 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Algorithmic Self-Portrait: Deconstructing Memory in ChatGPT
Feb 03, 2026To enable personalized and context-aware interactions, conversational AI systems have introduced a new mechanism: Memory. Memory creates what we refer to as the Algorithmic Self-portrait - a new form of personalization derived from users' self-disclosed information divulged within private conversations. While memory enables more coherent exchanges, the underlying processes of memory creation remain opaque, raising critical questions about data sensitivity, user agency, and the fidelity of the resulting portrait. To bridge this research gap, we analyze 2,050 memory entries from 80 real-world ChatGPT users. Our analyses reveal three key findings: (1) A striking 96% of memories in our dataset are created unilaterally by the conversational system, potentially shifting agency away from the user; (2) Memories, in our dataset, contain a rich mix of GDPR-defined personal data (in 28% memories) along with psychological insights about participants (in 52% memories); and (3)~A significant majority of the memories (84%) are directly grounded in user context, indicating faithful representation of the conversations. Finally, we introduce a framework-Attribution Shield-that anticipates these inferences, alerts about potentially sensitive memory inferences, and suggests query reformulations to protect personal information without sacrificing utility.
Rote Learning Considered Useful: Generalizing over Memorized Data in LLMs
Jul 29, 2025Rote learning is a memorization technique based on repetition. It is commonly believed to hinder generalization by encouraging verbatim memorization rather than deeper understanding. This insight holds for even learning factual knowledge that inevitably requires a certain degree of memorization. In this work, we demonstrate that LLMs can be trained to generalize from rote memorized data. We introduce a two-phase memorize-then-generalize framework, where the model first rote memorizes factual subject-object associations using a semantically meaningless token and then learns to generalize by fine-tuning on a small set of semantically meaningful prompts. Extensive experiments over 8 LLMs show that the models can reinterpret rote memorized data through the semantically meaningful prompts, as evidenced by the emergence of structured, semantically aligned latent representations between the two. This surprising finding opens the door to both effective and efficient knowledge injection and possible risks of repurposing the memorized data for malicious usage.
Revisiting Privacy, Utility, and Efficiency Trade-offs when Fine-Tuning Large Language Models
Feb 18, 2025We study the inherent trade-offs in minimizing privacy risks and maximizing utility, while maintaining high computational efficiency, when fine-tuning large language models (LLMs). A number of recent works in privacy research have attempted to mitigate privacy risks posed by memorizing fine-tuning data by using differentially private training methods (e.g., DP), albeit at a significantly higher computational cost (inefficiency). In parallel, several works in systems research have focussed on developing (parameter) efficient fine-tuning methods (e.g., LoRA), but few works, if any, investigated whether such efficient methods enhance or diminish privacy risks. In this paper, we investigate this gap and arrive at a surprising conclusion: efficient fine-tuning methods like LoRA mitigate privacy risks similar to private fine-tuning methods like DP. Our empirical finding directly contradicts prevailing wisdom that privacy and efficiency objectives are at odds during fine-tuning. Our finding is established by (a) carefully defining measures of privacy and utility that distinguish between memorizing sensitive and non-sensitive tokens in training and test datasets used in fine-tuning and (b) extensive evaluations using multiple open-source language models from Pythia, Gemma, and Llama families and different domain-specific datasets.
