 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Episodic Memory is the Missing Piece for Long-Term LLM Agents
Feb 10, 2025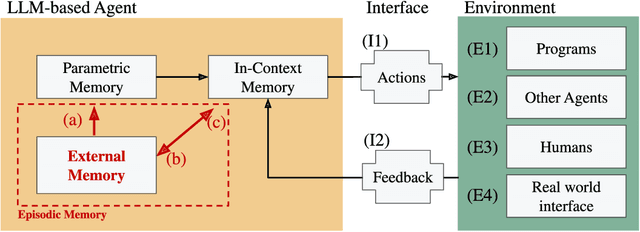

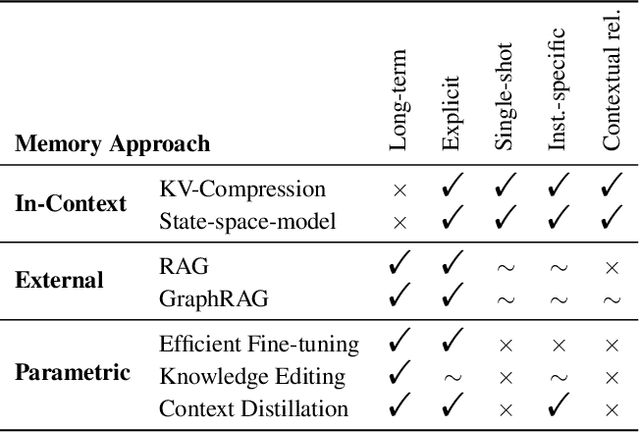
As Large Language Models (LLMs) evolve from text-completion tools into fully fledged agents operating in dynamic environments, they must address the challenge of continually learning and retaining long-term knowledge. Many biological systems solve these challenges with episodic memory, which supports single-shot learning of instance-specific contexts. Inspired by this, we present an episodic memory framework for LLM agents, centered around five key properties of episodic memory that underlie adaptive and context-sensitive behavior. With various research efforts already partially covering these properties, this position paper argues that now is the right time for an explicit, integrated focus on episodic memory to catalyze the development of long-term agents. To this end, we outline a roadmap that unites several research directions under the goal to support all five properties of episodic memory for more efficient long-term LLM agents.
Assessing Episodic Memory in LLMs with Sequence Order Recall Tasks
Oct 10, 2024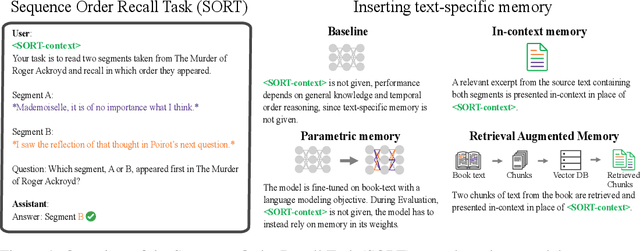
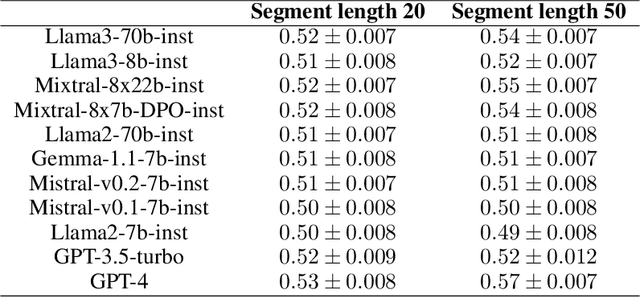
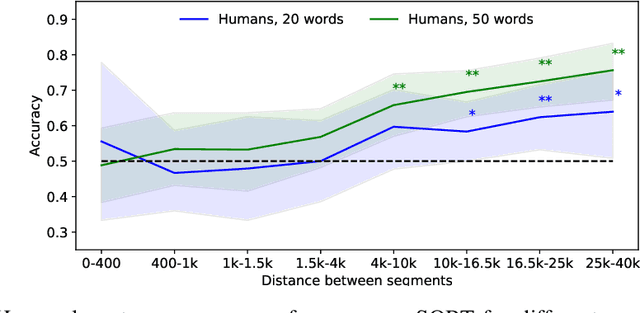
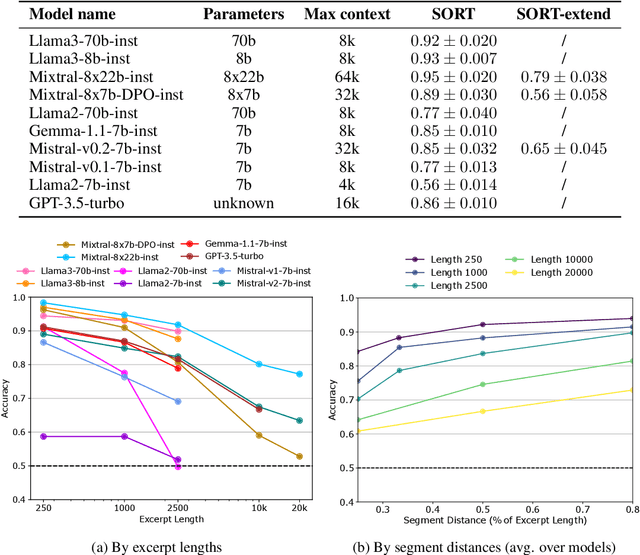
Current LLM benchmarks focus on evaluating models' memory of facts and semantic relations, primarily assessing semantic aspects of long-term memory. However, in humans, long-term memory also includes episodic memory, which links memories to their contexts, such as the time and place they occurred. The ability to contextualize memories is crucial for many cognitive tasks and everyday functions. This form of memory has not been evaluated in LLMs with existing benchmarks. To address the gap in evaluating memory in LLMs, we introduce Sequence Order Recall Tasks (SORT), which we