 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Oct 08, 2025Poisoning attacks can compromise the safety of large language models (LLMs) by injecting malicious documents into their training data. Existing work has studied pretraining poisoning assuming adversaries control a percentage of the training corpus. However, for large models, even small percentages translate to impractically large amounts of data. This work demonstrates for the first time that poisoning attacks instead require a near-constant number of documents regardless of dataset size. We conduct the largest pretraining poisoning experiments to date, pretraining models from 600M to 13B parameters on chinchilla-optimal datasets (6B to 260B tokens). We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data. We also run smaller-scale experiments to ablate factors that could influence attack success, including broader ratios of poisoned to clean data and non-random distributions of poisoned samples. Finally, we demonstrate the same dynamics for poisoning during fine-tuning. Altogether, our results suggest that injecting backdoors through data poisoning may be easier for large models than previously believed as the number of poisons required does not scale up with model size, highlighting the need for more research on defences to mitigate this risk in future models.
Measuring Fairness in Financial Transaction Machine Learning Models
Jan 18, 2025



Mastercard, a global leader in financial services, develops and deploys machine learning models aimed at optimizing card usage and preventing attrition through advanced predictive models. These models use aggregated and anonymized card usage patterns, including cross-border transactions and industry-specific spending, to tailor bank offerings and maximize revenue opportunities. Mastercard has established an AI Governance program, based on its Data and Tech Responsibility Principles, to evaluate any built and bought AI for efficacy, fairness, and transparency. As part of this effort, Mastercard has sought expertise from the Turing Institute through a Data Study Group to better assess fairness in more complex AI/ML models. The Data Study Group challenge lies in defining, measuring, and mitigating fairness in these predictions, which can be complex due to the various interpretations of fairness, gaps in the research literature, and ML-operations challenges.
Model Monitoring in the Absence of Labelled Truth Data via Feature Attributions Distributions
Jan 18, 2025Model monitoring involves analyzing AI algorithms once they have been deployed and detecting changes in their behaviour. This thesis explores machine learning model monitoring ML before the predictions impact real-world decisions or users. This step is characterized by one particular condition: the absence of labelled data at test time, which makes it challenging, even often impossible, to calculate performance metrics. The thesis is structured around two main themes: (i) AI alignment, measuring if AI models behave in a manner consistent with human values and (ii) performance monitoring, measuring if the models achieve specific accuracy goals or desires. The thesis uses a common methodology that unifies all its sections. It explores feature attribution distributions for both monitoring dimensions. Using these feature attribution explanations, we can exploit their theoretical properties to derive and establish certain guarantees and insights into model monitoring.
Moral Persuasion in Large Language Models: Evaluating Susceptibility and Ethical Alignment
Nov 18, 2024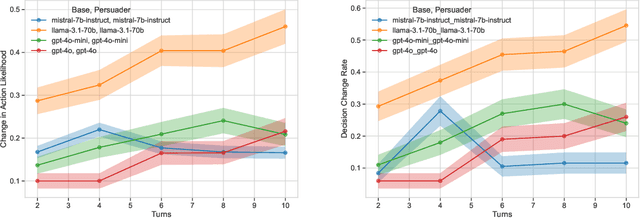