Position: Episodic Memory is the Missing Piece for Long-Term LLM Agents
Feb 10, 2025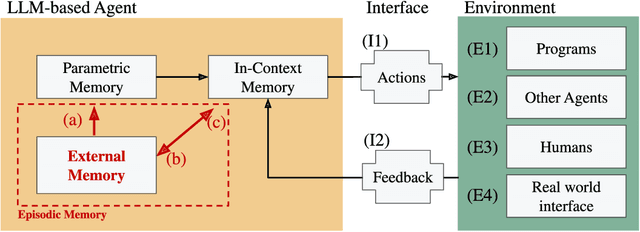

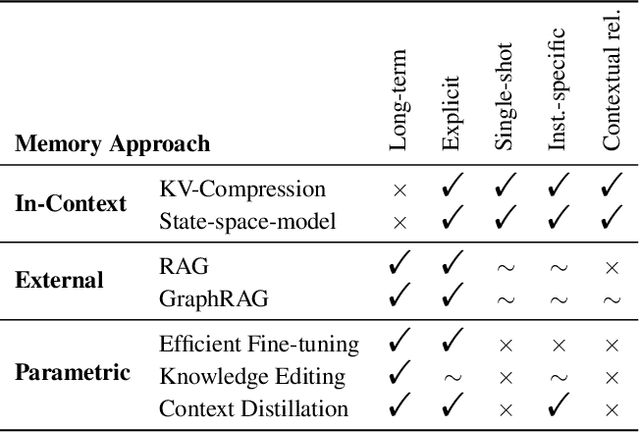
As Large Language Models (LLMs) evolve from text-completion tools into fully fledged agents operating in dynamic environments, they must address the challenge of continually learning and retaining long-term knowledge. Many biological systems solve these challenges with episodic memory, which supports single-shot learning of instance-specific contexts. Inspired by this, we present an episodic memory framework for LLM agents, centered around five key properties of episodic memory that underlie adaptive and context-sensitive behavior. With various research efforts already partially covering these properties, this position paper argues that now is the right time for an explicit, integrated focus on episodic memory to catalyze the development of long-term agents. To this end, we outline a roadmap that unites several research directions under the goal to support all five properties of episodic memory for more efficient long-term LLM agents.
Assessing Episodic Memory in LLMs with Sequence Order Recall Tasks
Oct 10, 2024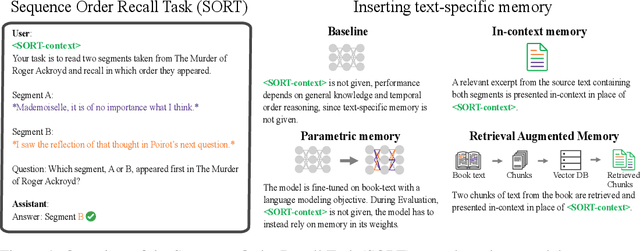
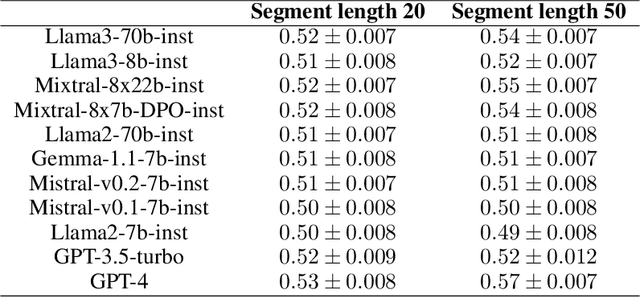
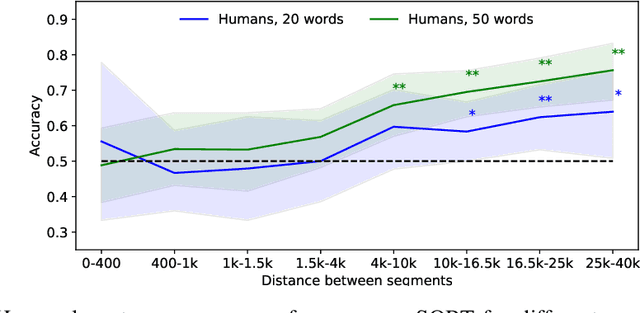
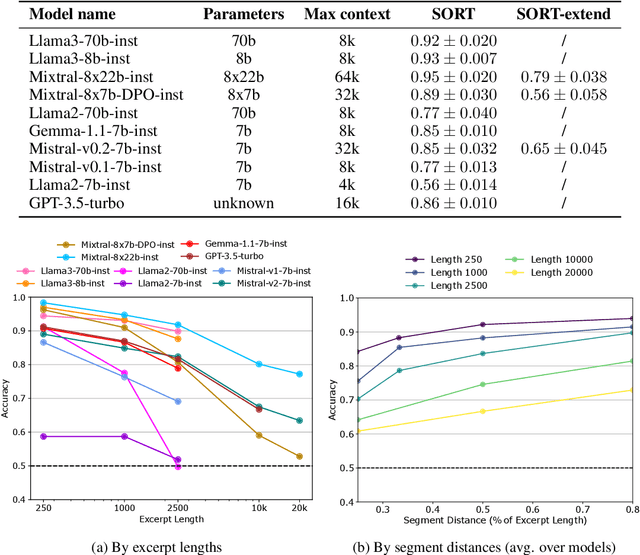
Current LLM benchmarks focus on evaluating models' memory of facts and semantic relations, primarily assessing semantic aspects of long-term memory. However, in humans, long-term memory also includes episodic memory, which links memories to their contexts, such as the time and place they occurred. The ability to contextualize memories is crucial for many cognitive tasks and everyday functions. This form of memory has not been evaluated in LLMs with existing benchmarks. To address the gap in evaluating memory in LLMs, we introduce Sequence Order Recall Tasks (SORT), which we adapt from tasks used to study episodic memory in cognitive psychology. SORT requires LLMs to recall the correct order of text segments, and provides