adapt from tasks used to study episodic memory in cognitive psychology. SORT requires LLMs to recall the correct order of text segments, and provides a general framework that is both easily extendable and does not require any additional annotations. We present an initial evaluation dataset, Book-SORT, comprising 36k pairs of segments extracted from 9 books recently added to the public domain. Based on a human experiment with 155 participants, we show that humans can recall sequence order based on long-term memory of a book. We find that models can perform the task with high accuracy when relevant text is given in-context during the SORT evaluation. However, when presented with the book text only during training, LLMs' performance on SORT falls short. By allowing to evaluate more aspects of memory, we believe that SORT will aid in the emerging development of memory-augmented models.
A generative framework to bridge data-driven models and scientific theories in language neuroscience
Oct 01, 2024


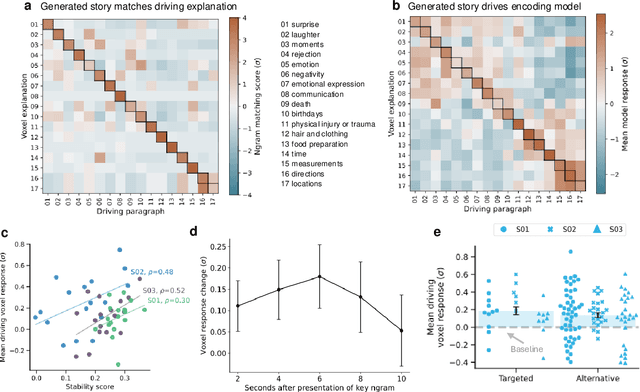
Representations from large language models are highly effective at predicting BOLD fMRI responses to language stimuli. However, these representations are largely opaque: it is unclear what features of the language stimulus drive the response in each brain area. We present generative explanation-mediated validation, a framework for generating concise explanations of language selectivity in the brain and then validating those explanations in follow-up experiments that use synthetic stimuli. This approach is successful at explaining selectivity both in individual voxels and cortical regions of interest (ROIs).We show that explanatory accuracy is closely related to the predictive power and stability of the underlying statistical models. These results demonstrate that LLMs can be used to bridge the widening gap between data-driven models and formal scientific theories.
How Many Bytes Can You Take Out Of Brain-To-Text Decoding?
