 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Family of LLMs Liberated from Static Vocabularies
Mar 16, 2026Tokenization is a central component of natural language processing in current large language models (LLMs), enabling models to convert raw text into processable units. Although learned tokenizers are widely adopted, they exhibit notable limitations, including their large, fixed vocabulary sizes and poor adaptability to new domains or languages. We present a family of models with up to 70 billion parameters based on the hierarchical autoregressive transformer (HAT) architecture. In HAT, an encoder transformer aggregates bytes into word embeddings and then feeds them to the backbone, a classical autoregressive transformer. The outputs of the backbone are then cross-attended by the decoder and converted back into bytes. We show that we can reuse available pre-trained models by converting the Llama 3.1 8B and 70B models into the HAT architecture: Llama-3.1-8B-TFree-HAT and Llama-3.1-70B-TFree-HAT are byte-level models whose encoder and decoder are trained from scratch, but where we adapt the pre-trained Llama backbone, i.e., the transformer blocks with the embedding matrix and head removed, to handle word embeddings instead of the original tokens. We also provide a 7B HAT model, Llama-TFree-HAT-Pretrained, trained entirely from scratch on nearly 4 trillion words. The HAT architecture improves text compression by reducing the number of required sequence positions and enhances robustness to intra-word variations, e.g., spelling differences. Through pre-training, as well as subsequent supervised fine-tuning and direct preference optimization in English and German, we show strong proficiency in both languages, improving on the original Llama 3.1 in most benchmarks. We release our models (including 200 pre-training checkpoints) on Hugging Face.
Revisiting Privacy, Utility, and Efficiency Trade-offs when Fine-Tuning Large Language Models
Feb 18, 2025We study the inherent trade-offs in minimizing privacy risks and maximizing utility, while maintaining high computational efficiency, when fine-tuning large language models (LLMs). A number of recent works in privacy research have attempted to mitigate privacy risks posed by memorizing fine-tuning data by using differentially private training methods (e.g., DP), albeit at a significantly higher computational cost (inefficiency). In parallel, several works in systems research have focussed on developing (parameter) efficient fine-tuning methods (e.g., LoRA), but few works, if any, investigated whether such efficient methods enhance or diminish privacy risks. In this paper, we investigate this gap and arrive at a surprising conclusion: efficient fine-tuning methods like LoRA mitigate privacy risks similar to private fine-tuning methods like DP. Our empirical finding directly contradicts prevailing wisdom that privacy and efficiency objectives are at odds during fine-tuning. Our finding is established by (a) carefully defining measures of privacy and utility that distinguish between memorizing sensitive and non-sensitive tokens in training and test datasets used in fine-tuning and (b) extensive evaluations using multiple open-source language models from Pythia, Gemma, and Llama families and different domain-specific datasets.
Understanding Memorisation in LLMs: Dynamics, Influencing Factors, and Implications
Jul 27, 2024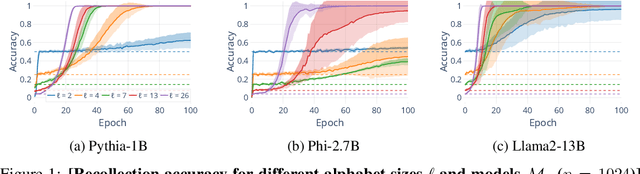
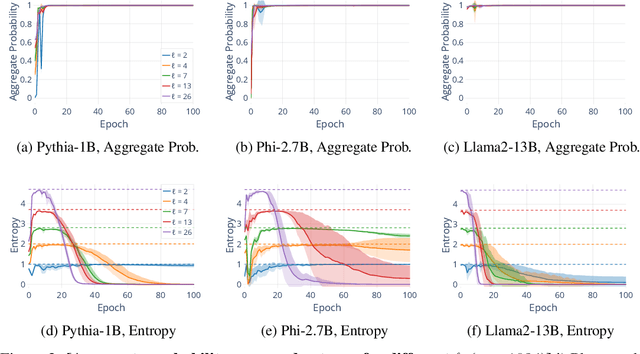
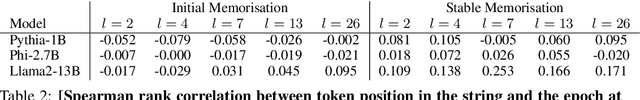
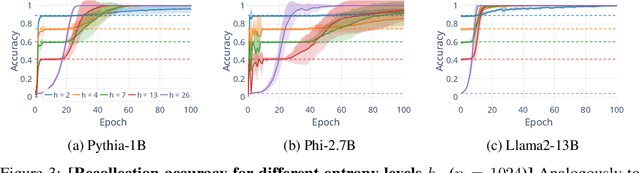
Understanding whether and to what extent large language models (LLMs) have memorised training data has important implications for the reliability of their output and the privacy of their training data. In order to cleanly measure and disentangle memorisation from other phenomena (e.g. in-context learning), we create an experimental framework that is based on repeatedly exposing LLMs to random strings. Our framework allows us to better understand the dynamics, i.e., the behaviour of the model, when repeatedly exposing it to random strings. Using our framework, we make several striking observations: (a) we find consistent phases of the dynamics across families of models (Pythia, Phi and Llama2), (b) we identify factors that make some strings easier to memorise than others, and (c) we identify the role of local prefixes and global context in memorisation. We also show that sequential exposition to different random strings has a significant effect on memorisation. Our results, often surprising, have significant downstream implications in the study and usage of LLMs.
