 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrappa: Gradient-Only Communication for Scalable Graph Neural Network Training
Feb 02, 2026Cross-partition edges dominate the cost of distributed GNN training: fetching remote features and activations per iteration overwhelms the network as graphs deepen and partition counts grow. Grappa is a distributed GNN training framework that enforces gradient-only communication: during each iteration, partitions train in isolation and exchange only gradients for the global update. To recover accuracy lost to isolation, Grappa (i) periodically repartitions to expose new neighborhoods and (ii) applies a lightweight coverage-corrected gradient aggregation inspired by importance sampling. We prove the corrected estimator is asymptotically unbiased under standard support and boundedness assumptions, and we derive a batch-level variant for compatibility with common deep-learning packages that minimizes mean-squared deviation from the ideal node-level correction. We also introduce a shrinkage version that improves stability in practice. Empirical results on real and synthetic graphs show that Grappa trains GNNs 4 times faster on average (up to 13 times) than state-of-the-art systems, achieves better accuracy especially for deeper models, and sustains training at the trillion-edge scale on commodity hardware. Grappa is model-agnostic, supports full-graph and mini-batch training, and does not rely on high-bandwidth interconnects or caching.
LoRACode: LoRA Adapters for Code Embeddings
Mar 07, 2025



Code embeddings are essential for semantic code search; however, current approaches often struggle to capture the precise syntactic and contextual nuances inherent in code. Open-source models such as CodeBERT and UniXcoder exhibit limitations in scalability and efficiency, while high-performing proprietary systems impose substantial computational costs. We introduce a parameter-efficient fine-tuning method based on Low-Rank Adaptation (LoRA) to construct task-specific adapters for code retrieval. Our approach reduces the number of trainable parameters to less than two percent of the base model, enabling rapid fine-tuning on extensive code corpora (2 million samples in 25 minutes on two H100 GPUs). Experiments demonstrate an increase of up to 9.1% in Mean Reciprocal Rank (MRR) for Code2Code search, and up to 86.69% for Text2Code search tasks across multiple programming languages. Distinction in task-wise and language-wise adaptation helps explore the sensitivity of code retrieval for syntactical and linguistic variations.
Towards Reliable Latent Knowledge Estimation in LLMs: In-Context Learning vs. Prompting Based Factual Knowledge Extraction
Apr 19, 2024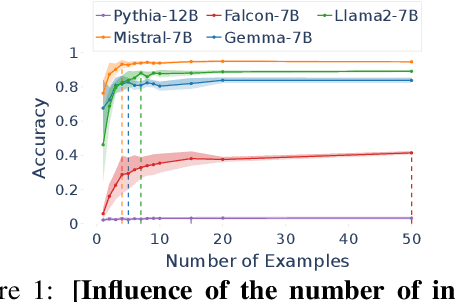
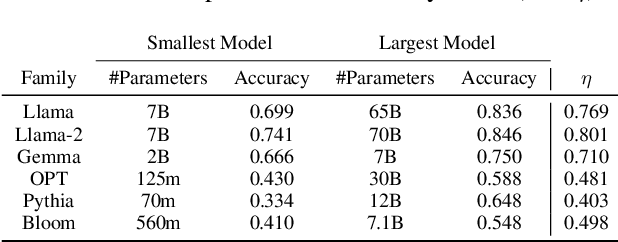
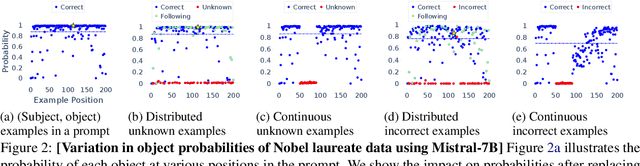
We propose an approach for estimating the latent knowledge embedded inside large language models (LLMs). We leverage the in-context learning (ICL) abilities of LLMs to estimate the extent to which an LLM knows the facts stored in a knowledge base. Our knowledge estimator avoids reliability concerns with previous prompting-based methods, is both conceptually simpler and easier to apply, and we demonstrate that it can surface more of the latent knowledge embedded in LLMs. We also investigate how different design choices affect the performance of ICL-based knowledge estimation. Using the proposed estimator, we perform a large-scale evaluation of the factual knowledge of a variety of open source LLMs, like OPT, Pythia, Llama(2), Mistral, Gemma, etc. over a large set of relations and facts from the Wikidata knowledge base. We observe differences in the factual knowledge between different model families and models of different sizes, that some relations are consistently better known than others but that models differ in the precise facts they know, and differences in the knowledge of base models and their finetuned counterparts.