May 22, 2024Brain-computer interfaces have promising medical and scientific applications for aiding speech and studying the brain. In this work, we propose an information-based evaluation metric for brain-to-text decoders. Using this metric, we examine two methods to augment existing state-of-the-art continuous text decoders. We show that these methods, in concert, can improve brain decoding performance by upwards of 40% when compared to a baseline model. We further examine the informatic properties of brain-to-text decoders and show empirically that they have Zipfian power law dynamics. Finally, we provide an estimate for the idealized performance of an fMRI-based text decoder. We compare this idealized model to our current model, and use our information-based metric to quantify the main sources of decoding error. We conclude that a practical brain-to-text decoder is likely possible given further algorithmic improvements.
Low-Dimensional Structure in the Space of Language Representations is Reflected in Brain Responses
Jun 15, 2021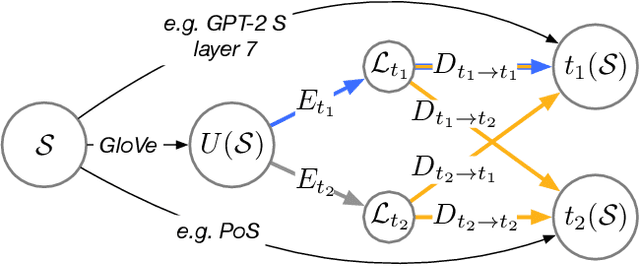
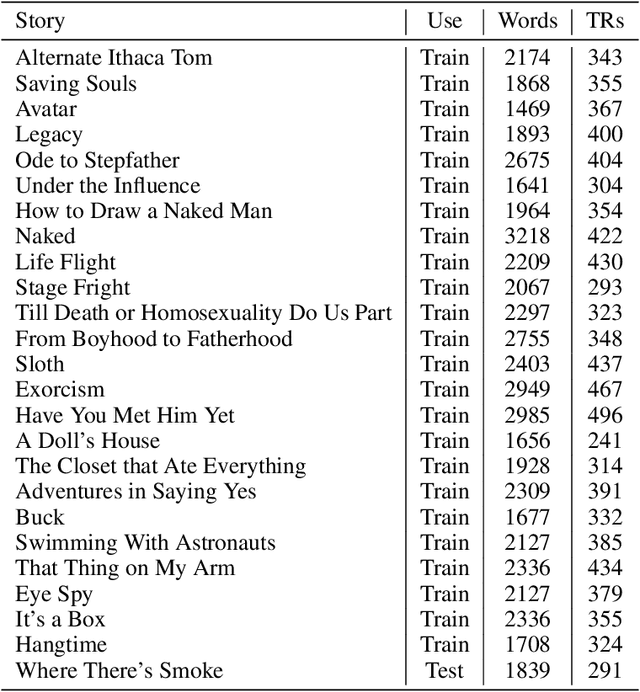
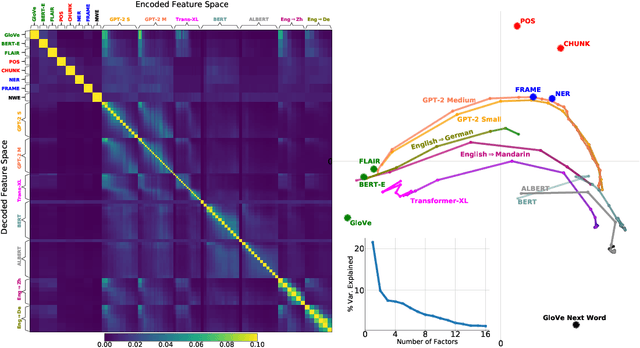
How related are the representations learned by neural language models, translation models, and language tagging tasks? We answer this question by adapting an encoder-decoder transfer learning method from computer vision to investigate the structure among 100 different feature spaces extracted from hidden representations of various networks trained on language tasks. This method reveals a low-dimensional structure where language models and translation models smoothly interpolate between word embeddings, syntactic and semantic tasks, and future word embeddings. We call this low-dimensional structure a language representation embedding because it encodes the relationships between representations needed to process language for a variety of NLP tasks. We find that this representation embedding can predict how well each individual feature space maps to human brain responses to natural language stimuli recorded using fMRI. Additionally, we find that the principal dimension of this structure can be used to create a metric which highlights the brain's natural language processing hierarchy. This suggests that the embedding captures some part of the brain's natural language representation structure.
