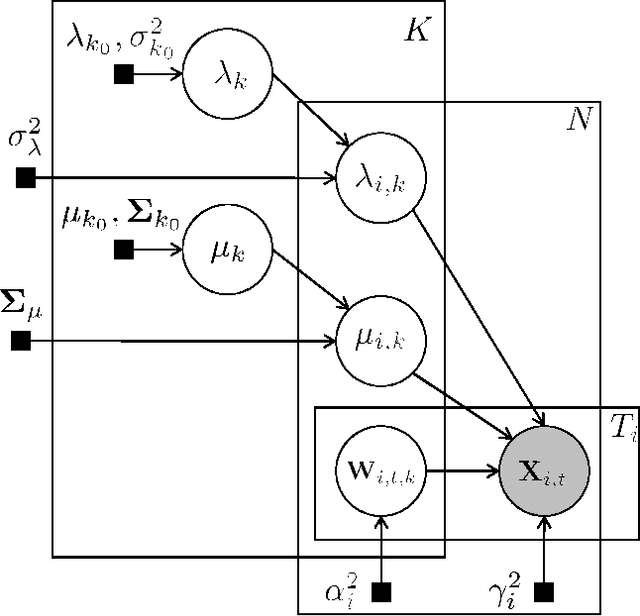
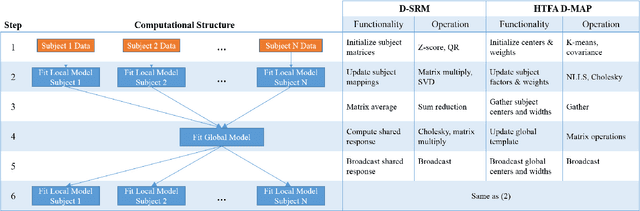
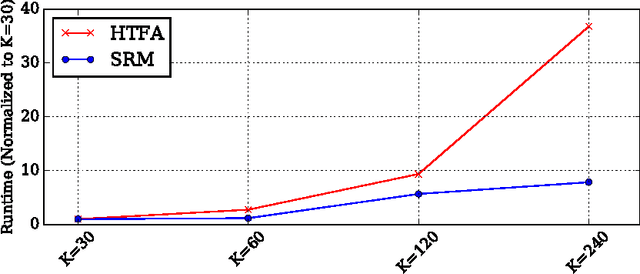
The scale of functional magnetic resonance image data is rapidly increasing as large multi-subject datasets are becoming widely available and high-resolution scanners are adopted. The inherent low-dimensionality of the information in this data has led neuroscientists to consider factor analysis methods to extract and analyze the underlying brain activity. In this work, we consider two recent multi-subject factor analysis methods: the Shared Response Model and Hierarchical Topographic Factor Analysis. We perform analytical, algorithmic, and code optimization to enable multi-node parallel implementations to scale. Single-node improvements result in 99x and 1812x speedups on these two methods, and enables the processing of larger datasets. Our distributed implementations show strong scaling of 3.3x and 5.5x respectively with 20 nodes on real datasets. We also demonstrate weak scaling on a synthetic dataset with 1024 subjects, on up to 1024 nodes and 32,768 cores.