 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning vs. In-context Learning in Large Language Models: A Formal Language Learning Perspective
Apr 25, 2026Large language models (LLMs) operate in two fundamental learning modes - fine-tuning (FT) and in-context learning (ICL) - raising key questions about which mode yields greater language proficiency and whether they differ in their inductive biases. Prior studies comparing FT and ICL have yielded mixed and inconclusive results due to inconsistent experimental setups. To enable a rigorous comparison, we propose a formal language learning task - offering precise language boundaries, controlled string sampling, and no data contamination - and introduce a discriminative test for language proficiency, where an LLM succeeds if it assigns higher generation probability to in-language strings than to out-of-language strings. Empirically, we find that: (a) FT has greater language proficiency than ICL on in-distribution generalization, but both perform equally well on out-of-distribution generalization. (b) Their inductive biases, measured by the correlation in string generation probabilities, are similar when both modes partially learn the language but diverge at higher proficiency levels. (c) Unlike FT, ICL performance differs substantially across models of varying sizes and families and is sensitive to the token vocabulary of the language. Thus, our work demonstrates the promise of formal languages as a controlled testbed for evaluating LLMs, behaviors that are difficult to isolate in natural language datasets. Our source code is available at https://github.com/bishwamittra/formallm.
In Agents We Trust, but Who Do Agents Trust? Latent Source Preferences Steer LLM Generations
Feb 17, 2026Agents based on Large Language Models (LLMs) are increasingly being deployed as interfaces to information on online platforms. These agents filter, prioritize, and synthesize information retrieved from the platforms' back-end databases or via web search. In these scenarios, LLM agents govern the information users receive, by drawing users' attention to particular instances of retrieved information at the expense of others. While much prior work has focused on biases in the information LLMs themselves generate, less attention has been paid to the factors that influence what information LLMs select and present to users. We hypothesize that when information is attributed to specific sources (e.g., particular publishers, journals, or platforms), current LLMs exhibit systematic latent source preferences- that is, they prioritize information from some sources over others. Through controlled experiments on twelve LLMs from six model providers, spanning both synthetic and real-world tasks, we find that several models consistently exhibit strong and predictable source preferences. These preferences are sensitive to contextual framing, can outweigh the influence of content itself, and persist despite explicit prompting to avoid them. They also help explain phenomena such as the observed left-leaning skew in news recommendations in prior work. Our findings advocate for deeper investigation into the origins of these preferences, as well as for mechanisms that provide users with transparency and control over the biases guiding LLM-powered agents.
Rote Learning Considered Useful: Generalizing over Memorized Data in LLMs
Jul 29, 2025Rote learning is a memorization technique based on repetition. It is commonly believed to hinder generalization by encouraging verbatim memorization rather than deeper understanding. This insight holds for even learning factual knowledge that inevitably requires a certain degree of memorization. In this work, we demonstrate that LLMs can be trained to generalize from rote memorized data. We introduce a two-phase memorize-then-generalize framework, where the model first rote memorizes factual subject-object associations using a semantically meaningless token and then learns to generalize by fine-tuning on a small set of semantically meaningful prompts. Extensive experiments over 8 LLMs show that the models can reinterpret rote memorized data through the semantically meaningful prompts, as evidenced by the emergence of structured, semantically aligned latent representations between the two. This surprising finding opens the door to both effective and efficient knowledge injection and possible risks of repurposing the memorized data for malicious usage.
Revisiting Privacy, Utility, and Efficiency Trade-offs when Fine-Tuning Large Language Models
Feb 18, 2025We study the inherent trade-offs in minimizing privacy risks and maximizing utility, while maintaining high computational efficiency, when fine-tuning large language models (LLMs). A number of recent works in privacy research have attempted to mitigate privacy risks posed by memorizing fine-tuning data by using differentially private training methods (e.g., DP), albeit at a significantly higher computational cost (inefficiency). In parallel, several works in systems research have focussed on developing (parameter) efficient fine-tuning methods (e.g., LoRA), but few works, if any, investigated whether such efficient methods enhance or diminish privacy risks. In this paper, we investigate this gap and arrive at a surprising conclusion: efficient fine-tuning methods like LoRA mitigate privacy risks similar to private fine-tuning methods like DP. Our empirical finding directly contradicts prevailing wisdom that privacy and efficiency objectives are at odds during fine-tuning. Our finding is established by (a) carefully defining measures of privacy and utility that distinguish between memorizing sensitive and non-sensitive tokens in training and test datasets used in fine-tuning and (b) extensive evaluations using multiple open-source language models from Pythia, Gemma, and Llama families and different domain-specific datasets.
