 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonX: Declarative Reasoning on Explanations
Feb 27, 2026Explaining opaque Machine Learning (ML) models has become an increasingly important challenge. However, current eXplanation in AI (XAI) methods suffer several shortcomings, including insufficient abstraction, limited user interactivity, and inadequate integration of symbolic knowledge. We propose ReasonX, an explanation tool based on expressions (or, queries) in a closed algebra of operators over theories of linear constraints. ReasonX provides declarative and interactive explanations for decision trees, which may represent the ML models under analysis or serve as global or local surrogate models for any black-box predictor. Users can express background or common sense knowledge as linear constraints. This allows for reasoning at multiple levels of abstraction, ranging from fully specified examples to under-specified or partially constrained ones. ReasonX leverages Mixed-Integer Linear Programming (MILP) to reason over the features of factual and contrastive instances. We present here the architecture of ReasonX, which consists of a Python layer, closer to the user, and a Constraint Logic Programming (CLP) layer, which implements a meta-interpreter of the query algebra. The capabilities of ReasonX are demonstrated through qualitative examples, and compared to other XAI tools through quantitative experiments.
Bounded-Abstention Pairwise Learning to Rank
May 29, 2025


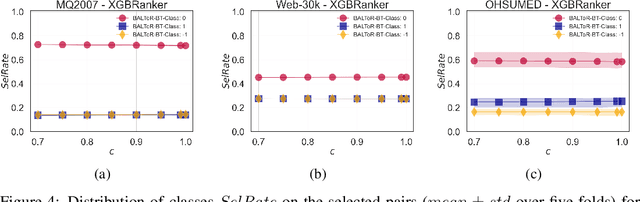
Ranking systems influence decision-making in high-stakes domains like health, education, and employment, where they can have substantial economic and social impacts. This makes the integration of safety mechanisms essential. One such mechanism is $\textit{abstention}$, which enables algorithmic decision-making system to defer uncertain or low-confidence decisions to human experts. While abstention have been predominantly explored in the context of classification tasks, its application to other machine learning paradigms remains underexplored. In this paper, we introduce a novel method for abstention in pairwise learning-to-rank tasks. Our approach is based on thresholding the ranker's conditional risk: the system abstains from making a decision when the estimated risk exceeds a predefined threshold. Our contributions are threefold: a theoretical characterization of the optimal abstention strategy, a model-agnostic, plug-in algorithm for constructing abstaining ranking models, and a comprehensive empirical evaluations across multiple datasets, demonstrating the effectiveness of our approach.
Counterfactual Situation Testing: From Single to Multidimensional Discrimination
Feb 03, 2025We present counterfactual situation testing (CST), a causal data mining framework for detecting individual discrimination in a dataset of classifier decisions. CST answers the question "what would have been the model outcome had the individual, or complainant, been of a different protected status?" It extends the legally-grounded situation testing (ST) of Thanh et al. (2011) by operationalizing the notion of fairness given the difference via counterfactual reasoning. ST finds for each complainant similar protected and non-protected instances in the dataset; constructs, respectively, a control and test group; and compares the groups such that a difference in outcomes implies a potential case of individual discrimination. CST, instead, avoids this idealized comparison by establishing the test group on the complainant's generated counterfactual, which reflects how the protected attribute when changed influences other seemingly neutral attributes of the complainant. Under CST we test for discrimination for each complainant by comparing similar individuals within each group but dissimilar individuals across groups. We consider single (e.g., gender) and multidimensional (e.g., gender and race) discrimination testing. For multidimensional discrimination we study multiple and intersectional discrimination and, as feared by legal scholars, find evidence that the former fails to account for the latter kind. Using a k-nearest neighbor implementation, we showcase CST on synthetic and real data. Experimental results show that CST uncovers a higher number of cases than ST, even when the model is counterfactually fair. In fact, CST extends counterfactual fairness (CF) of Kusner et al. (2017) by equipping CF with confidence intervals.
The explanation dialogues: an expert focus study to understand requirements towards explanations within the GDPR
Jan 09, 2025



Explainable AI (XAI) provides methods to understand non-interpretable machine learning models. However, we have little knowledge about what legal experts expect from these explanations, including their legal compliance with, and value against European Union legislation. To close this gap, we present the Explanation Dialogues, an expert focus study to uncover the expectations, reasoning, and understanding of legal experts and practitioners towards XAI, with a specific focus on the European General Data Protection Regulation. The study consists of an online questionnaire and follow-up interviews, and is centered around a use-case in the credit domain. We extract both a set of hierarchical and interconnected codes using grounded theory, and present the standpoints of the participating experts towards XAI. We find that the presented explanations are hard to understand and lack information, and discuss issues that can arise from the different interests of the data controller and subject. Finally, we present a set of recommendations for developers of XAI methods, and indications of legal areas of discussion. Among others, recommendations address the presentation, choice, and content of an explanation, technical risks as well as the end-user, while we provide legal pointers to the contestability of explanations, transparency thresholds, intellectual property rights as well as the relationship between involved parties.