Understanding the Role of Invariance in Transfer Learning
Jul 05, 2024Transfer learning is a powerful technique for knowledge-sharing between different tasks. Recent work has found that the representations of models with certain invariances, such as to adversarial input perturbations, achieve higher performance on downstream tasks. These findings suggest that invariance may be an important property in the context of transfer learning. However, the relationship of invariance with transfer performance is not fully understood yet and a number of questions remain. For instance, how important is invariance compared to other factors of the pretraining task? How transferable is learned invariance? In this work, we systematically investigate the importance of representational invariance for transfer learning, as well as how it interacts with other parameters during pretraining. To do so, we introduce a family of synthetic datasets that allow us to precisely control factors of variation both in training and test data. Using these datasets, we a) show that for learning representations with high transfer performance, invariance to the right transformations is as, or often more, important than most other factors such as the number of training samples, the model architecture and the identity of the pretraining classes, b) show conditions under which invariance can harm the ability to transfer representations and c) explore how transferable invariance is between tasks. The code is available at \url{https://github.com/tillspeicher/representation-invariance-transfer}.
Towards Reliable Latent Knowledge Estimation in LLMs: In-Context Learning vs. Prompting Based Factual Knowledge Extraction
Apr 19, 2024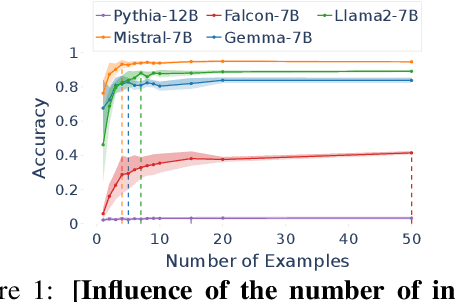
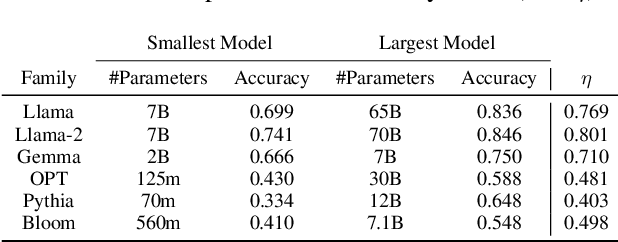
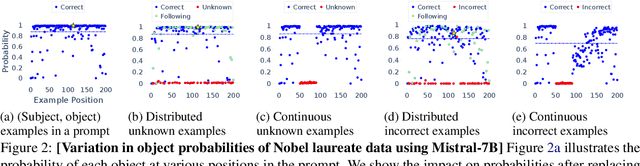
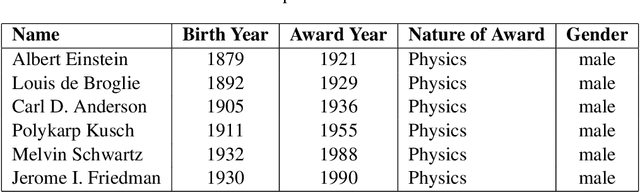
We propose an approach for estimating the latent knowledge embedded inside large language models (LLMs). We leverage the in-context learning (ICL) abilities of LLMs to estimate the extent to which an LLM knows the facts stored in a knowledge base. Our knowledge estimator avoids reliability concerns with previous prompting-based methods, is both conceptually simpler and easier to apply, and we demonstrate that it can surface more of the latent knowledge embedded in LLMs. We also investigate how different design choices affect the performance of ICL-based knowledge estimation. Using the proposed estimator, we perform a large-scale evaluation of the factual knowledge of a variety of open source LLMs, like OPT, Pythia, Llama(2), Mistral, Gemma, etc. over a large set of relations and facts from the Wikidata knowledge base. We observe differences in the factual knowledge between different model families and models of different sizes, that some relations are consistently better known than others but that models differ in the precise facts they know, and differences in the knowledge of base models and their finetuned counterparts.
