 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Fairness through Reweighting: A Path to Attain the Sufficiency Rule
Aug 26, 2024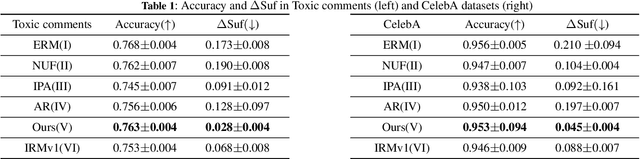
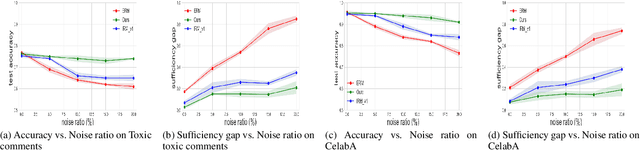
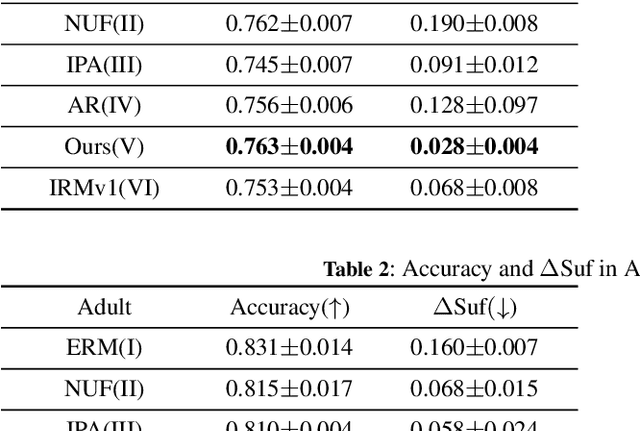
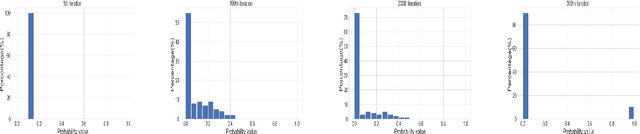
We introduce an innovative approach to enhancing the empirical risk minimization (ERM) process in model training through a refined reweighting scheme of the training data to enhance fairness. This scheme aims to uphold the sufficiency rule in fairness by ensuring that optimal predictors maintain consistency across diverse sub-groups. We employ a bilevel formulation to address this challenge, wherein we explore sample reweighting strategies. Unlike conventional methods that hinge on model size, our formulation bases generalization complexity on the space of sample weights. We discretize the weights to improve training speed. Empirical validation of our method showcases its effectiveness and robustness, revealing a consistent improvement in the balance between prediction performance and fairness metrics across various experiments.
Counterfactual Explanation for Regression via Disentanglement in Latent Space
Nov 23, 2023



Counterfactual Explanations (CEs) help address the question: How can the factors that influence the prediction of a predictive model be changed to achieve a more favorable outcome from a user's perspective? Thus, they bear the potential to guide the user's interaction with AI systems since they represent easy-to-understand explanations. To be applicable, CEs need to be realistic and actionable. In the literature, various methods have been proposed to generate CEs. However, the majority of research on CEs focuses on classification problems where questions like "What should I do to get my rejected loan approved?" are raised. In practice, answering questions like "What should I do to increase my salary?" are of a more regressive nature. In this paper, we introduce a novel method to generate CEs for a pre-trained regressor by first disentangling the label-relevant from the label-irrelevant dimensions in the latent space. CEs are then generated by combining the label-irrelevant dimensions and the predefined output. The intuition behind this approach is that the ideal counterfactual search should focus on the label-irrelevant characteristics of the input and suggest changes toward target-relevant characteristics. Searching in the latent space could help achieve this goal. We show that our method maintains the characteristics of the query sample during the counterfactual search. In various experiments, we demonstrate that the proposed method is competitive based on different quality measures on image and tabular datasets in regression problem settings. It efficiently returns results closer to the original data manifold compared to three state-of-the-art methods, which is essential for realistic high-dimensional machine learning applications. Our code will be made available as an open-source package upon the publication of this work.
