 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning vs. In-context Learning in Large Language Models: A Formal Language Learning Perspective
Apr 25, 2026Large language models (LLMs) operate in two fundamental learning modes - fine-tuning (FT) and in-context learning (ICL) - raising key questions about which mode yields greater language proficiency and whether they differ in their inductive biases. Prior studies comparing FT and ICL have yielded mixed and inconclusive results due to inconsistent experimental setups. To enable a rigorous comparison, we propose a formal language learning task - offering precise language boundaries, controlled string sampling, and no data contamination - and introduce a discriminative test for language proficiency, where an LLM succeeds if it assigns higher generation probability to in-language strings than to out-of-language strings. Empirically, we find that: (a) FT has greater language proficiency than ICL on in-distribution generalization, but both perform equally well on out-of-distribution generalization. (b) Their inductive biases, measured by the correlation in string generation probabilities, are similar when both modes partially learn the language but diverge at higher proficiency levels. (c) Unlike FT, ICL performance differs substantially across models of varying sizes and families and is sensitive to the token vocabulary of the language. Thus, our work demonstrates the promise of formal languages as a controlled testbed for evaluating LLMs, behaviors that are difficult to isolate in natural language datasets. Our source code is available at https://github.com/bishwamittra/formallm.
Testing the Limits of Truth Directions in LLMs
Apr 04, 2026Large language models (LLMs) have been shown to encode truth of statements in their activation space along a linear truth direction. Previous studies have argued that these directions are universal in certain aspects, while more recent work has questioned this conclusion drawing on limited generalization across some settings. In this work, we identify a number of limits of truth-direction universality that have not been previously understood. We first show that truth directions are highly layer-dependent, and that a full understanding of universality requires probing at many layers in the model. We then show that truth directions depend heavily on task type, emerging in earlier layers for factual and later layers for reasoning tasks; they also vary in performance across levels of task complexity. Finally, we show that model instructions dramatically affect truth directions; simple correctness evaluation instructions significantly affect the generalization ability of truth probes. Our findings indicate that universality claims for truth directions are more limited than previously known, with significant differences observable for various model layers, task difficulties, task types, and prompt templates.
A QUBO Framework for Team Formation
Mar 29, 2025The team formation problem assumes a set of experts and a task, where each expert has a set of skills and the task requires some skills. The objective is to find a set of experts that maximizes coverage of the required skills while simultaneously minimizing the costs associated with the experts. Different definitions of cost have traditionally led to distinct problem formulations and algorithmic solutions. We introduce the unified TeamFormation formulation that captures all cost definitions for team formation problems that balance task coverage and expert cost. Specifically, we formulate three TeamFormation variants with different cost functions using quadratic unconstrained binary optimization (QUBO), and we evaluate two distinct general-purpose solution methods. We show that solutions based on the QUBO formulations of TeamFormation problems are at least as good as those produced by established baselines. Furthermore, we show that QUBO-based solutions leveraging graph neural networks can effectively learn representations of experts and skills to enable transfer learning, allowing node embeddings from one problem instance to be efficiently applied to another.
FGCE: Feasible Group Counterfactual Explanations for Auditing Fairness
Oct 29, 2024



This paper introduces the first graph-based framework for generating group counterfactual explanations to audit model fairness, a crucial aspect of trustworthy machine learning. Counterfactual explanations are instrumental in understanding and mitigating unfairness by revealing how inputs should change to achieve a desired outcome. Our framework, named Feasible Group Counterfactual Explanations (FGCEs), captures real-world feasibility constraints and constructs subgroups with similar counterfactuals, setting it apart from existing methods. It also addresses key trade-offs in counterfactual generation, including the balance between the number of counterfactuals, their associated costs, and the breadth of coverage achieved. To evaluate these trade-offs and assess fairness, we propose measures tailored to group counterfactual generation. Our experimental results on benchmark datasets demonstrate the effectiveness of our approach in managing feasibility constraints and trade-offs, as well as the potential of our proposed metrics in identifying and quantifying fairness issues.