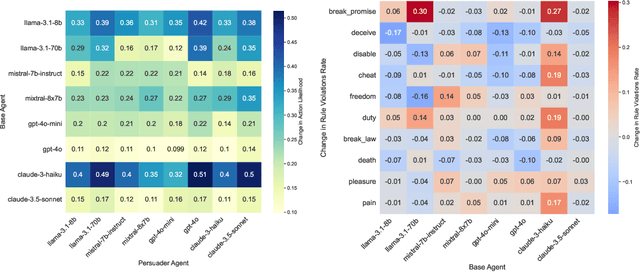

We explore how large language models (LLMs) can be influenced by prompting them to alter their initial decisions and align them with established ethical frameworks. Our study is based on two experiments designed to assess the susceptibility of LLMs to moral persuasion. In the first experiment, we examine the susceptibility to moral ambiguity by evaluating a Base Agent LLM on morally ambiguous scenarios and observing how a Persuader Agent attempts to modify the Base Agent's initial decisions. The second experiment evaluates the susceptibility of LLMs to align with predefined ethical frameworks by prompting them to adopt specific value alignments rooted in established philosophical theories. The results demonstrate that LLMs can indeed be persuaded in morally charged scenarios, with the success of persuasion depending on factors such as the model used, the complexity of the scenario, and the conversation length. Notably, LLMs of distinct sizes but from the same company produced markedly different outcomes, highlighting the variability in their susceptibility to ethical persuasion.
Model Agnostic Explainable Selective Regression via Uncertainty Estimation
Nov 15, 2023With the wide adoption of machine learning techniques, requirements have evolved beyond sheer high performance, often requiring models to be trustworthy. A common approach to increase the trustworthiness of such systems is to allow them to refrain from predicting. Such a framework is known as selective prediction. While selective prediction for classification tasks has been widely analyzed, the problem of selective regression is understudied. This paper presents a novel approach to selective regression that utilizes model-agnostic non-parametric uncertainty estimation. Our proposed framework showcases superior performance compared to state-of-the-art selective regressors, as demonstrated through comprehensive benchmarking on 69 datasets. Finally, we use explainable AI techniques to gain an understanding of the drivers behind selective regression. We implement our selective regression method in the open-source Python package doubt and release the code used to reproduce our experiments.
Kantian Deontology Meets AI Alignment: Towards Morally Robust Fairness Metrics
Nov 09, 2023Deontological ethics, specifically understood through Immanuel Kant, provides a moral framework that emphasizes the importance of duties and principles, rather than the consequences of action. Understanding that despite the prominence of deontology, it is currently an overlooked approach in fairness metrics, this paper explores the compatibility of a Kantian deontological framework in fairness metrics, part of the AI alignment field. We revisit Kant's critique of utilitarianism, which is the primary approach in AI fairness metrics and argue that fairness principles should align with the Kantian deontological framework. By integrating Kantian ethics into AI alignment, we not only bring in a widely-accepted prominent moral theory but also strive for a more morally grounded AI landscape that better balances outcomes and procedures in pursuit of fairness and justice.
How to Data in Datathons
Sep 19, 2023

