 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemographic Parity Inspector: Fairness Audits via the Explanation Space
Paper and Code
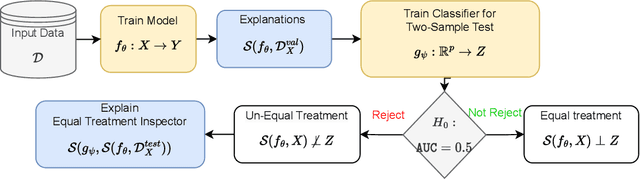
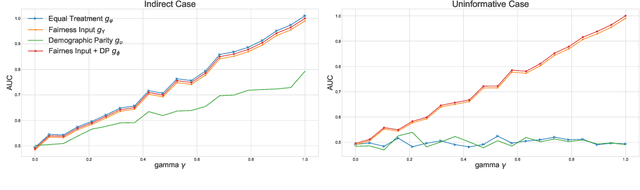
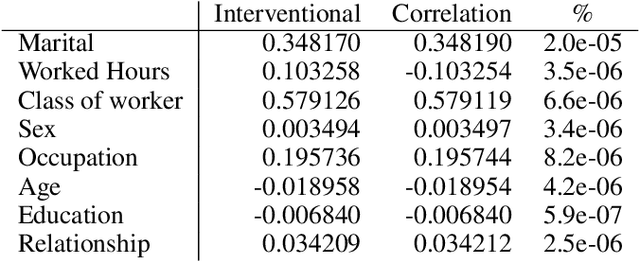
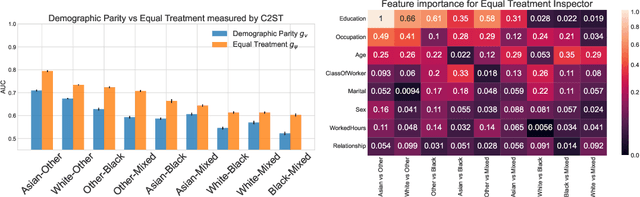
Even if deployed with the best intentions, machine learning methods can perpetuate, amplify or even create social biases. Measures of (un-)fairness have been proposed as a way to gauge the (non-)discriminatory nature of machine learning models. However, proxies of protected attributes causing discriminatory effects remain challenging to address. In this work, we propose a new algorithmic approach that measures group-wise demographic parity violations and allows us to inspect the causes of inter-group discrimination. Our method relies on the novel idea of measuring the dependence of a model on the protected attribute based on the explanation space, an informative space that allows for more sensitive audits than the primary space of input data or prediction distributions, and allowing for the assertion of theoretical demographic parity auditing guarantees. We provide a mathematical analysis, synthetic examples, and experimental evaluation of real-world data. We release an open-source Python package with methods, routines, and tutorials.