Understanding Memorisation in LLMs: Dynamics, Influencing Factors, and Implications
Jul 27, 2024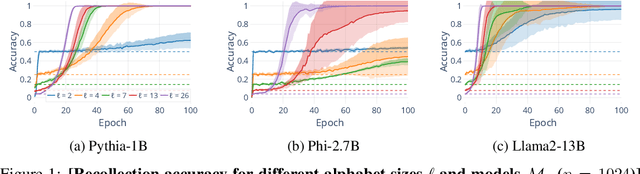
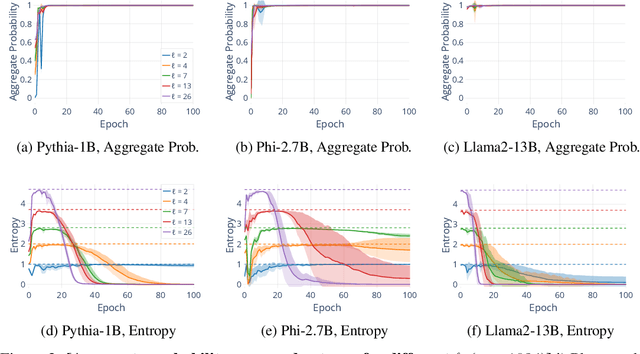
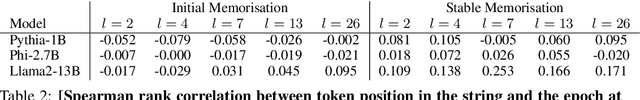
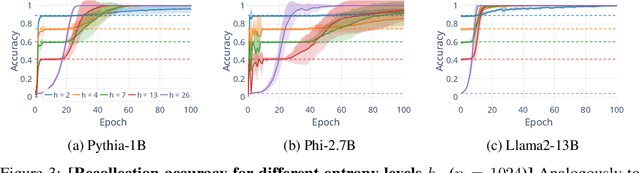
Understanding whether and to what extent large language models (LLMs) have memorised training data has important implications for the reliability of their output and the privacy of their training data. In order to cleanly measure and disentangle memorisation from other phenomena (e.g. in-context learning), we create an experimental framework that is based on repeatedly exposing LLMs to random strings. Our framework allows us to better understand the dynamics, i.e., the behaviour of the model, when repeatedly exposing it to random strings. Using our framework, we make several striking observations: (a) we find consistent phases of the dynamics across families of models (Pythia, Phi and Llama2), (b) we identify factors that make some strings easier to memorise than others, and (c) we identify the role of local prefixes and global context in memorisation. We also show that sequential exposition to different random strings has a significant effect on memorisation. Our results, often surprising, have significant downstream implications in the study and usage of LLMs.
Towards Reliable Latent Knowledge Estimation in LLMs: In-Context Learning vs. Prompting Based Factual Knowledge Extraction
Apr 19, 2024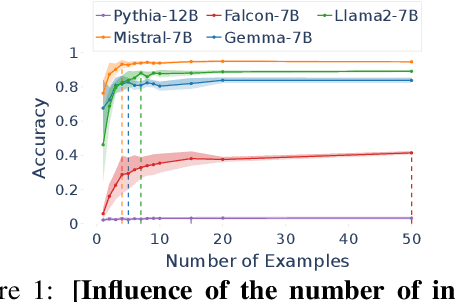
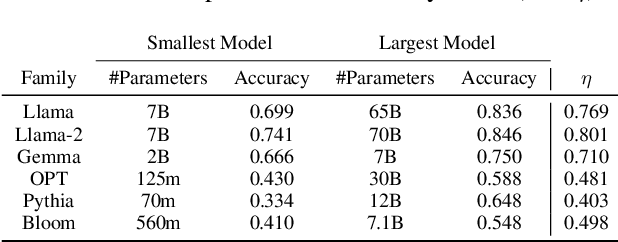
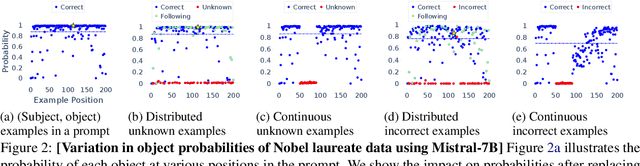
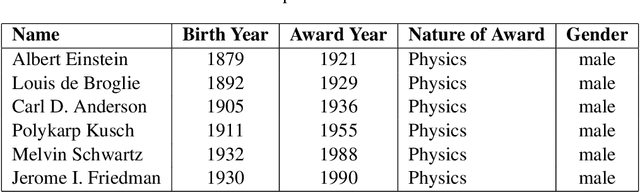
We propose an approach for estimating the latent knowledge embedded inside large language models (LLMs). We leverage the in-context learning (ICL) abilities of LLMs to estimate the extent to which an LLM knows the facts stored in a knowledge base. Our knowledge estimator avoids reliability concerns with previous prompting-based methods, is both conceptually simpler and easier to apply, and we demonstrate that it can surface more of the latent knowledge embedded in LLMs. We also investigate how different design choices affect the performance of ICL-based knowledge estimation. Using the proposed estimator, we perform a large-scale evaluation of the factual knowledge of a variety of open source LLMs, like OPT, Pythia, Llama(2), Mistral, Gemma, etc. over a large set of relations and facts from the Wikidata knowledge base. We observe differences in the factual knowledge between different model families and models of different sizes, that some relations are consistently better known than others but that models differ in the precise facts they know, and differences in the knowledge of base models and their finetuned counterparts.