Selecting Informative Contexts Improves Language Model Finetuning
May 01, 2020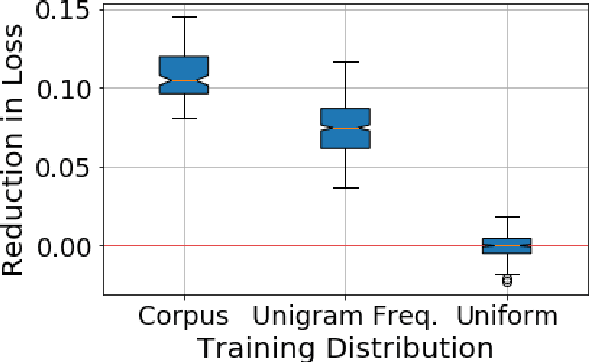
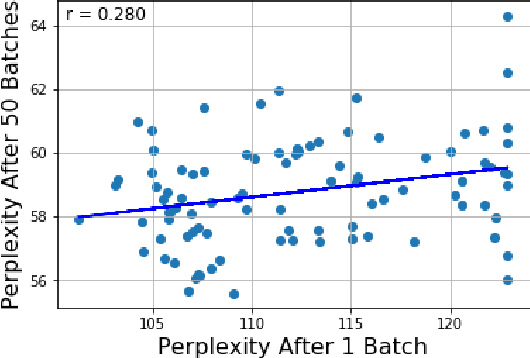
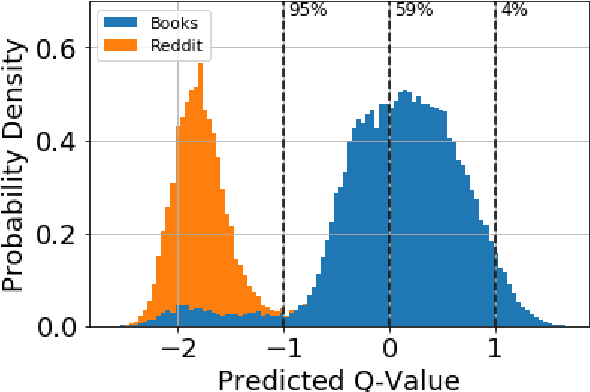
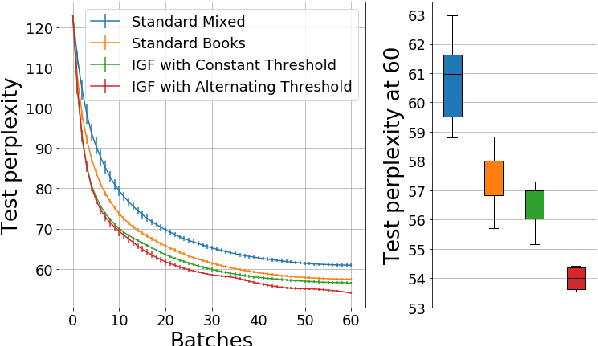
We present a general finetuning meta-method that we call information gain filtration for improving the overall training efficiency and final performance of language model finetuning. This method uses a secondary learner which attempts to quantify the benefit of finetuning the language model on each given example. During the finetuning process, we use this learner to decide whether or not each given example should be trained on or skipped. We show that it suffices for this learner to be simple and that the finetuning process itself is dominated by the relatively trivial relearning of a new unigram frequency distribution over the modelled language domain, a process which the learner aids. Our method trains to convergence using 40% fewer batches than normal finetuning, and achieves a median perplexity of 54.0 on a books dataset compared to a median perplexity of 57.3 for standard finetuning using the same neural architecture.