Logical Consistency of Large Language Models in Fact-checking
Dec 20, 2024In recent years, large language models (LLMs) have demonstrated significant success in performing varied natural language tasks such as language translation, question-answering, summarizing, fact-checking, etc. Despite LLMs' impressive ability to generate human-like texts, LLMs are infamous for their inconsistent responses -- a meaning-preserving change in the input query results in an inconsistent response and attributes to vulnerabilities of LLMs such as hallucination, jailbreaking, etc. Consequently, existing research focuses on simple paraphrasing-based consistency assessment of LLMs, and ignores complex queries that necessitates an even better understanding of logical reasoning by an LLM. Our work therefore addresses the logical inconsistency of LLMs under complex logical queries with primitive logical operators, e.g., negation, conjunction, and disjunction. As a test bed, we consider retrieval-augmented LLMs on a fact-checking task involving propositional logic queries from real-world knowledge graphs (KGs). Our contributions are three-fold. Benchmark: We introduce three logical fact-checking datasets over KGs for community development towards logically consistent LLMs. Assessment: We propose consistency measures of LLMs on propositional logic queries as input and demonstrate that existing LLMs lack logical consistency, specially on complex queries. Improvement: We employ supervised fine-tuning to improve the logical consistency of LLMs on the complex fact-checking task with KG contexts.
Active Fourier Auditor for Estimating Distributional Properties of ML Models
Oct 10, 2024



With the pervasive deployment of Machine Learning (ML) models in real-world applications, verifying and auditing properties of ML models have become a central concern. In this work, we focus on three properties: robustness, individual fairness, and group fairness. We discuss two approaches for auditing ML model properties: estimation with and without reconstruction of the target model under audit. Though the first approach is studied in the literature, the second approach remains unexplored. For this purpose, we develop a new framework that quantifies different properties in terms of the Fourier coefficients of the ML model under audit but does not parametrically reconstruct it. We propose the Active Fourier Auditor (AFA), which queries sample points according to the Fourier coefficients of the ML model, and further estimates the properties. We derive high probability error bounds on AFA's estimates, along with the worst-case lower bounds on the sample complexity to audit them. Numerically we demonstrate on multiple datasets and models that AFA is more accurate and sample-efficient to estimate the properties of interest than the baselines.
