 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing CBMs Through Binary Distillation with Applications to Test-Time Intervention
Mar 09, 2025Concept bottleneck models~(CBM) aim to improve model interpretability by predicting human level ``concepts" in a bottleneck within a deep learning model architecture. However, how the predicted concepts are used in predicting the target still either remains black-box or is simplified to maintain interpretability at the cost of prediction performance. We propose to use Fast Interpretable Greedy Sum-Trees~(FIGS) to obtain Binary Distillation~(BD). This new method, called FIGS-BD, distills a binary-augmented concept-to-target portion of the CBM into an interpretable tree-based model, while mimicking the competitive prediction performance of the CBM teacher. FIGS-BD can be used in downstream tasks to explain and decompose CBM predictions into interpretable binary-concept-interaction attributions and guide adaptive test-time intervention. Across $4$ datasets, we demonstrate that adaptive test-time intervention identifies key concepts that significantly improve performance for realistic human-in-the-loop settings that allow for limited concept interventions.
A generative framework to bridge data-driven models and scientific theories in language neuroscience
Oct 01, 2024


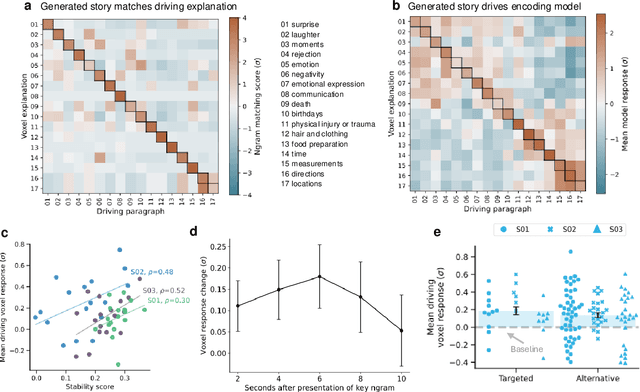
Representations from large language models are highly effective at predicting BOLD fMRI responses to language stimuli. However, these representations are largely opaque: it is unclear what features of the language stimulus drive the response in each brain area. We present generative explanation-mediated validation, a framework for generating concise explanations of language selectivity in the brain and then validating those explanations in follow-up experiments that use synthetic stimuli. This approach is successful at explaining selectivity both in individual voxels and cortical regions of interest (ROIs).We show that explanatory accuracy is closely related to the predictive power and stability of the underlying statistical models. These results demonstrate that LLMs can be used to bridge the widening gap between data-driven models and formal scientific theories.