 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing explainable supervised machine learning into interactive feedback loops for statistical production system
Feb 07, 2022



Statistical production systems cover multiple steps from the collection, aggregation, and integration of data to tasks like data quality assurance and dissemination. While the context of data quality assurance is one of the most promising fields for applying machine learning, the lack of curated and labeled training data is often a limiting factor. The statistical production system for the Centralised Securities Database features an interactive feedback loop between data collected by the European Central Bank and data quality assurance performed by data quality managers at National Central Banks. The quality assurance feedback loop is based on a set of rule-based checks for raising exceptions, upon which the user either confirms the data or corrects an actual error. In this paper we use the information received from this feedback loop to optimize the exceptions presented to the National Central Banks thereby improving the quality of exceptions generated and the time consumed on the system by the users authenticating those exceptions. For this approach we make use of explainable supervised machine learning to (a) identify the types of exceptions and (b) to prioritize which exceptions are more likely to require an intervention or correction by the NCBs. Furthermore, we provide an explainable AI taxonomy aiming to identify the different explainable AI needs that arose during the project.
Desiderata for Explainable AI in statistical production systems of the European Central Bank
Jul 18, 2021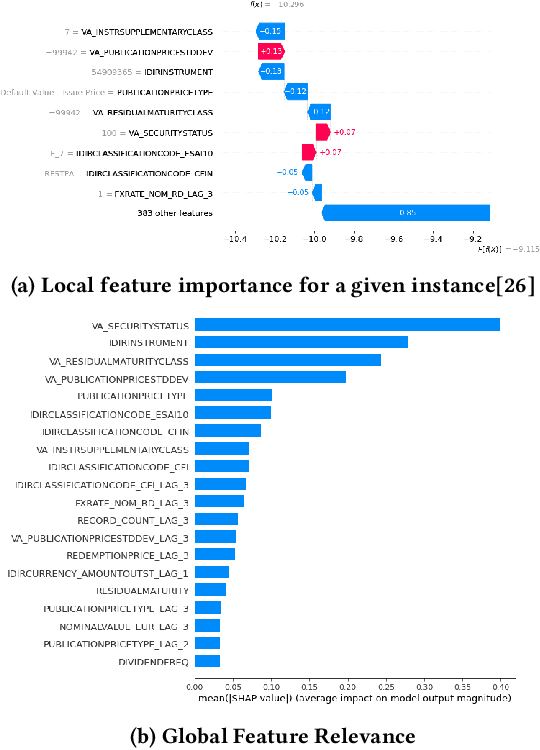


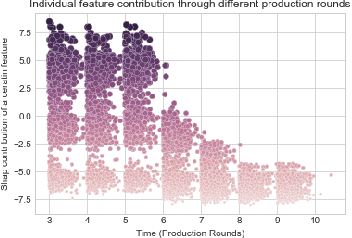
Explainable AI constitutes a fundamental step towards establishing fairness and addressing bias in algorithmic decision-making. Despite the large body of work on the topic, the benefit of solutions is mostly evaluated from a conceptual or theoretical point of view and the usefulness for real-world use cases remains uncertain. In this work, we aim to state clear user-centric desiderata for explainable AI reflecting common explainability needs experienced in statistical production systems of the European Central Bank. We link the desiderata to archetypical user roles and give examples of techniques and methods which can be used to address the user's needs. To this end, we provide two concrete use cases from the domain of statistical data production in central banks: the detection of outliers in the Centralised Securities Database and the data-driven identification of data quality checks for the Supervisory Banking data system.
Restricted Boltzmann Machines for Robust and Fast Latent Truth Discovery
Dec 31, 2017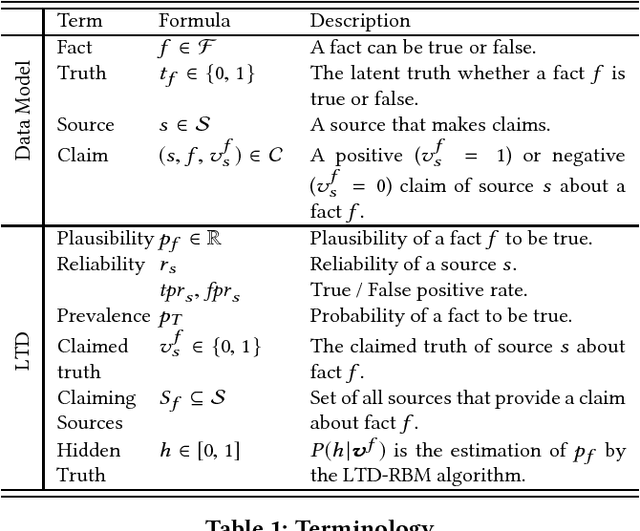


