 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Algorithmic Self-Portrait: Deconstructing Memory in ChatGPT
Feb 03, 2026To enable personalized and context-aware interactions, conversational AI systems have introduced a new mechanism: Memory. Memory creates what we refer to as the Algorithmic Self-portrait - a new form of personalization derived from users' self-disclosed information divulged within private conversations. While memory enables more coherent exchanges, the underlying processes of memory creation remain opaque, raising critical questions about data sensitivity, user agency, and the fidelity of the resulting portrait. To bridge this research gap, we analyze 2,050 memory entries from 80 real-world ChatGPT users. Our analyses reveal three key findings: (1) A striking 96% of memories in our dataset are created unilaterally by the conversational system, potentially shifting agency away from the user; (2) Memories, in our dataset, contain a rich mix of GDPR-defined personal data (in 28% memories) along with psychological insights about participants (in 52% memories); and (3)~A significant majority of the memories (84%) are directly grounded in user context, indicating faithful representation of the conversations. Finally, we introduce a framework-Attribution Shield-that anticipates these inferences, alerts about potentially sensitive memory inferences, and suggests query reformulations to protect personal information without sacrificing utility.
LoRA on the Go: Instance-level Dynamic LoRA Selection and Merging
Nov 10, 2025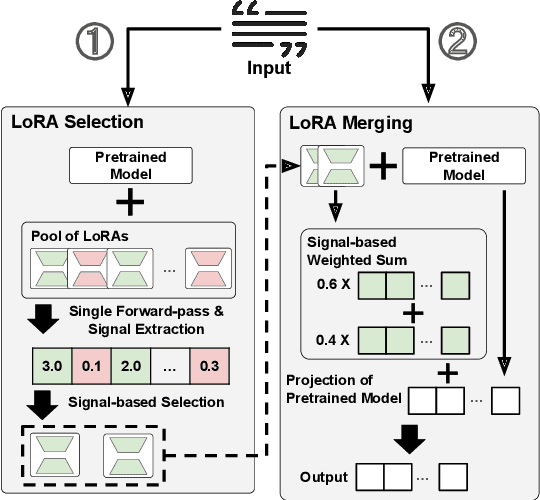
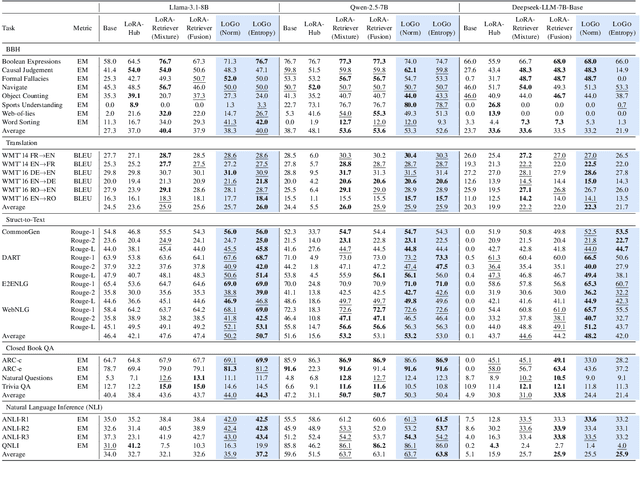
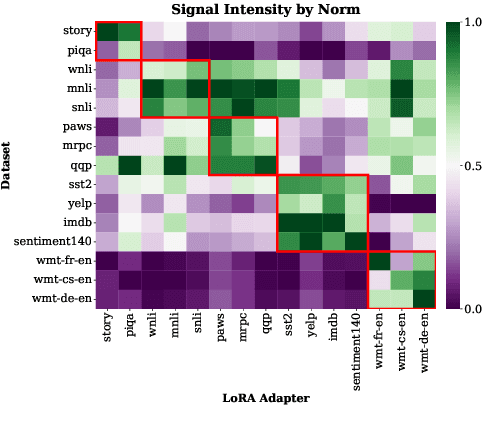
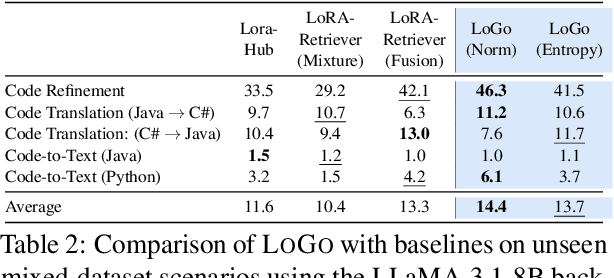
Low-Rank Adaptation (LoRA) has emerged as a parameter-efficient approach for fine-tuning large language models.However, conventional LoRA adapters are typically trained for a single task, limiting their applicability in real-world settings where inputs may span diverse and unpredictable domains. At inference time, existing approaches combine multiple LoRAs for improving performance on diverse tasks, while usually requiring labeled data or additional task-specific training, which is expensive at scale. In this work, we introduce LoRA on the Go (LoGo), a training-free framework that dynamically selects and merges adapters at the instance level without any additional requirements. LoGo leverages signals extracted from a single forward pass through LoRA adapters, to identify the most relevant adapters and determine their contributions on-the-fly. Across 5 NLP benchmarks, 27 datasets, and 3 model families, LoGo outperforms training-based baselines on some tasks upto a margin of 3.6% while remaining competitive on other tasks and maintaining inference throughput, highlighting its effectiveness and practicality.