Diffused Redundancy in Pre-trained Representations
May 31, 2023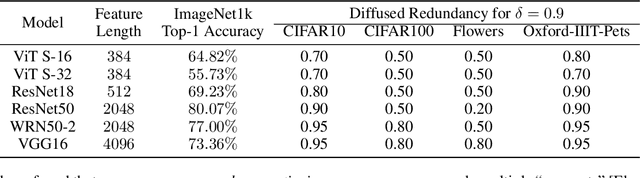
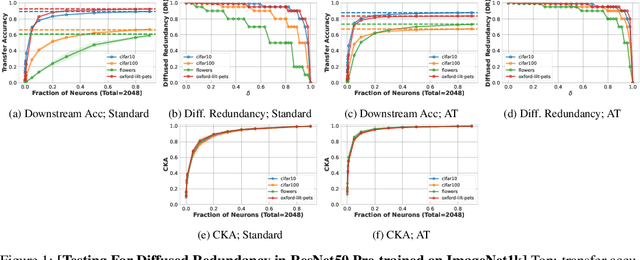
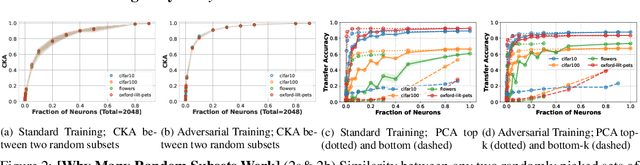
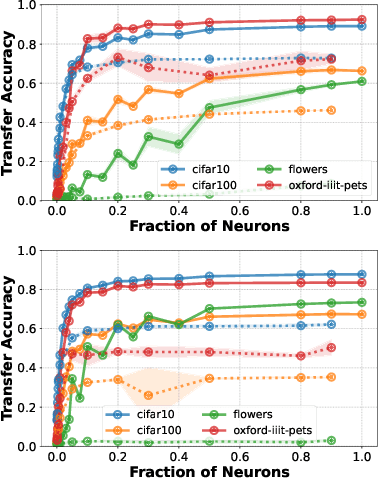
Representations learned by pre-training a neural network on a large dataset are increasingly used successfully to perform a variety of downstream tasks. In this work, we take a closer look at how features are encoded in such pre-trained representations. We find that learned representations in a given layer exhibit a degree of diffuse redundancy, i.e., any randomly chosen subset of neurons in the layer that is larger than a threshold size shares a large degree of similarity with the full layer and is able to perform similarly as the whole layer on a variety of downstream tasks. For example, a linear probe trained on $20\%$ of randomly picked neurons from a ResNet50 pre-trained on ImageNet1k achieves an accuracy within $5\%$ of a linear probe trained on the full layer of neurons for downstream CIFAR10 classification. We conduct experiments on different neural architectures (including CNNs and Transformers) pre-trained on both ImageNet1k and ImageNet21k and evaluate a variety of downstream tasks taken from the VTAB benchmark. We find that the loss & dataset used during pre-training largely govern the degree of diffuse redundancy and the "critical mass" of neurons needed often depends on the downstream task, suggesting that there is a task-inherent redundancy-performance Pareto frontier. Our findings shed light on the nature of representations learned by pre-trained deep neural networks and suggest that entire layers might not be necessary to perform many downstream tasks. We investigate the potential for exploiting this redundancy to achieve efficient generalization for downstream tasks and also draw caution to certain possible unintended consequences.