a general framework that is both easily extendable and does not require any additional annotations. We present an initial evaluation dataset, Book-SORT, comprising 36k pairs of segments extracted from 9 books recently added to the public domain. Based on a human experiment with 155 participants, we show that humans can recall sequence order based on long-term memory of a book. We find that models can perform the task with high accuracy when relevant text is given in-context during the SORT evaluation. However, when presented with the book text only during training, LLMs' performance on SORT falls short. By allowing to evaluate more aspects of memory, we believe that SORT will aid in the emerging development of memory-augmented models.
Understanding Memorisation in LLMs: Dynamics, Influencing Factors, and Implications
Jul 27, 2024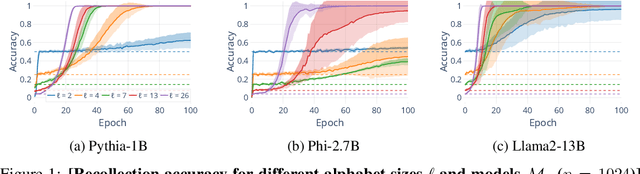
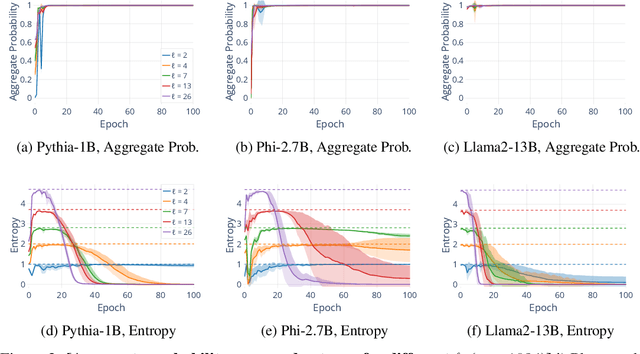
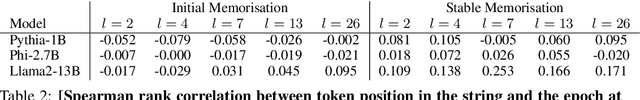
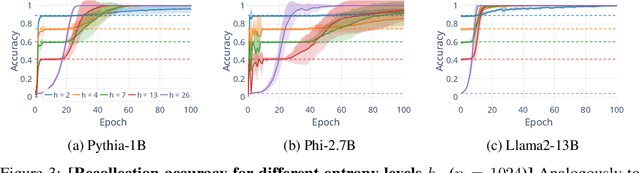
Understanding whether and to what extent large language models (LLMs) have memorised training data has important implications for the reliability of their output and the privacy of their training data. In order to cleanly measure and disentangle memorisation from other phenomena (e.g. in-context learning), we create an experimental framework that is based on repeatedly exposing LLMs to random strings. Our framework allows us to better understand the dynamics, i.e., the behaviour of the model, when repeatedly exposing it to random strings. Using our framework, we make several striking observations: (a) we find consistent phases of the dynamics across families of models (Pythia, Phi and Llama2), (b) we identify factors that make some strings easier to memorise than others, and (c) we identify the role of local prefixes and global context in memorisation. We also show that sequential exposition to different random strings has a significant effect on memorisation. Our results, often surprising, have significant downstream implications in the study and usage of LLMs.