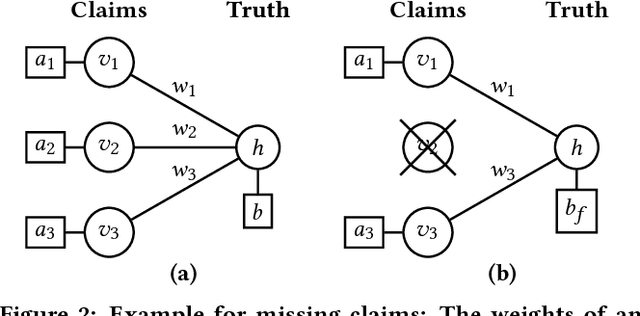
We address the problem of latent truth discovery, LTD for short, where the goal is to discover the underlying true values of entity attributes in the presence of noisy, conflicting or incomplete information. Despite a multitude of algorithms to address the LTD problem that can be found in literature, only little is known about their overall performance with respect to effectiveness (in terms of truth discovery capabilities), efficiency and robustness. A practical LTD approach should satisfy all these characteristics so that it can be applied to heterogeneous datasets of varying quality and degrees of cleanliness. We propose a novel algorithm for LTD that satisfies the above requirements. The proposed model is based on Restricted Boltzmann Machines, thus coined LTD-RBM. In extensive experiments on various heterogeneous and publicly available datasets, LTD-RBM is superior to state-of-the-art LTD techniques in terms of an overall consideration of effectiveness, efficiency and robustness.
A Generalized Language Model as the Combination of Skipped n-grams and Modified Kneser-Ney Smoothing
Apr 13, 2014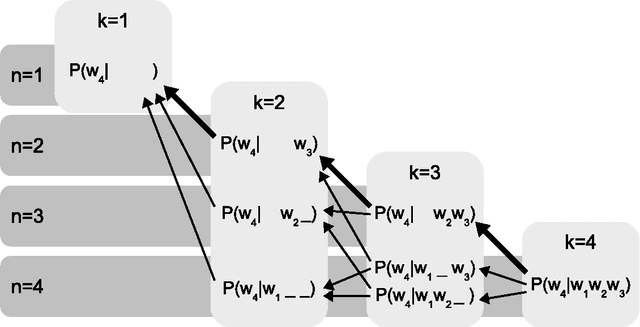
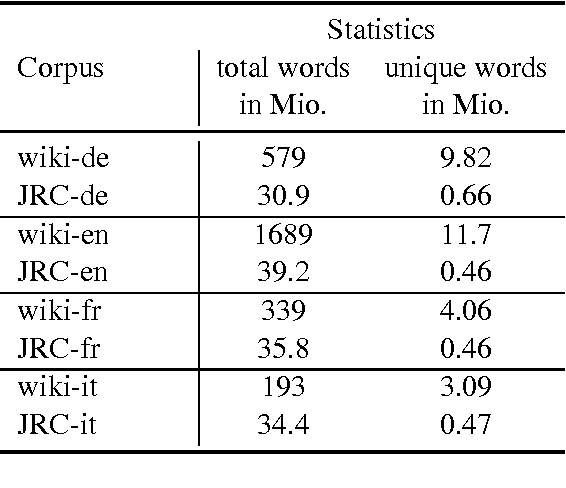
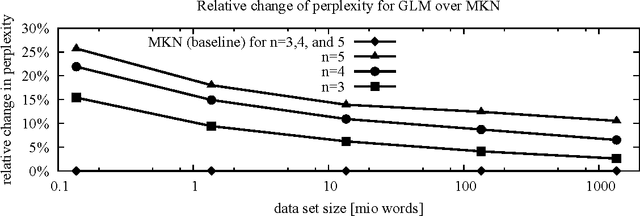
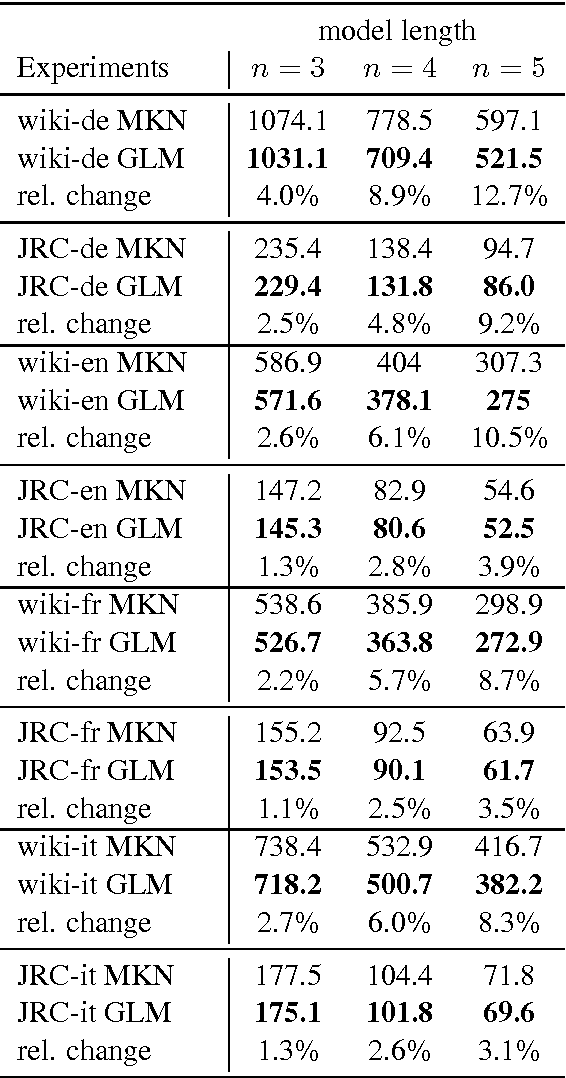
We introduce a novel approach for building language models based on a systematic, recursive exploration of skip n-gram models which are interpolated using modified Kneser-Ney smoothing. Our approach generalizes language models as it contains the classical interpolation with lower order models as a special case. In this paper we motivate, formalize and present our approach. In an extensive empirical experiment over English text corpora we demonstrate that our generalized language models lead to a substantial reduction of perplexity between 3.1% and 12.7% in comparison to traditional language models using modified Kneser-Ney smoothing. Furthermore, we investigate the behaviour over three other languages and a domain specific corpus where we observed consistent improvements. Finally, we also show that the strength of our approach lies in its ability to cope in particular with sparse training data. Using a very small training data set of only 736 KB text we yield improvements of even 25.7% reduction of perplexity.