Pointwise Representational Similarity
May 30, 2023With the increasing reliance on deep neural networks, it is important to develop ways to better understand their learned representations. Representation similarity measures have emerged as a popular tool for examining learned representations However, existing measures only provide aggregate estimates of similarity at a global level, i.e. over a set of representations for N input examples. As such, these measures are not well-suited for investigating representations at a local level, i.e. representations of a single input example. Local similarity measures are needed, for instance, to understand which individual input representations are affected by training interventions to models (e.g. to be more fair and unbiased) or are at greater risk of being misclassified. In this work, we fill in this gap and propose Pointwise Normalized Kernel Alignment (PNKA), a measure that quantifies how similarly an individual input is represented in two representation spaces. Intuitively, PNKA compares the similarity of an input's neighborhoods across both spaces. Using our measure, we are able to analyze properties of learned representations at a finer granularity than what was previously possible. Concretely, we show how PNKA can be leveraged to develop a deeper understanding of (a) the input examples that are likely to be misclassified, (b) the concepts encoded by (individual) neurons in a layer, and (c) the effects of fairness interventions on learned representations.
Measuring Representational Robustness of Neural Networks Through Shared Invariances
Jun 23, 2022
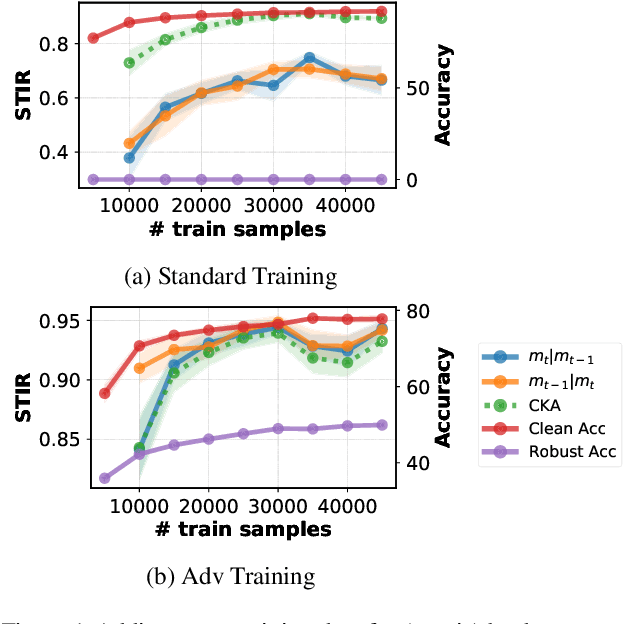

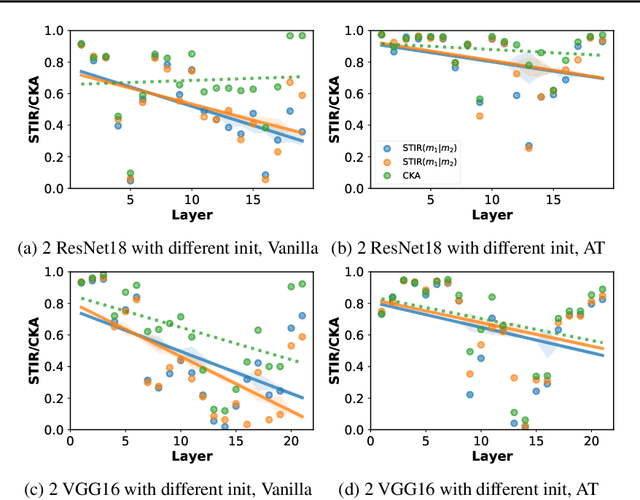
A major challenge in studying robustness in deep learning is defining the set of ``meaningless'' perturbations to which a given Neural Network (NN) should be invariant. Most work on robustness implicitly uses a human as the reference model to define such perturbations. Our work offers a new view on robustness by using another reference NN to define the set of perturbations a given NN should be invariant to, thus generalizing the reliance on a reference ``human NN'' to any NN. This makes measuring robustness equivalent to measuring the extent to which two NNs share invariances, for which we propose a measure called STIR. STIR re-purposes existing representation similarity measures to make them suitable for measuring shared invariances. Using our measure, we are able to gain insights into how shared invariances vary with changes in weight initialization, architecture, loss functions, and training dataset. Our implementation is available at: \url{https://github.com/nvedant07/STIR}.