Towards Reliable Latent Knowledge Estimation in LLMs: In-Context Learning vs. Prompting Based Factual Knowledge Extraction
Apr 19, 2024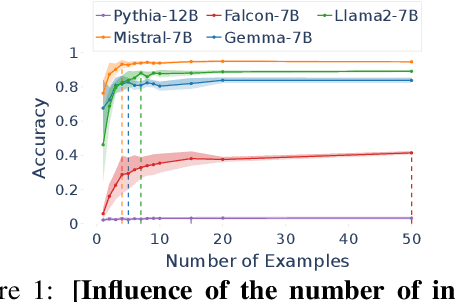
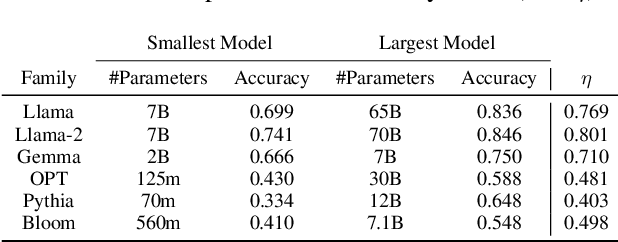
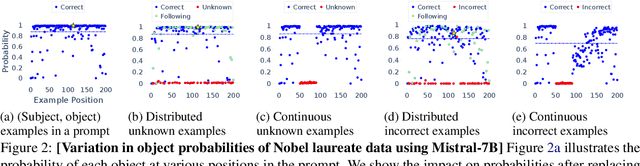
We propose an approach for estimating the latent knowledge embedded inside large language models (LLMs). We leverage the in-context learning (ICL) abilities of LLMs to estimate the extent to which an LLM knows the facts stored in a knowledge base. Our knowledge estimator avoids reliability concerns with previous prompting-based methods, is both conceptually simpler and easier to apply, and we demonstrate that it can surface more of the latent knowledge embedded in LLMs. We also investigate how different design choices affect the performance of ICL-based knowledge estimation. Using the proposed estimator, we perform a large-scale evaluation of the factual knowledge of a variety of open source LLMs, like OPT, Pythia, Llama(2), Mistral, Gemma, etc. over a large set of relations and facts from the Wikidata knowledge base. We observe differences in the factual knowledge between different model families and models of different sizes, that some relations are consistently better known than others but that models differ in the precise facts they know, and differences in the knowledge of base models and their finetuned counterparts.
A Negation Quantum Decision Model to Predict the Interference Effect in Categorization
Apr 19, 2021



Categorization is a significant task in decision-making, which is a key part of human behavior. An interference effect is caused by categorization in some cases, which breaks the total probability principle. A negation quantum model (NQ model) is developed in this article to predict the interference. Taking the advantage of negation to bring more information in the distribution from a different perspective, the proposed model is a combination of the negation of a probability distribution and the quantum decision model. Information of the phase contained in quantum probability and the special calculation method to it can easily represented the interference effect. The results of the proposed NQ model is closely to the real experiment data and has less error than the existed models.