Rote Learning Considered Useful: Generalizing over Memorized Data in LLMs
Jul 29, 2025Rote learning is a memorization technique based on repetition. It is commonly believed to hinder generalization by encouraging verbatim memorization rather than deeper understanding. This insight holds for even learning factual knowledge that inevitably requires a certain degree of memorization. In this work, we demonstrate that LLMs can be trained to generalize from rote memorized data. We introduce a two-phase memorize-then-generalize framework, where the model first rote memorizes factual subject-object associations using a semantically meaningless token and then learns to generalize by fine-tuning on a small set of semantically meaningful prompts. Extensive experiments over 8 LLMs show that the models can reinterpret rote memorized data through the semantically meaningful prompts, as evidenced by the emergence of structured, semantically aligned latent representations between the two. This surprising finding opens the door to both effective and efficient knowledge injection and possible risks of repurposing the memorized data for malicious usage.
Revisiting Privacy, Utility, and Efficiency Trade-offs when Fine-Tuning Large Language Models
Feb 18, 2025We study the inherent trade-offs in minimizing privacy risks and maximizing utility, while maintaining high computational efficiency, when fine-tuning large language models (LLMs). A number of recent works in privacy research have attempted to mitigate privacy risks posed by memorizing fine-tuning data by using differentially private training methods (e.g., DP), albeit at a significantly higher computational cost (inefficiency). In parallel, several works in systems research have focussed on developing (parameter) efficient fine-tuning methods (e.g., LoRA), but few works, if any, investigated whether such efficient methods enhance or diminish privacy risks. In this paper, we investigate this gap and arrive at a surprising conclusion: efficient fine-tuning methods like LoRA mitigate privacy risks similar to private fine-tuning methods like DP. Our empirical finding directly contradicts prevailing wisdom that privacy and efficiency objectives are at odds during fine-tuning. Our finding is established by (a) carefully defining measures of privacy and utility that distinguish between memorizing sensitive and non-sensitive tokens in training and test datasets used in fine-tuning and (b) extensive evaluations using multiple open-source language models from Pythia, Gemma, and Llama families and different domain-specific datasets.