Deep Generative Modeling for Scene Synthesis via Hybrid Representations
Aug 06, 2018
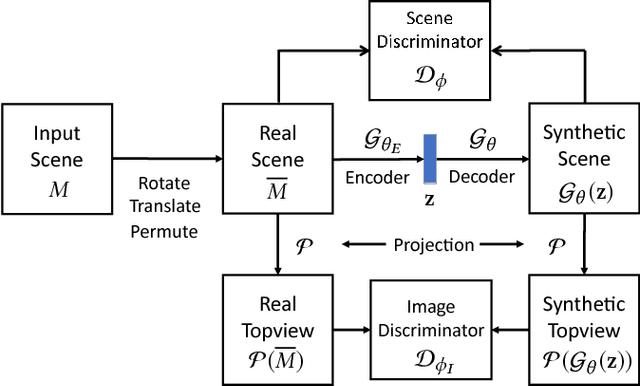
We present a deep generative scene modeling technique for indoor environments. Our goal is to train a generative model using a feed-forward neural network that maps a prior distribution (e.g., a normal distribution) to the distribution of primary objects in indoor scenes. We introduce a 3D object arrangement representation that models the locations and orientations of objects, based on their size and shape attributes. Moreover, our scene representation is applicable for 3D objects with different multiplicities (repetition counts), selected from a database. We show a principled way to train this model by combining discriminator losses for both a 3D object arrangement representation and a 2D image-based representation. We demonstrate the effectiveness of our scene representation and the deep learning method on benchmark datasets. We also show the applications of this generative model in scene interpolation and scene completion.
Efficient, sparse representation of manifold distance matrices for classical scaling
Mar 29, 2018
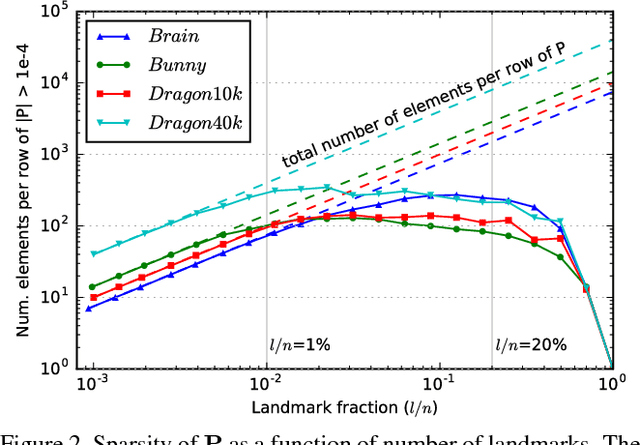
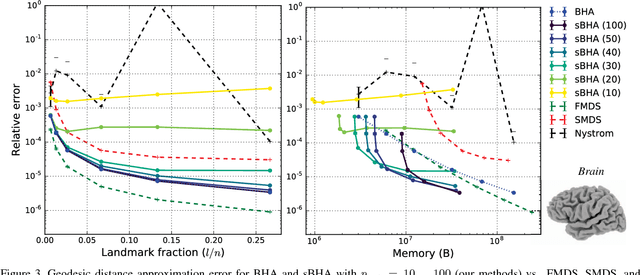
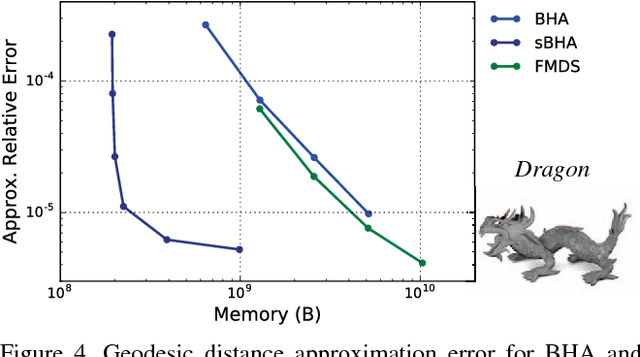
Geodesic distance matrices can reveal shape properties that are largely invariant to non-rigid deformations, and thus are often used to analyze and represent 3-D shapes. However, these matrices grow quadratically with the number of points. Thus for large point sets it is common to use a low-rank approximation to the distance matrix, which fits in memory and can be efficiently analyzed using methods such as multidimensional scaling (MDS). In this paper we present a novel sparse method for efficiently representing geodesic distance matrices using biharmonic interpolation. This method exploits knowledge of the data manifold to learn a sparse interpolation operator that approximates distances using a subset of points. We show that our method is 2x faster and uses 20x less memory than current leading methods for solving MDS on large point sets, with similar quality. This enables analyses of large point sets that were previously infeasible.