Exponential Negation of a Probability Distribution
Oct 22, 2020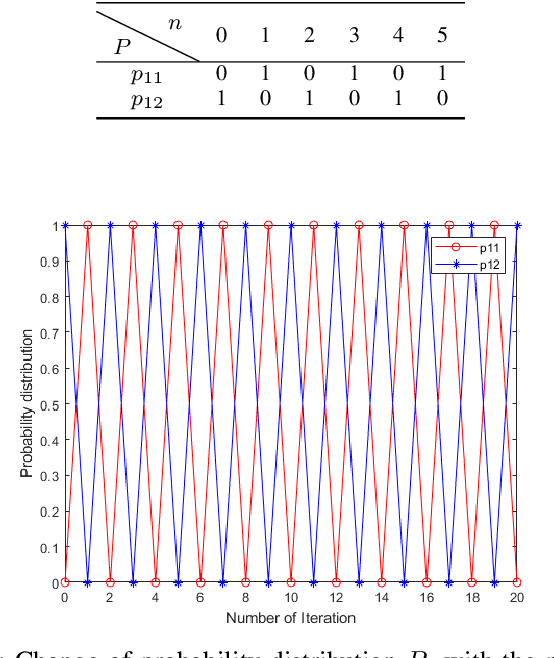
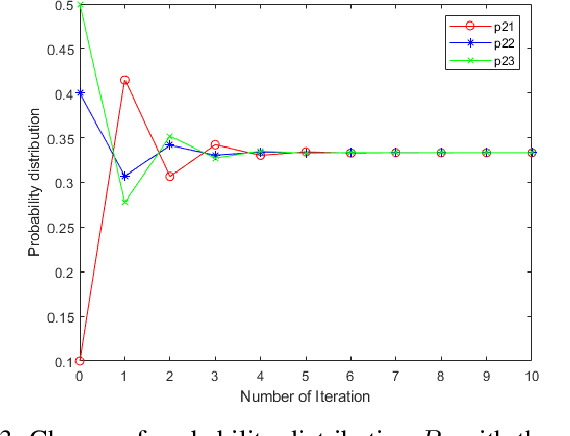
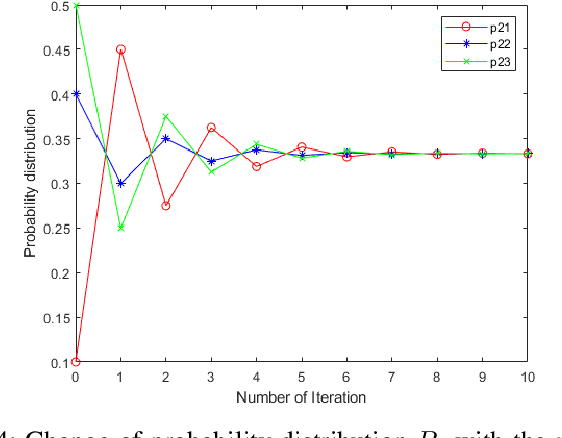
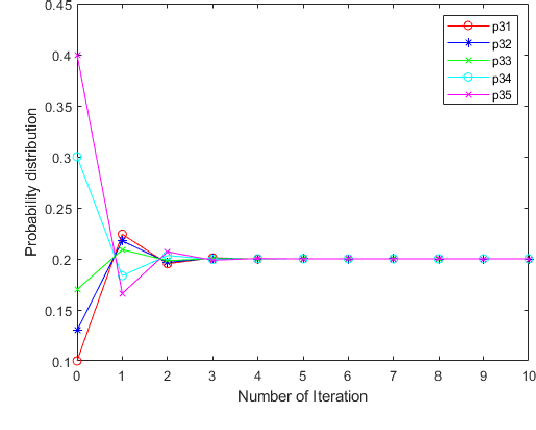
Negation operation is important in intelligent information processing. Different with existing arithmetic negation, an exponential negation is presented in this paper. The new negation can be seen as a kind of geometry negation. Some basic properties of the proposed negation is investigated, we find that the fix point is the uniform probability distribution.The negation is an entropy increase operation and all the probability distributions will converge to the uniform distribution after multiple negation iterations. The number of iterations of convergence is inversely proportional to the number of elements in the distribution. Some numerical examples are used to illustrate the efficiency of the proposed negation.