 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonX: Declarative Reasoning on Explanations
Feb 27, 2026Explaining opaque Machine Learning (ML) models has become an increasingly important challenge. However, current eXplanation in AI (XAI) methods suffer several shortcomings, including insufficient abstraction, limited user interactivity, and inadequate integration of symbolic knowledge. We propose ReasonX, an explanation tool based on expressions (or, queries) in a closed algebra of operators over theories of linear constraints. ReasonX provides declarative and interactive explanations for decision trees, which may represent the ML models under analysis or serve as global or local surrogate models for any black-box predictor. Users can express background or common sense knowledge as linear constraints. This allows for reasoning at multiple levels of abstraction, ranging from fully specified examples to under-specified or partially constrained ones. ReasonX leverages Mixed-Integer Linear Programming (MILP) to reason over the features of factual and contrastive instances. We present here the architecture of ReasonX, which consists of a Python layer, closer to the user, and a Constraint Logic Programming (CLP) layer, which implements a meta-interpreter of the query algebra. The capabilities of ReasonX are demonstrated through qualitative examples, and compared to other XAI tools through quantitative experiments.
The explanation dialogues: an expert focus study to understand requirements towards explanations within the GDPR
Jan 09, 2025



Explainable AI (XAI) provides methods to understand non-interpretable machine learning models. However, we have little knowledge about what legal experts expect from these explanations, including their legal compliance with, and value against European Union legislation. To close this gap, we present the Explanation Dialogues, an expert focus study to uncover the expectations, reasoning, and understanding of legal experts and practitioners towards XAI, with a specific focus on the European General Data Protection Regulation. The study consists of an online questionnaire and follow-up interviews, and is centered around a use-case in the credit domain. We extract both a set of hierarchical and interconnected codes using grounded theory, and present the standpoints of the participating experts towards XAI. We find that the presented explanations are hard to understand and lack information, and discuss issues that can arise from the different interests of the data controller and subject. Finally, we present a set of recommendations for developers of XAI methods, and indications of legal areas of discussion. Among others, recommendations address the presentation, choice, and content of an explanation, technical risks as well as the end-user, while we provide legal pointers to the contestability of explanations, transparency thresholds, intellectual property rights as well as the relationship between involved parties.
Declarative Reasoning on Explanations Using Constraint Logic Programming
Sep 01, 2023Explaining opaque Machine Learning (ML) models is an increasingly relevant problem. Current explanation in AI (XAI) methods suffer several shortcomings, among others an insufficient incorporation of background knowledge, and a lack of abstraction and interactivity with the user. We propose REASONX, an explanation method based on Constraint Logic Programming (CLP). REASONX can provide declarative, interactive explanations for decision trees, which can be the ML models under analysis or global/local surrogate models of any black-box model. Users can express background or common sense knowledge using linear constraints and MILP optimization over features of factual and contrastive instances, and interact with the answer constraints at different levels of abstraction through constraint projection. We present here the architecture of REASONX, which consists of a Python layer, closer to the user, and a CLP layer. REASONX's core execution engine is a Prolog meta-program with declarative semantics in terms of logic theories.
Reason to explain: Interactive contrastive explanations (REASONX)
May 29, 2023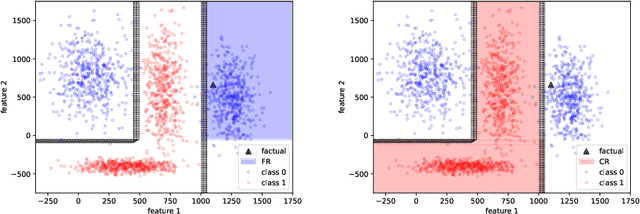
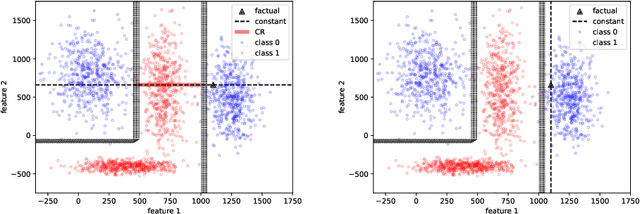
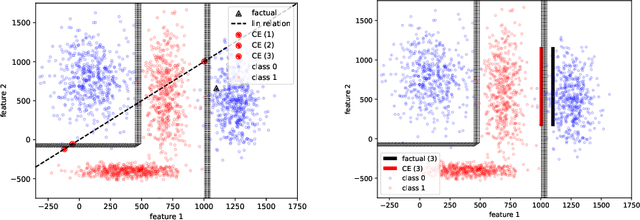
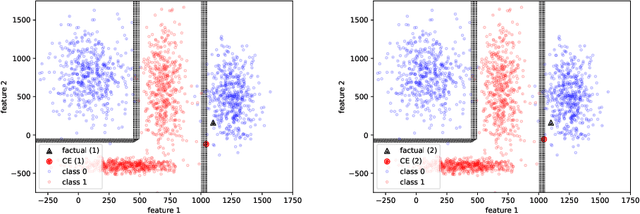
Many high-performing machine learning models are not interpretable. As they are increasingly used in decision scenarios that can critically affect individuals, it is necessary to develop tools to better understand their outputs. Popular explanation methods include contrastive explanations. However, they suffer several shortcomings, among others an insufficient incorporation of background knowledge, and a lack of interactivity. While (dialogue-like) interactivity is important to better communicate an explanation, background knowledge has the potential to significantly improve their quality, e.g., by adapting the explanation to the needs of the end-user. To close this gap, we present REASONX, an explanation tool based on Constraint Logic Programming (CLP). REASONX provides interactive contrastive explanations that can be augmented by background knowledge, and allows to operate under a setting of under-specified information, leading to increased flexibility in the provided explanations. REASONX computes factual and constrative decision rules, as well as closest constrative examples. It provides explanations for decision trees, which can be the ML models under analysis, or global/local surrogate models of any ML model. While the core part of REASONX is built on CLP, we also provide a program layer that allows to compute the explanations via Python, making the tool accessible to a wider audience. We illustrate the capability of REASONX on a synthetic data set, and on a a well-developed example in the credit domain. In both cases, we can show how REASONX can be flexibly used and tailored to the needs of the user.