A Practical Approach to Causal Inference over Time
Oct 14, 2024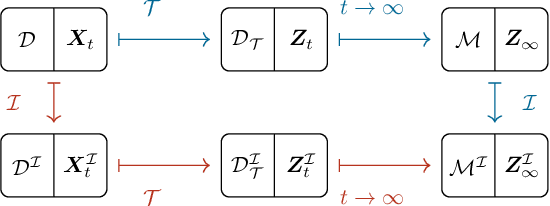
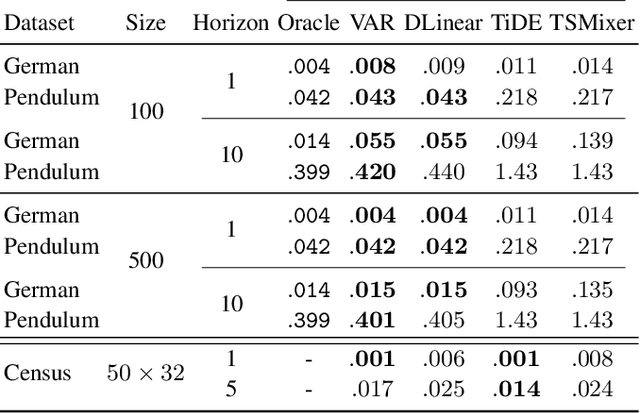
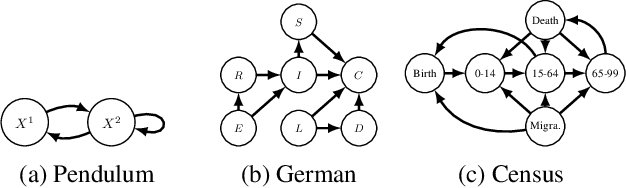
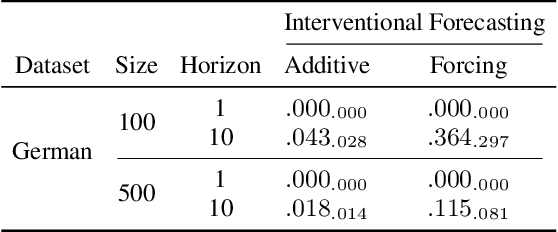
In this paper, we focus on estimating the causal effect of an intervention over time on a dynamical system. To that end, we formally define causal interventions and their effects over time on discrete-time stochastic processes (DSPs). Then, we show under which conditions the equilibrium states of a DSP, both before and after a causal intervention, can be captured by a structural causal model (SCM). With such an equivalence at hand, we provide an explicit mapping from vector autoregressive models (VARs), broadly applied in econometrics, to linear, but potentially cyclic and/or affected by unmeasured confounders, SCMs. The resulting causal VAR framework allows us to perform causal inference over time from observational time series data. Our experiments on synthetic and real-world datasets show that the proposed framework achieves strong performance in terms of observational forecasting while enabling accurate estimation of the causal effect of interventions on dynamical systems. We demonstrate, through a case study, the potential practical questions that can be addressed using the proposed causal VAR framework.
Enhancing Fairness through Reweighting: A Path to Attain the Sufficiency Rule
Aug 26, 2024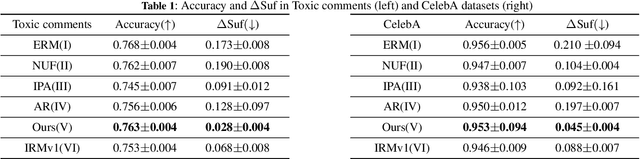
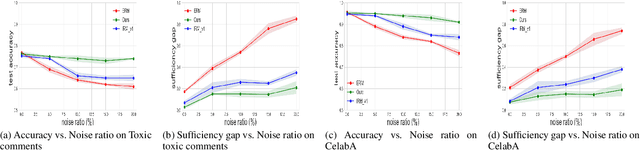
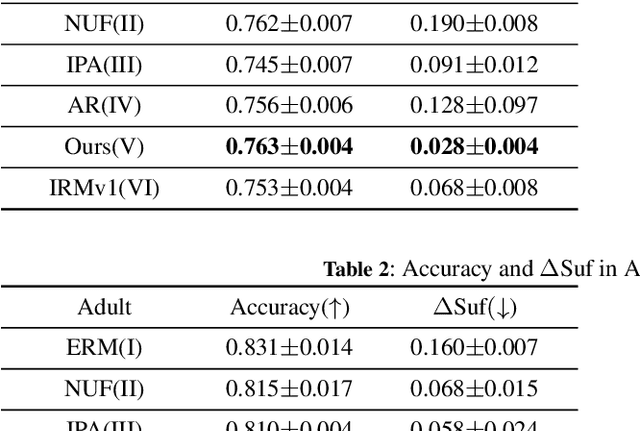
We introduce an innovative approach to enhancing the empirical risk minimization (ERM) process in model training through a refined reweighting scheme of the training data to enhance fairness. This scheme aims to uphold the sufficiency rule in fairness by ensuring that optimal predictors maintain consistency across diverse sub-groups. We employ a bilevel formulation to address this challenge, wherein we explore sample reweighting strategies. Unlike conventional methods that hinge on model size, our formulation bases generalization complexity on the space of sample weights. We discretize the weights to improve training speed. Empirical validation of our method showcases its effectiveness and robustness, revealing a consistent improvement in the balance between prediction performance and fairness metrics across various experiments.