Understanding Memorisation in LLMs: Dynamics, Influencing Factors, and Implications
Jul 27, 2024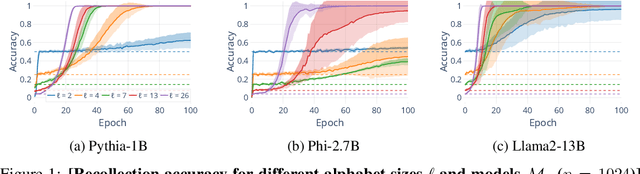
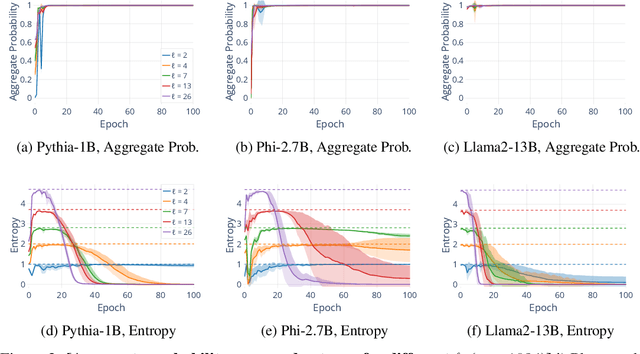
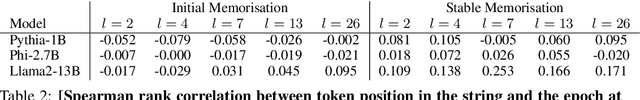
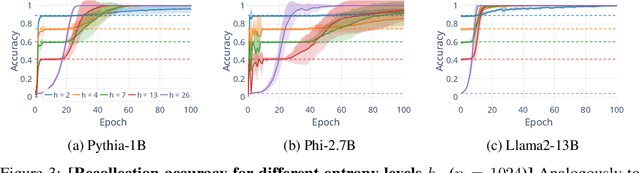
Understanding whether and to what extent large language models (LLMs) have memorised training data has important implications for the reliability of their output and the privacy of their training data. In order to cleanly measure and disentangle memorisation from other phenomena (e.g. in-context learning), we create an experimental framework that is based on repeatedly exposing LLMs to random strings. Our framework allows us to better understand the dynamics, i.e., the behaviour of the model, when repeatedly exposing it to random strings. Using our framework, we make several striking observations: (a) we find consistent phases of the dynamics across families of models (Pythia, Phi and Llama2), (b) we identify factors that make some strings easier to memorise than others, and (c) we identify the role of local prefixes and global context in memorisation. We also show that sequential exposition to different random strings has a significant effect on memorisation. Our results, often surprising, have significant downstream implications in the study and usage of LLMs.
Towards Reliable Latent Knowledge Estimation in LLMs: In-Context Learning vs. Prompting Based Factual Knowledge Extraction
Apr 19, 2024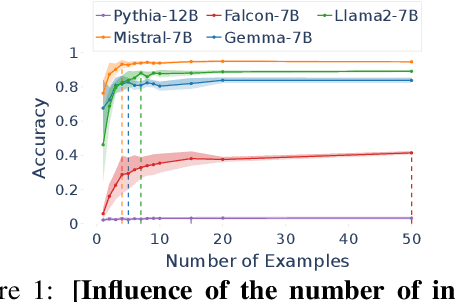
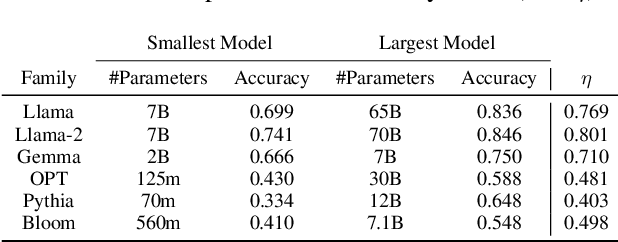
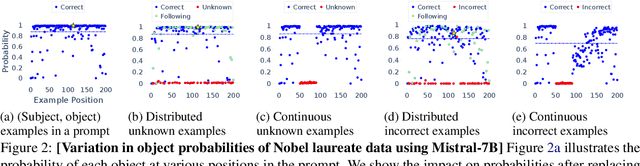
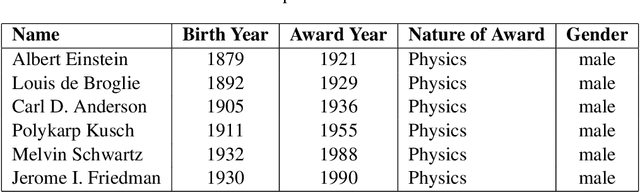
We propose an approach for estimating the latent knowledge embedded inside large language models (LLMs). We leverage the in-context learning (ICL) abilities of LLMs to estimate the extent to which an LLM knows the facts stored in a knowledge base. Our knowledge estimator avoids reliability concerns with previous prompting-based methods, is both conceptually simpler and easier to apply, and we demonstrate that it can surface more of the latent knowledge embedded in LLMs. We also investigate how different design choices affect the performance of ICL-based knowledge estimation. Using the proposed estimator, we perform a large-scale evaluation of the factual knowledge of a variety of open source LLMs, like OPT, Pythia, Llama(2), Mistral, Gemma, etc. over a large set of relations and facts from the Wikidata knowledge base. We observe differences in the factual knowledge between different model families and models of different sizes, that some relations are consistently better known than others but that models differ in the precise facts they know, and differences in the knowledge of base models and their finetuned counterparts.