Demographic Parity Inspector: Fairness Audits via the Explanation Space
Mar 14, 2023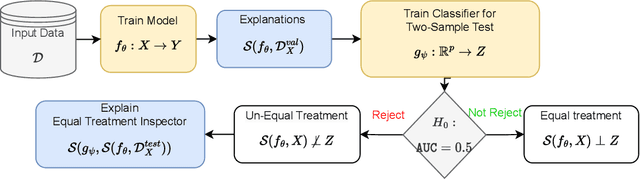
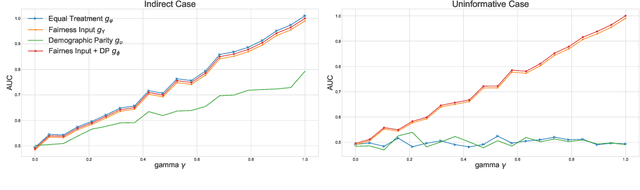
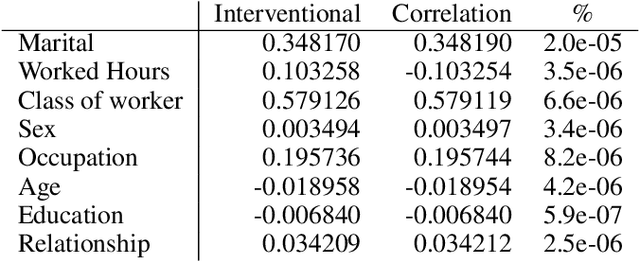
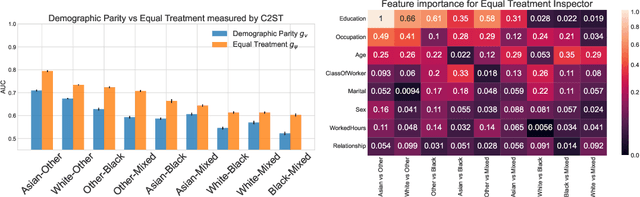
Even if deployed with the best intentions, machine learning methods can perpetuate, amplify or even create social biases. Measures of (un-)fairness have been proposed as a way to gauge the (non-)discriminatory nature of machine learning models. However, proxies of protected attributes causing discriminatory effects remain challenging to address. In this work, we propose a new algorithmic approach that measures group-wise demographic parity violations and allows us to inspect the causes of inter-group discrimination. Our method relies on the novel idea of measuring the dependence of a model on the protected attribute based on the explanation space, an informative space that allows for more sensitive audits than the primary space of input data or prediction distributions, and allowing for the assertion of theoretical demographic parity auditing guarantees. We provide a mathematical analysis, synthetic examples, and experimental evaluation of real-world data. We release an open-source Python package with methods, routines, and tutorials.
Explainability in Practice: Estimating Electrification Rates from Mobile Phone Data in Senegal
Nov 11, 2022Explainable artificial intelligence (XAI) provides explanations for not interpretable machine learning (ML) models. While many technical approaches exist, there is a lack of validation of these techniques on real-world datasets. In this work, we present a use-case of XAI: an ML model which is trained to estimate electrification rates based on mobile phone data in Senegal. The data originate from the Data for Development challenge by Orange in 2014/15. We apply two model-agnostic, local explanation techniques and find that while the model can be verified, it is biased with respect to the population density. We conclude our paper by pointing to the two main challenges we encountered during our work: data processing and model design that might be restricted by currently available XAI methods, and the importance of domain knowledge to interpret explanations.