Adversarial Reweighting Guided by Wasserstein Distance for Bias Mitigation
Nov 21, 2023



The unequal representation of different groups in a sample population can lead to discrimination of minority groups when machine learning models make automated decisions. To address these issues, fairness-aware machine learning jointly optimizes two (or more) metrics aiming at predictive effectiveness and low unfairness. However, the inherent under-representation of minorities in the data makes the disparate treatment of subpopulations less noticeable and difficult to deal with during learning. In this paper, we propose a novel adversarial reweighting method to address such \emph{representation bias}. To balance the data distribution between the majority and the minority groups, our approach deemphasizes samples from the majority group. To minimize empirical risk, our method prefers samples from the majority group that are close to the minority group as evaluated by the Wasserstein distance. Our theoretical analysis shows the effectiveness of our adversarial reweighting approach. Experiments demonstrate that our approach mitigates bias without sacrificing classification accuracy, outperforming related state-of-the-art methods on image and tabular benchmark datasets.
Causal Fairness-Guided Dataset Reweighting using Neural Networks
Nov 17, 2023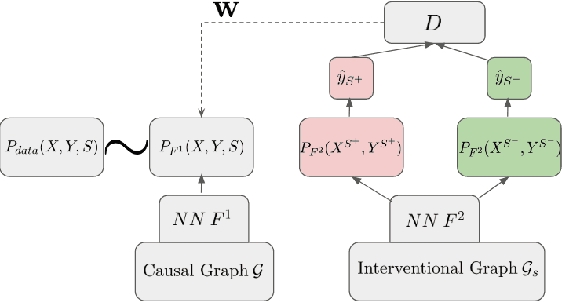
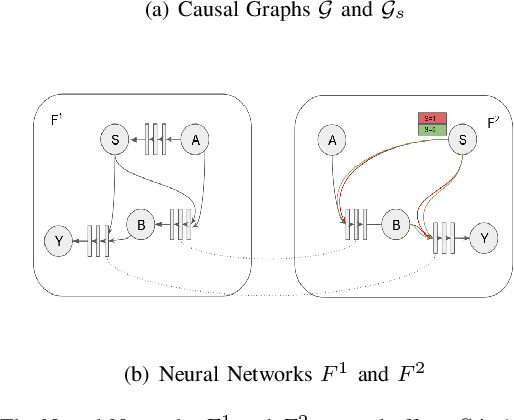
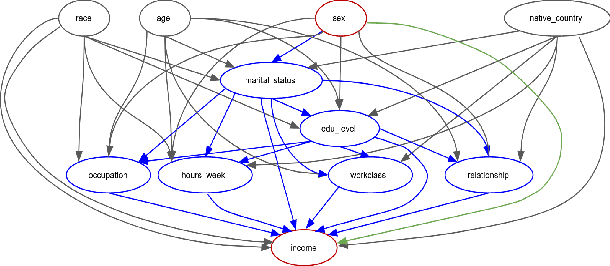
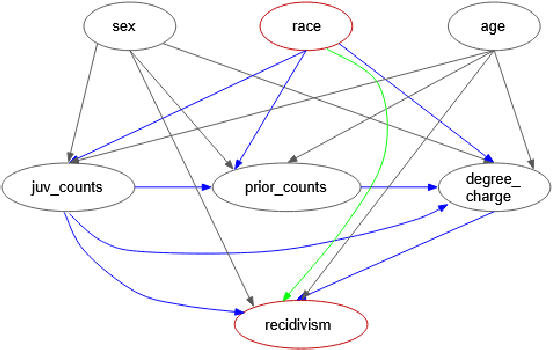
The importance of achieving fairness in machine learning models cannot be overstated. Recent research has pointed out that fairness should be examined from a causal perspective, and several fairness notions based on the on Pearl's causal framework have been proposed. In this paper, we construct a reweighting scheme of datasets to address causal fairness. Our approach aims at mitigating bias by considering the causal relationships among variables and incorporating them into the reweighting process. The proposed method adopts two neural networks, whose structures are intentionally used to reflect the structures of a causal graph and of an interventional graph. The two neural networks can approximate the causal model of the data, and the causal model of interventions. Furthermore, reweighting guided by a discriminator is applied to achieve various fairness notions. Experiments on real-world datasets show that our method can achieve causal fairness on the data while remaining close to the original data for downstream tasks.