Team Formation amidst Conflicts
Feb 29, 2024



In this work, we formulate the problem of team formation amidst conflicts. The goal is to assign individuals to tasks, with given capacities, taking into account individuals' task preferences and the conflicts between them. Using dependent rounding schemes as our main toolbox, we provide efficient approximation algorithms. Our framework is extremely versatile and can model many different real-world scenarios as they arise in educational settings and human-resource management. We test and deploy our algorithms on real-world datasets and we show that our algorithms find assignments that are better than those found by natural baselines. In the educational setting we also show how our assignments are far better than those done manually by human experts. In the human resource management application we show how our assignments increase the diversity of teams. Finally, using a synthetic dataset we demonstrate that our algorithms scale very well in practice.
Understanding team collapse via probabilistic graphical models
Feb 14, 2024



In this work, we develop a graphical model to capture team dynamics. We analyze the model and show how to learn its parameters from data. Using our model we study the phenomenon of team collapse from a computational perspective. We use simulations and real-world experiments to find the main causes of team collapse. We also provide the principles of building resilient teams, i.e., teams that avoid collapsing. Finally, we use our model to analyze the structure of NBA teams and dive deeper into games of interest.
Online Submodular Maximization via Online Convex Optimization
Sep 13, 2023



We study monotone submodular maximization under general matroid constraints in the online setting. We prove that online optimization of a large class of submodular functions, namely, weighted threshold potential functions, reduces to online convex optimization (OCO). This is precisely because functions in this class admit a concave relaxation; as a result, OCO policies, coupled with an appropriate rounding scheme, can be used to achieve sublinear regret in the combinatorial setting. We show that our reduction extends to many different versions of the online learning problem, including the dynamic regret, bandit, and optimistic-learning settings.
Finding teams that balance expert load and task coverage
Nov 03, 2020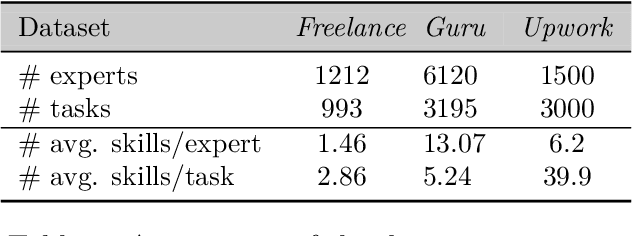
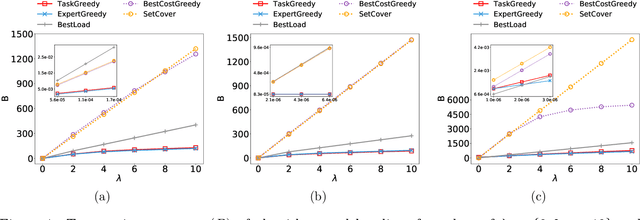
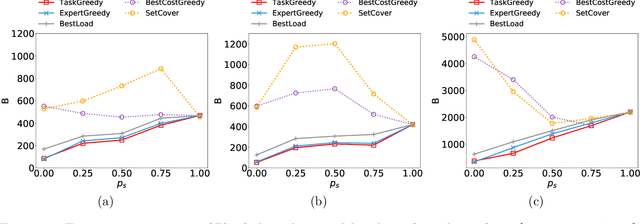
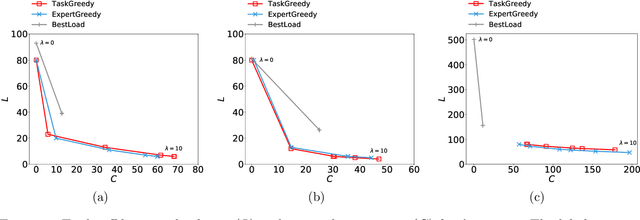
The rise of online labor markets (e.g., Freelancer, Guru and Upwork) has ignited a lot of research on team formation, where experts acquiring different skills form teams to complete tasks. The core idea in this line of work has been the strict requirement that the team of experts assigned to complete a given task should contain a superset of the skills required by the task. However, in many applications the required skills are often a wishlist of the entity that posts the task and not all of the skills are absolutely necessary. Thus, in our setting we relax the complete coverage requirement and we allow for tasks to be partially covered by the formed teams, assuming that the quality of task completion is proportional to the fraction of covered skills per task. At the same time, we assume that when multiple tasks need to be performed, the less the load of an expert the better the performance. We combine these two high-level objectives into one and define the BalancedTA problem. We also consider a generalization of this problem where each task consists of required and optional skills. In this setting, our objective is the same under the constraint that all required skills should be covered. From the technical point of view, we show that the BalancedTA problem (and its variant) is NP-hard and design efficient heuristics for solving it in practice. Using real datasets from three online market places, Freelancer, Guru and Upwork we demonstrate the efficiency of our methods and the practical utility of our framework.