Unifying Model Explainability and Robustness via Machine-Checkable Concepts
Jul 02, 2020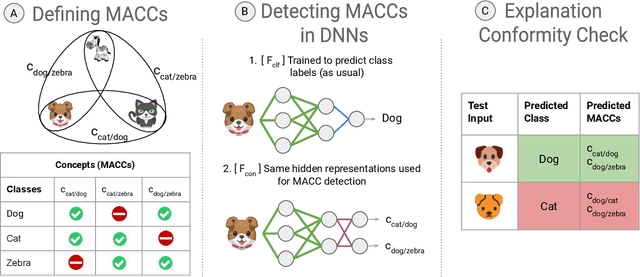



As deep neural networks (DNNs) get adopted in an ever-increasing number of applications, explainability has emerged as a crucial desideratum for these models. In many real-world tasks, one of the principal reasons for requiring explainability is to in turn assess prediction robustness, where predictions (i.e., class labels) that do not conform to their respective explanations (e.g., presence or absence of a concept in the input) are deemed to be unreliable. However, most, if not all, prior methods for checking explanation-conformity (e.g., LIME, TCAV, saliency maps) require significant manual intervention, which hinders their large-scale deployability. In this paper, we propose a robustness-assessment framework, at the core of which is the idea of using machine-checkable concepts. Our framework defines a large number of concepts that the DNN explanations could be based on and performs the explanation-conformity check at test time to assess prediction robustness. Both steps are executed in an automated manner without requiring any human intervention and are easily scaled to datasets with a very large number of classes. Experiments on real-world datasets and human surveys show that our framework is able to enhance prediction robustness significantly: the predictions marked to be robust by our framework have significantly higher accuracy and are more robust to adversarial perturbations.
A Unified Approach to Quantifying Algorithmic Unfairness: Measuring Individual & Group Unfairness via Inequality Indices
Jul 02, 2018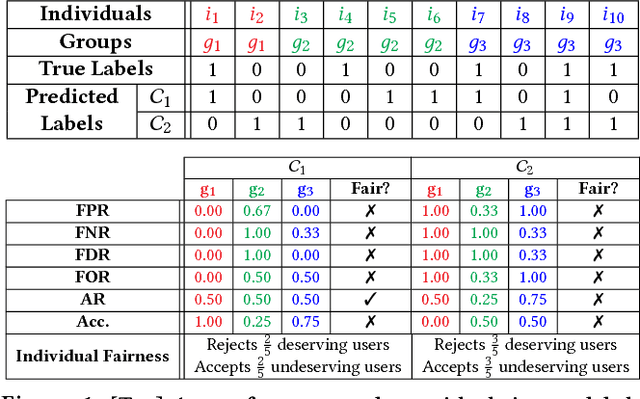
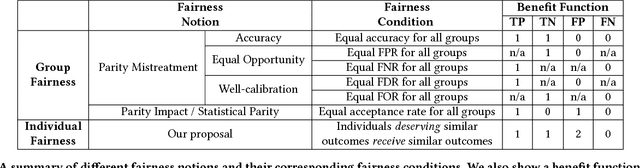

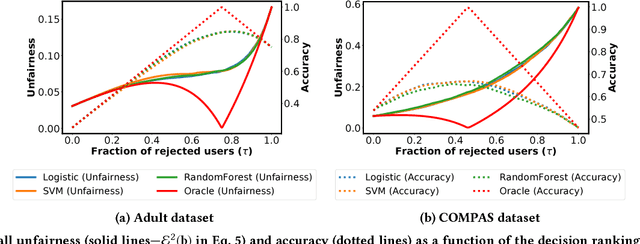
Discrimination via algorithmic decision making has received considerable attention. Prior work largely focuses on defining conditions for fairness, but does not define satisfactory measures of algorithmic unfairness. In this paper, we focus on the following question: Given two unfair algorithms, how should we determine which of the two is more unfair? Our core idea is to use existing inequality indices from economics to measure how unequally the outcomes of an algorithm benefit different individuals or groups in a population. Our work offers a justified and general framework to compare and contrast the (un)fairness of algorithmic predictors. This unifying approach enables us to quantify unfairness both at the individual and the group level. Further, our work reveals overlooked tradeoffs between different fairness notions: using our proposed measures, the overall individual-level unfairness of an algorithm can be decomposed into a between-group and a within-group component. Earlier methods are typically designed to tackle only between-group unfairness, which may be justified for legal or other reasons. However, we demonstrate that minimizing exclusively the between-group component may, in fact, increase the within-group, and hence the overall unfairness. We characterize and illustrate the tradeoffs between our measures of (un)fairness and the prediction accuracy.