VTruST: Controllable value function based subset selection for Data-Centric Trustworthy AI
Mar 08, 2024
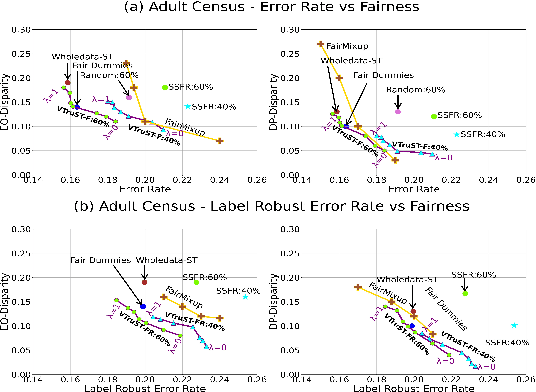
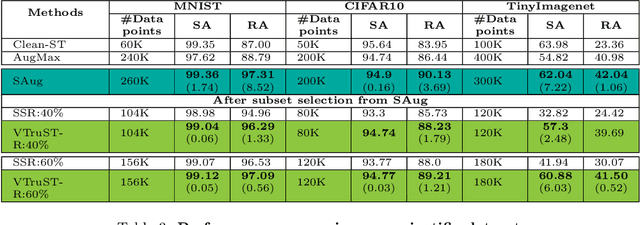
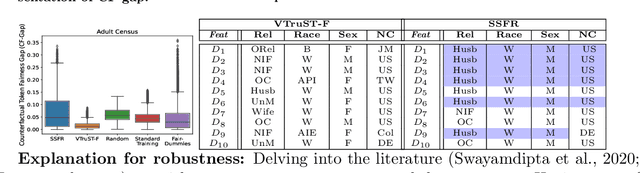
Trustworthy AI is crucial to the widespread adoption of AI in high-stakes applications with fairness, robustness, and accuracy being some of the key trustworthiness metrics. In this work, we propose a controllable framework for data-centric trustworthy AI (DCTAI)- VTruST, that allows users to control the trade-offs between the different trustworthiness metrics of the constructed training datasets. A key challenge in implementing an efficient DCTAI framework is to design an online value-function-based training data subset selection algorithm. We pose the training data valuation and subset selection problem as an online sparse approximation formulation. We propose a novel online version of the Orthogonal Matching Pursuit (OMP) algorithm for solving this problem. Experimental results show that VTruST outperforms the state-of-the-art baselines on social, image, and scientific datasets. We also show that the data values generated by VTruST can provide effective data-centric explanations for different trustworthiness metrics.
LearnDefend: Learning to Defend against Targeted Model-Poisoning Attacks on Federated Learning
May 03, 2023



Targeted model poisoning attacks pose a significant threat to federated learning systems. Recent studies show that edge-case targeted attacks, which target a small fraction of the input space are nearly impossible to counter using existing fixed defense strategies. In this paper, we strive to design a learned-defense strategy against such attacks, using a small defense dataset. The defense dataset can be collected by the central authority of the federated learning task, and should contain a mix of poisoned and clean examples. The proposed framework, LearnDefend, estimates the probability of a client update being malicious. The examples in defense dataset need not be pre-marked as poisoned or clean. We also learn a poisoned data detector model which can be used to mark each example in the defense dataset as clean or poisoned. We estimate the poisoned data detector and the client importance models in a coupled optimization approach. Our experiments demonstrate that LearnDefend is capable of defending against state-of-the-art attacks where existing fixed defense strategies fail. We also show that LearnDefend is robust to size and noise in the marking of clean examples in the defense dataset.
