 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelecting Informative Contexts Improves Language Model Finetuning
Paper and Code
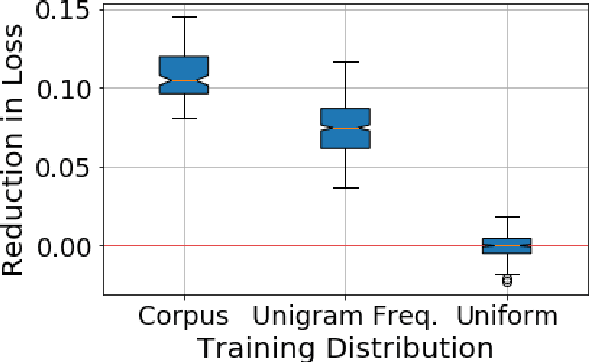
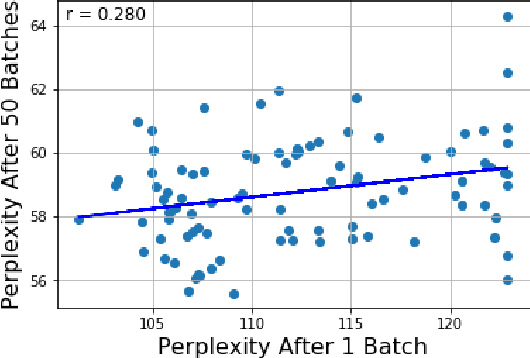
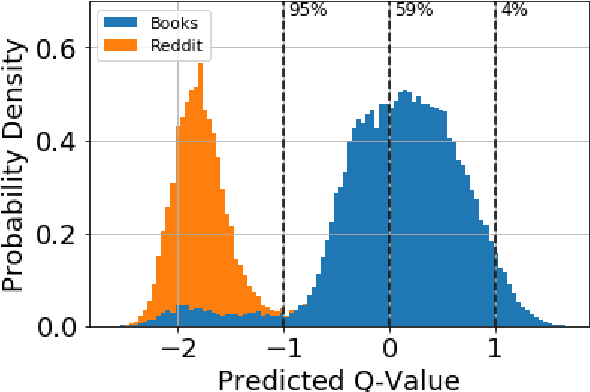
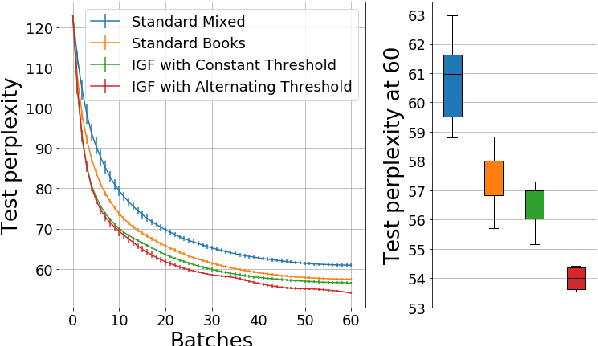
We present a general finetuning meta-method that we call information gain filtration for improving the overall training efficiency and final performance of language model finetuning. This method uses a secondary learner which attempts to quantify the benefit of finetuning the language model on each given example. During the finetuning process, we use this learner to decide whether or not each given example should be trained on or skipped. We show that it suffices for this learner to be simple and that the finetuning process itself is dominated by the relatively trivial relearning of a new unigram frequency distribution over the modelled language domain, a process which the learner aids. Our method trains to convergence using 40% fewer batches than normal finetuning, and achieves a median perplexity of 54.0 on a books dataset compared to a median perplexity of 57.3 for standard finetuning using the same neural architecture.