Interpretable Distribution-Invariant Fairness Measures for Continuous Scores
Aug 22, 2023



Measures of algorithmic fairness are usually discussed in the context of binary decisions. We extend the approach to continuous scores. So far, ROC-based measures have mainly been suggested for this purpose. Other existing methods depend heavily on the distribution of scores, are unsuitable for ranking tasks, or their effect sizes are not interpretable. Here, we propose a distributionally invariant version of fairness measures for continuous scores with a reasonable interpretation based on the Wasserstein distance. Our measures are easily computable and well suited for quantifying and interpreting the strength of group disparities as well as for comparing biases across different models, datasets, or time points. We derive a link between the different families of existing fairness measures for scores and show that the proposed distributionally invariant fairness measures outperform ROC-based fairness measures because they are more explicit and can quantify significant biases that ROC-based fairness measures miss. Finally, we demonstrate their effectiveness through experiments on the most commonly used fairness benchmark datasets.
Counterfactual Explanation via Search in Gaussian Mixture Distributed Latent Space
Jul 25, 2023



Counterfactual Explanations (CEs) are an important tool in Algorithmic Recourse for addressing two questions: 1. What are the crucial factors that led to an automated prediction/decision? 2. How can these factors be changed to achieve a more favorable outcome from a user's perspective? Thus, guiding the user's interaction with AI systems by proposing easy-to-understand explanations and easy-to-attain feasible changes is essential for the trustworthy adoption and long-term acceptance of AI systems. In the literature, various methods have been proposed to generate CEs, and different quality measures have been suggested to evaluate these methods. However, the generation of CEs is usually computationally expensive, and the resulting suggestions are unrealistic and thus non-actionable. In this paper, we introduce a new method to generate CEs for a pre-trained binary classifier by first shaping the latent space of an autoencoder to be a mixture of Gaussian distributions. CEs are then generated in latent space by linear interpolation between the query sample and the centroid of the target class. We show that our method maintains the characteristics of the input sample during the counterfactual search. In various experiments, we show that the proposed method is competitive based on different quality measures on image and tabular datasets -- efficiently returns results that are closer to the original data manifold compared to three state-of-the-art methods, which are essential for realistic high-dimensional machine learning applications.
Explanation Shift: Investigating Interactions between Models and Shifting Data Distributions
Mar 14, 2023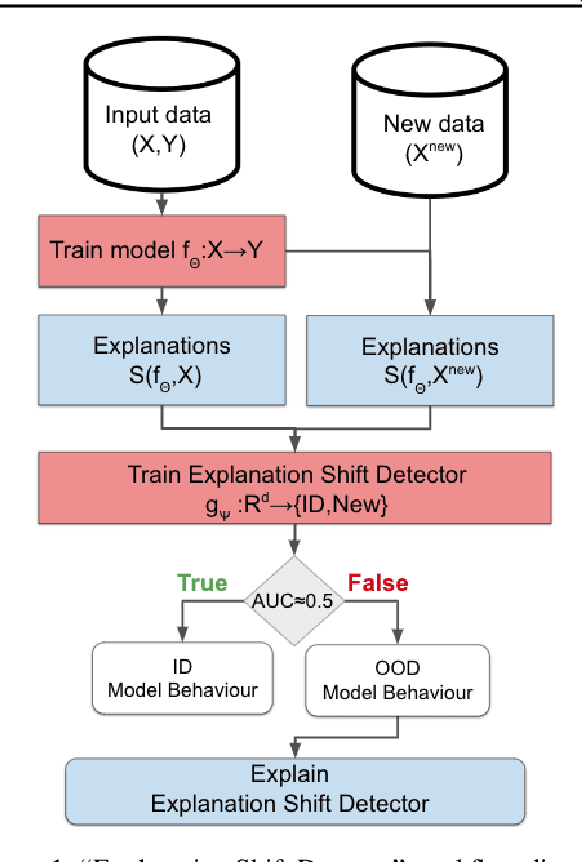
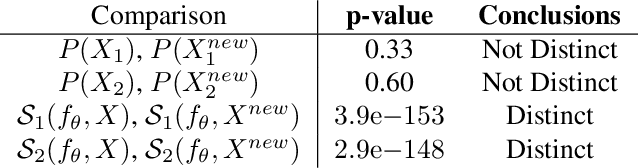
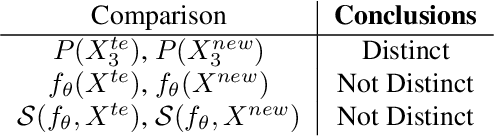
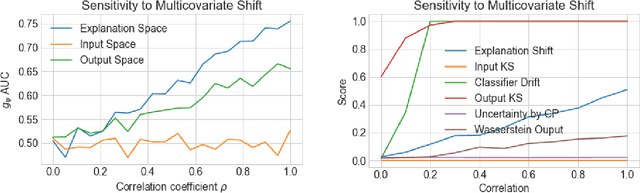
As input data distributions evolve, the predictive performance of machine learning models tends to deteriorate. In practice, new input data tend to come without target labels. Then, state-of-the-art techniques model input data distributions or model prediction distributions and try to understand issues regarding the interactions between learned models and shifting distributions. We suggest a novel approach that models how explanation characteristics shift when affected by distribution shifts. We find that the modeling of explanation shifts can be a better indicator for detecting out-of-distribution model behaviour than state-of-the-art techniques. We analyze different types of distribution shifts using synthetic examples and real-world data sets. We provide an algorithmic method that allows us to inspect the interaction between data set features and learned models and compare them to the state-of-the-art. We release our methods in an open-source Python package, as well as the code used to reproduce our experiments.