Understanding Memorisation in LLMs: Dynamics, Influencing Factors, and Implications
Jul 27, 2024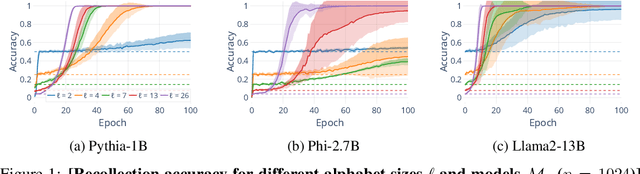
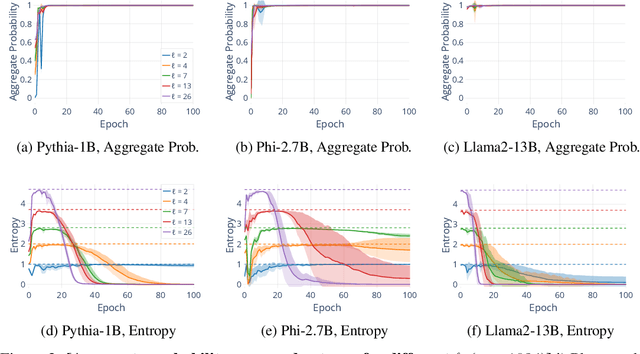
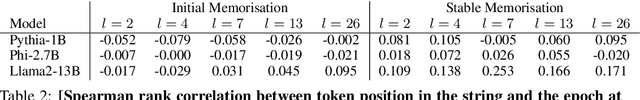
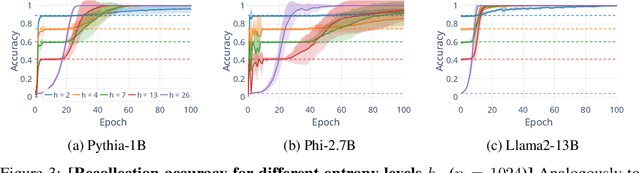
Understanding whether and to what extent large language models (LLMs) have memorised training data has important implications for the reliability of their output and the privacy of their training data. In order to cleanly measure and disentangle memorisation from other phenomena (e.g. in-context learning), we create an experimental framework that is based on repeatedly exposing LLMs to random strings. Our framework allows us to better understand the dynamics, i.e., the behaviour of the model, when repeatedly exposing it to random strings. Using our framework, we make several striking observations: (a) we find consistent phases of the dynamics across families of models (Pythia, Phi and Llama2), (b) we identify factors that make some strings easier to memorise than others, and (c) we identify the role of local prefixes and global context in memorisation. We also show that sequential exposition to different random strings has a significant effect on memorisation. Our results, often surprising, have significant downstream implications in the study and usage of LLMs.
Towards Reliable Latent Knowledge Estimation in LLMs: In-Context Learning vs. Prompting Based Factual Knowledge Extraction
Apr 19, 2024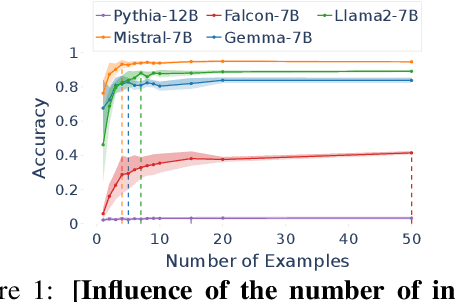
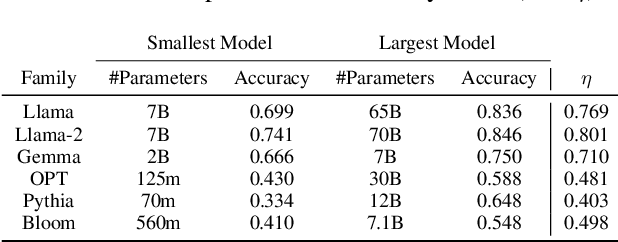
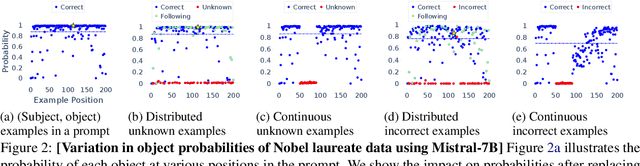
We propose an approach for estimating the latent knowledge embedded inside large language models (LLMs). We leverage the in-context learning (ICL) abilities of LLMs to estimate the extent to which an LLM knows the facts stored in a knowledge base. Our knowledge estimator avoids reliability concerns with previous prompting-based methods, is both conceptually simpler and easier to apply, and we demonstrate that it can surface more of the latent knowledge embedded in LLMs. We also investigate how different design choices affect the performance of ICL-based knowledge estimation. Using the proposed estimator, we perform a large-scale evaluation of the factual knowledge of a variety of open source LLMs, like OPT, Pythia, Llama(2), Mistral, Gemma, etc. over a large set of relations and facts from the Wikidata knowledge base. We observe differences in the factual knowledge between different model families and models of different sizes, that some relations are consistently better known than others but that models differ in the precise facts they know, and differences in the knowledge of base models and their finetuned counterparts.