CheckSel: Efficient and Accurate Data-valuation Through Online Checkpoint Selection
Mar 14, 2022



Data valuation and subset selection have emerged as valuable tools for application-specific selection of important training data. However, the efficiency-accuracy tradeoffs of state-of-the-art methods hinder their widespread application to many AI workflows. In this paper, we propose a novel 2-phase solution to this problem. Phase 1 selects representative checkpoints from an SGD-like training algorithm, which are used in phase-2 to estimate the approximate training data values, e.g. decrease in validation loss due to each training point. A key contribution of this paper is CheckSel, an Orthogonal Matching Pursuit-inspired online sparse approximation algorithm for checkpoint selection in the online setting, where the features are revealed one at a time. Another key contribution is the study of data valuation in the domain adaptation setting, where a data value estimator obtained using checkpoints from training trajectory in the source domain training dataset is used for data valuation in a target domain training dataset. Experimental results on benchmark datasets show the proposed algorithm outperforms recent baseline methods by up to 30% in terms of test accuracy while incurring a similar computational burden, for both standalone and domain adaptation settings.
Finding High-Value Training Data Subset through Differentiable Convex Programming
Apr 28, 2021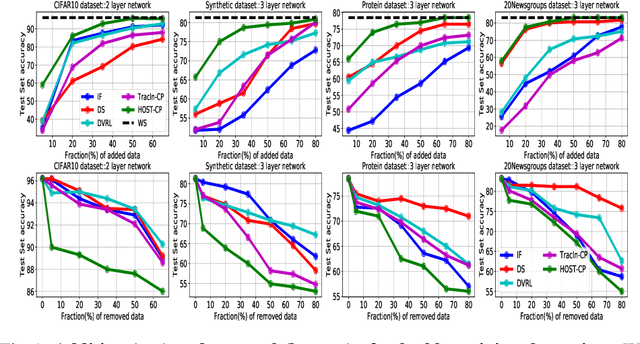

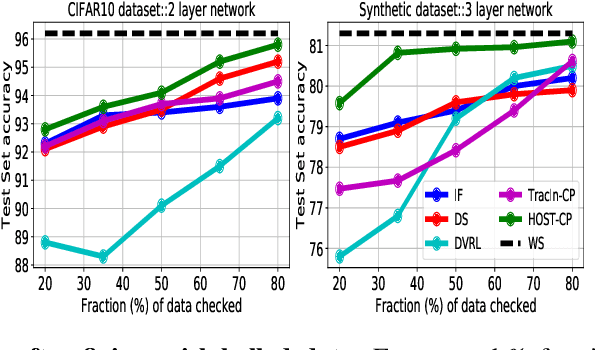
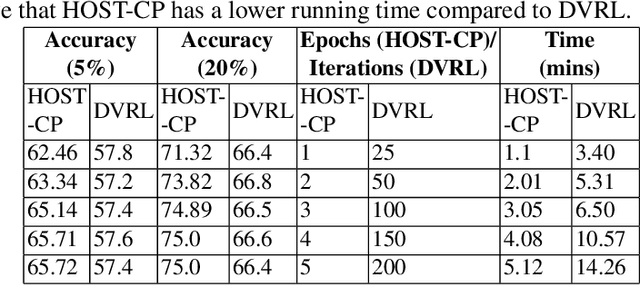
Finding valuable training data points for deep neural networks has been a core research challenge with many applications. In recent years, various techniques for calculating the "value" of individual training datapoints have been proposed for explaining trained models. However, the value of a training datapoint also depends on other selected training datapoints - a notion that is not explicitly captured by existing methods. In this paper, we study the problem of selecting high-value subsets of training data. The key idea is to design a learnable framework for online subset selection, which can be learned using mini-batches of training data, thus making our method scalable. This results in a parameterized convex subset selection problem that is amenable to a differentiable convex programming paradigm, thus allowing us to learn the parameters of the selection model in end-to-end training. Using this framework, we design an online alternating minimization-based algorithm for jointly learning the parameters of the selection model and ML model. Extensive evaluation on a synthetic dataset, and three standard datasets, show that our algorithm finds consistently higher value subsets of training data, compared to the recent state-of-the-art methods, sometimes ~20% higher value than existing methods. The subsets are also useful in finding mislabelled training data. Our algorithm takes running time comparable to the existing valuation functions.