The rise of datathons, also known as data or data science hackathons, has provided a platform to collaborate, learn, and innovate in a short timeframe. Despite their significant potential benefits, organizations often struggle to effectively work with data due to a lack of clear guidelines and best practices for potential issues that might arise. Drawing on our own experiences and insights from organizing >80 datathon challenges with >60 partnership organizations since 2016, we provide guidelines and recommendations that serve as a resource for organizers to navigate the data-related complexities of datathons. We apply our proposed framework to 10 case studies.
Explanation Shift: Investigating Interactions between Models and Shifting Data Distributions
Mar 14, 2023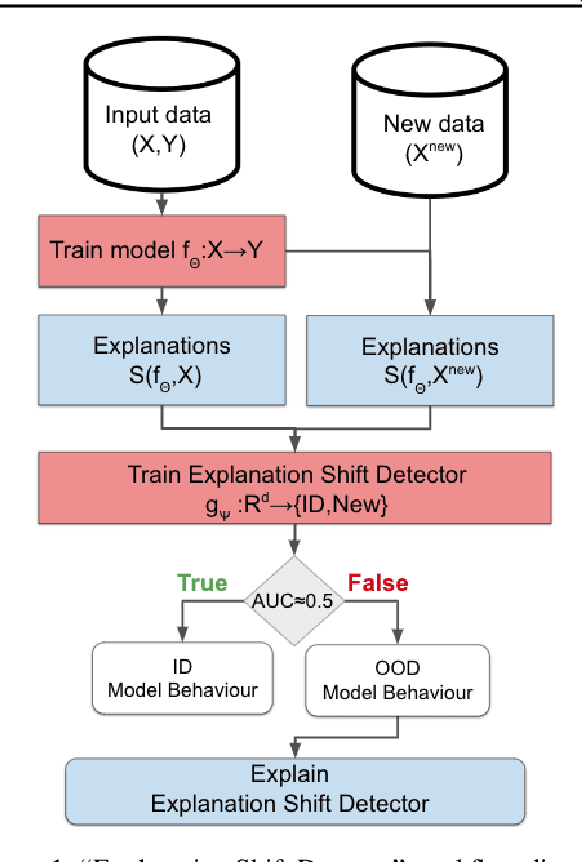
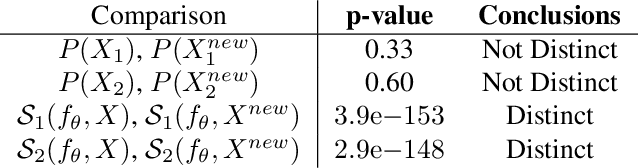
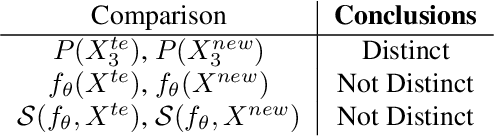
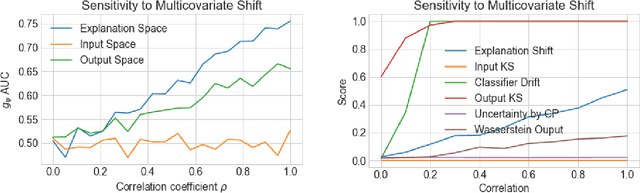
As input data distributions evolve, the predictive performance of machine learning models tends to deteriorate. In practice, new input data tend to come without target labels. Then, state-of-the-art techniques model input data distributions or model prediction distributions and try to understand issues regarding the interactions between learned models and shifting distributions. We suggest a novel approach that models how explanation characteristics shift when affected by distribution shifts. We find that the modeling of explanation shifts can be a better indicator for detecting out-of-distribution model behaviour than state-of-the-art techniques. We analyze different types of distribution shifts using synthetic examples and real-world data sets. We provide an algorithmic method that allows us to inspect the interaction between data set features and learned models and compare them to the state-of-the-art. We release our methods in an open-source Python package, as well as the code used to reproduce our experiments.
Demographic Parity Inspector: Fairness Audits via the Explanation Space
Mar 14, 2023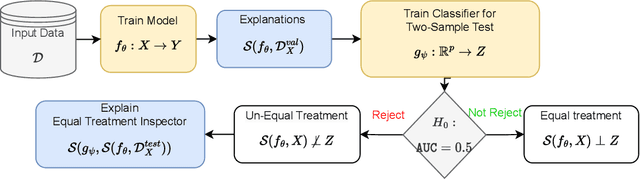
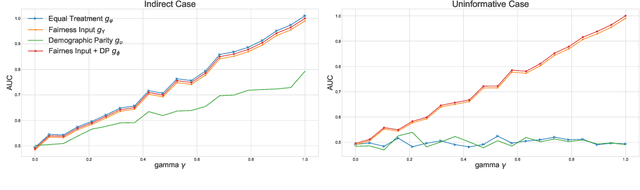
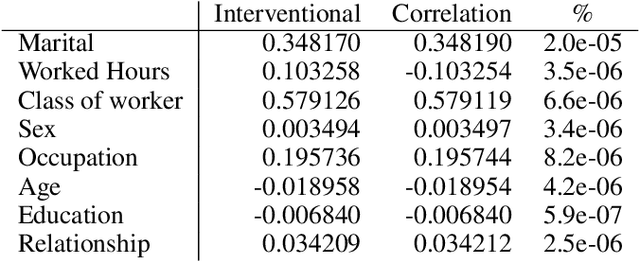
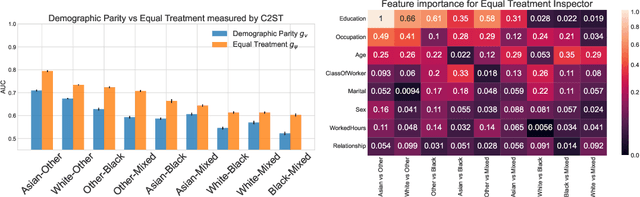
Even if deployed with the best intentions, machine learning methods can perpetuate, amplify or even create social biases. Measures of (un-)fairness have been proposed as a way to gauge the (non-)discriminatory nature of machine learning models. However, proxies of protected attributes causing discriminatory effects remain challenging to address. In this work, we propose a new algorithmic approach that measures group-wise demographic parity violations and allows us to inspect the causes of inter-group discrimination. Our method relies on the novel idea of measuring the dependence of a model on the protected attribute based on the explanation space, an informative space that allows for more sensitive audits than the primary space of input data or prediction distributions, and allowing for the assertion of theoretical demographic parity auditing guarantees. We provide a mathematical analysis, synthetic examples, and experimental evaluation of real-world data. We release an open-source Python package with methods, routines, and tutorials.
Introducing explainable supervised machine learning into interactive feedback loops for statistical production system
Feb 07, 2022



Statistical production systems cover multiple steps from the collection, aggregation, and integration of data to tasks like data quality assurance and dissemination. While the context of data quality assurance is one of the most promising fields for applying machine learning, the lack of curated and labeled training data is often a limiting factor. The statistical production system for the Centralised Securities Database features an interactive feedback loop between data collected by the European Central Bank and data quality assurance performed by data quality managers at National Central Banks. The quality assurance feedback loop is based on a set of rule-based checks for raising exceptions, upon which the user either confirms the data or corrects an actual error. In this paper we use the information received from this feedback loop to optimize the exceptions presented to the National Central Banks thereby improving the quality of exceptions generated and the time consumed on the system by the users authenticating those exceptions. For this approach we make use of explainable supervised machine learning to (a) identify the types of exceptions and (b) to prioritize which exceptions are more likely to require an intervention or correction by the NCBs. Furthermore, we provide an explainable AI taxonomy aiming to identify the different explainable AI needs that arose during the project.