Don't Forget What I did?: Assessing Client Contributions in Federated Learning
Mar 11, 2024



Federated Learning (FL) is a collaborative machine learning (ML) approach, where multiple clients participate in training an ML model without exposing the private data. Fair and accurate assessment of client contributions is an important problem in FL to facilitate incentive allocation and encouraging diverse clients to participate in a unified model training. Existing methods for assessing client contribution adopts co-operative game-theoretic concepts, such as Shapley values, but under simplified assumptions. In this paper, we propose a history-aware game-theoretic framework, called FLContrib, to assess client contributions when a subset of (potentially non-i.i.d.) clients participate in each epoch of FL training. By exploiting the FL training process and linearity of Shapley value, we develop FLContrib that yields a historical timeline of client contributions as FL training progresses over epochs. Additionally, to assess client contribution under limited computational budget, we propose a scheduling procedure that considers a two-sided fairness criteria to perform expensive Shapley value computation only in a subset of training epochs. In experiments, we demonstrate a controlled trade-off between the correctness and efficiency of client contributions assessed via FLContrib. To demonstrate the benefits of history-aware client contributions, we apply FLContrib to detect dishonest clients conducting data poisoning in FL training.
How Biased is Your Feature?: Computing Fairness Influence Functions with Global Sensitivity Analysis
Jun 01, 2022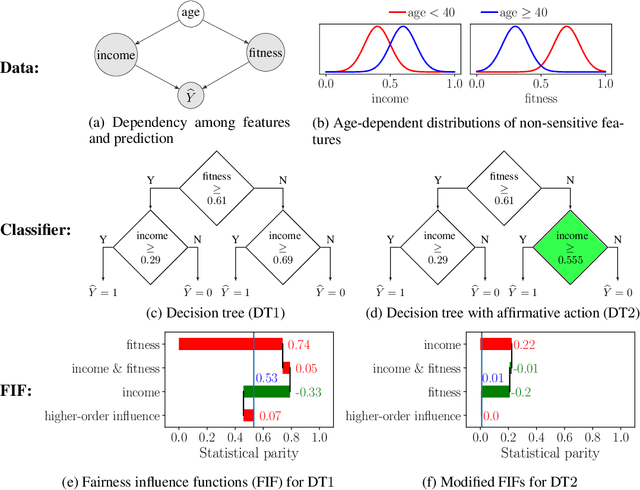
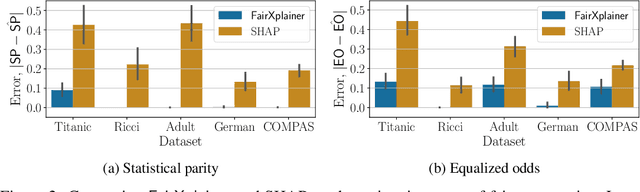

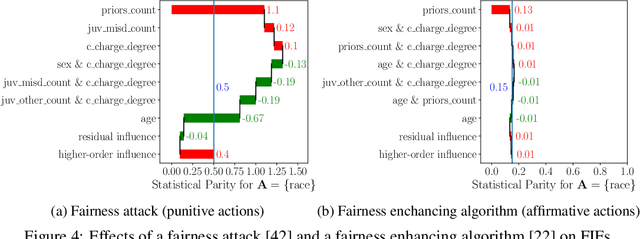
Fairness in machine learning has attained significant focus due to the widespread application of machine learning in high-stake decision-making tasks. Unless regulated with a fairness objective, machine learning classifiers might demonstrate unfairness/bias towards certain demographic populations in the data. Thus, the quantification and mitigation of the bias induced by classifiers have become a central concern. In this paper, we aim to quantify the influence of different features on the bias of a classifier. To this end, we propose a framework of Fairness Influence Function (FIF), and compute it as a scaled difference of conditional variances in the prediction of the classifier. We also instantiate an algorithm, FairXplainer, that uses variance decomposition among the subset of features and a local regressor to compute FIFs accurately, while also capturing the intersectional effects of the features. Our experimental analysis validates that FairXplainer captures the influences of both individual features and higher-order feature interactions, estimates the bias more accurately than existing local explanation methods, and detects the increase/decrease in bias due to affirmative/punitive actions in the classifier.