 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Episodic Memory in LLMs with Sequence Order Recall Tasks
Oct 10, 2024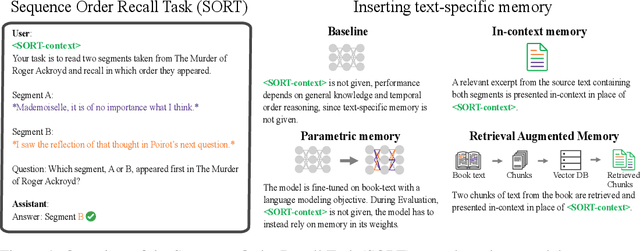
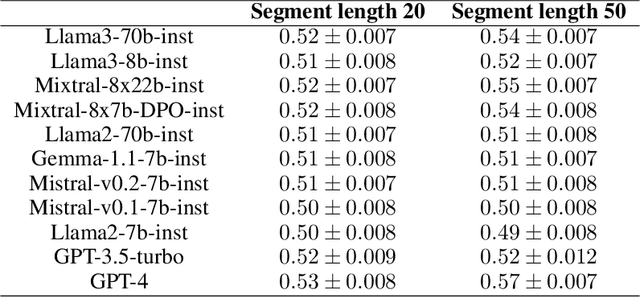
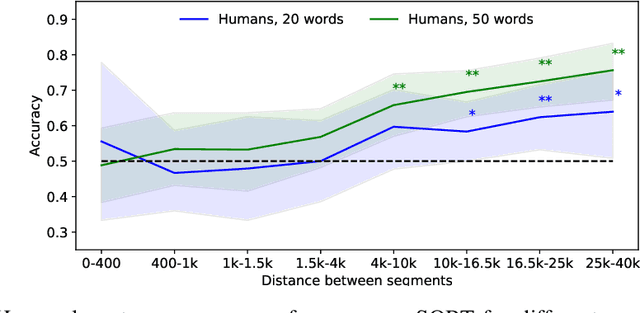
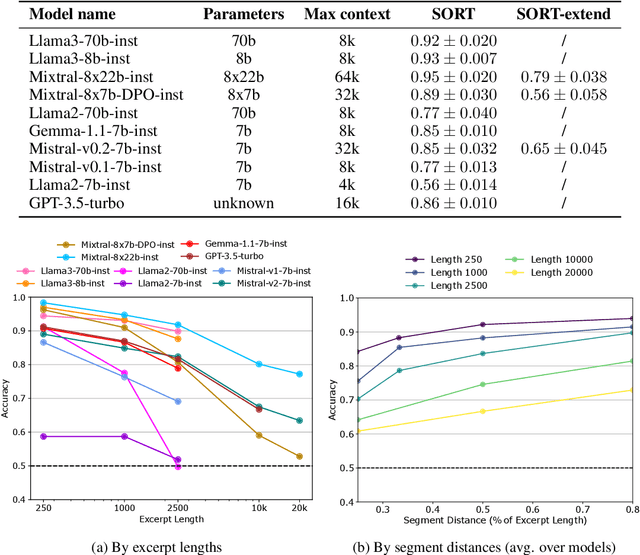
Current LLM benchmarks focus on evaluating models' memory of facts and semantic relations, primarily assessing semantic aspects of long-term memory. However, in humans, long-term memory also includes episodic memory, which links memories to their contexts, such as the time and place they occurred. The ability to contextualize memories is crucial for many cognitive tasks and everyday functions. This form of memory has not been evaluated in LLMs with existing benchmarks. To address the gap in evaluating memory in LLMs, we introduce Sequence Order Recall Tasks (SORT), which we adapt from tasks used to study episodic memory in cognitive psychology. SORT requires LLMs to recall the correct order of text segments, and provides a general framework that is both easily extendable and does not require any additional annotations. We present an initial evaluation dataset, Book-SORT, comprising 36k pairs of segments extracted from 9 books recently added to the public domain. Based on a human experiment with 155 participants, we show that humans can recall sequence order based on long-term memory of a book. We find that models can perform the task with high accuracy when relevant text is given in-context during the SORT evaluation. However, when presented with the book text only during training, LLMs' performance on SORT falls short. By allowing to evaluate more aspects of memory, we believe that SORT will aid in the emerging development of memory-augmented models.
Large language models can segment narrative events similarly to humans
Jan 24, 2023Humans perceive discrete events such as "restaurant visits" and "train rides" in their continuous experience. One important prerequisite for studying human event perception is the ability of researchers to quantify when one event ends and another begins. Typically, this information is derived by aggregating behavioral annotations from several observers. Here we present an alternative computational approach where event boundaries are derived using a large language model, GPT-3, instead of using human annotations. We demonstrate that GPT-3 can segment continuous narrative text into events. GPT-3-annotated events are significantly correlated with human event annotations. Furthermore, these GPT-derived annotations achieve a good approximation of the "consensus" solution (obtained by averaging across human annotations); the boundaries identified by GPT-3 are closer to the consensus, on average, than boundaries identified by individual human annotators. This finding suggests that GPT-3 provides a feasible solution for automated event annotations, and it demonstrates a further parallel between human cognition and prediction in large language models. In the future, GPT-3 may thereby help to elucidate the principles underlying human event perception.