A Causal Framework for Evaluating Deferring Systems
May 29, 2024Deferring systems extend supervised Machine Learning (ML) models with the possibility to defer predictions to human experts. However, evaluating the impact of a deferring strategy on system accuracy is still an overlooked area. This paper fills this gap by evaluating deferring systems through a causal lens. We link the potential outcomes framework for causal inference with deferring systems. This allows us to identify the causal impact of the deferring strategy on predictive accuracy. We distinguish two scenarios. In the first one, we can access both the human and the ML model predictions for the deferred instances. In such a case, we can identify the individual causal effects for deferred instances and aggregates of them. In the second scenario, only human predictions are available for the deferred instances. In this case, we can resort to regression discontinuity design to estimate a local causal effect. We empirically evaluate our approach on synthetic and real datasets for seven deferring systems from the literature.
Uncovering Algorithmic Discrimination: An Opportunity to Revisit the Comparator
May 22, 2024Causal reasoning, in particular, counterfactual reasoning plays a central role in testing for discrimination. Counterfactual reasoning materializes when testing for discrimination, what is known as the counterfactual model of discrimination, when we compare the discrimination comparator with the discrimination complainant, where the comparator is a similar (or similarly situated) profile to that of the complainant used for testing the discrimination claim of the complainant. In this paper, we revisit the comparator by presenting two kinds of comparators based on the sort of causal intervention we want to represent. We present the ceteris paribus and the mutatis mutandis comparator, where the former is the standard and the latter is a new kind of comparator. We argue for the use of the mutatis mutandis comparator, which is built on the fairness given the difference notion, for testing future algorithmic discrimination cases.
Causal Perception
Jan 24, 2024Perception occurs when two individuals interpret the same information differently. Despite being a known phenomenon with implications for bias in decision-making, as individuals' experience determines interpretation, perception remains largely overlooked in automated decision-making (ADM) systems. In particular, it can have considerable effects on the fairness or fair usage of an ADM system, as fairness itself is context-specific and its interpretation dependent on who is judging. In this work, we formalize perception under causal reasoning to capture the act of interpretation by an individual. We also formalize individual experience as additional causal knowledge that comes with and is used by an individual. Further, we define and discuss loaded attributes, which are attributes prone to evoke perception. Sensitive attributes, such as gender and race, are clear examples of loaded attributes. We define two kinds of causal perception, unfaithful and inconsistent, based on the causal properties of faithfulness and consistency. We illustrate our framework through a series of decision-making examples and discuss relevant fairness applications. The goal of this work is to position perception as a parameter of interest, useful for extending the standard, single interpretation ADM problem formulation.
Deep Neural Network Benchmarks for Selective Classification
Jan 23, 2024With the increasing deployment of machine learning models in many socially-sensitive tasks, there is a growing demand for reliable and trustworthy predictions. One way to accomplish these requirements is to allow a model to abstain from making a prediction when there is a high risk of making an error. This requires adding a selection mechanism to the model, which selects those examples for which the model will provide a prediction. The selective classification framework aims to design a mechanism that balances the fraction of rejected predictions (i.e., the proportion of examples for which the model does not make a prediction) versus the improvement in predictive performance on the selected predictions. Multiple selective classification frameworks exist, most of which rely on deep neural network architectures. However, the empirical evaluation of the existing approaches is still limited to partial comparisons among methods and settings, providing practitioners with little insight into their relative merits. We fill this gap by benchmarking 18 baselines on a diverse set of 44 datasets that includes both image and tabular data. Moreover, there is a mix of binary and multiclass tasks. We evaluate these approaches using several criteria, including selective error rate, empirical coverage, distribution of rejected instance's classes, and performance on out-of-distribution instances. The results indicate that there is not a single clear winner among the surveyed baselines, and the best method depends on the users' objectives.