Dynamic Model Tree for Interpretable Data Stream Learning
Mar 30, 2022
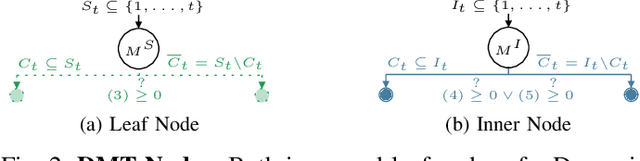


Data streams are ubiquitous in modern business and society. In practice, data streams may evolve over time and cannot be stored indefinitely. Effective and transparent machine learning on data streams is thus often challenging. Hoeffding Trees have emerged as a state-of-the art for online predictive modelling. They are easy to train and provide meaningful convergence guarantees under a stationary process. Yet, at the same time, Hoeffding Trees often require heuristic and costly extensions to adjust to distributional change, which may considerably impair their interpretability. In this work, we revisit Model Trees for machine learning in evolving data streams. Model Trees are able to maintain more flexible and locally robust representations of the active data concept, making them a natural fit for data stream applications. Our novel framework, called Dynamic Model Tree, satisfies desirable consistency and minimality properties. In experiments with synthetic and real-world tabular streaming data sets, we show that the proposed framework can drastically reduce the number of splits required by existing incremental decision trees. At the same time, our framework often outperforms state-of-the-art models in terms of predictive quality -- especially when concept drift is involved. Dynamic Model Trees are thus a powerful online learning framework that contributes to more lightweight and interpretable machine learning in data streams.
On Counterfactual Explanations under Predictive Multiplicity
Jun 23, 2020


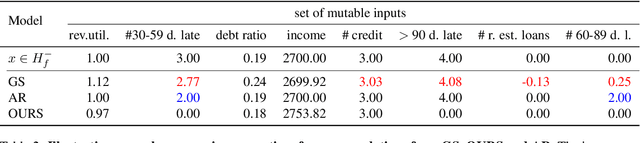
Counterfactual explanations are usually obtained by identifying the smallest change made to an input to change a prediction made by a fixed model (hereafter called sparse methods). Recent work, however, has revitalized an old insight: there often does not exist one superior solution to a prediction problem with respect to commonly used measures of interest (e.g. error rate). In fact, often multiple different classifiers give almost equal solutions. This phenomenon is known as predictive multiplicity (Breiman, 2001; Marx et al., 2019). In this work, we derive a general upper bound for the costs of counterfactual explanations under predictive multiplicity. Most notably, it depends on a discrepancy notion between two classifiers, which describes how differently they treat negatively predicted individuals. We then compare sparse and data support approaches empirically on real-world data. The results show that data support methods are more robust to multiplicity of different models. At the same time, we show that those methods have provably higher cost of generating counterfactual explanations under one fixed model. In summary, our theoretical and empiricaln results challenge the commonly held view that counterfactual recommendations should be sparse in general.
Leveraging Model Inherent Variable Importance for Stable Online Feature Selection
Jun 18, 2020


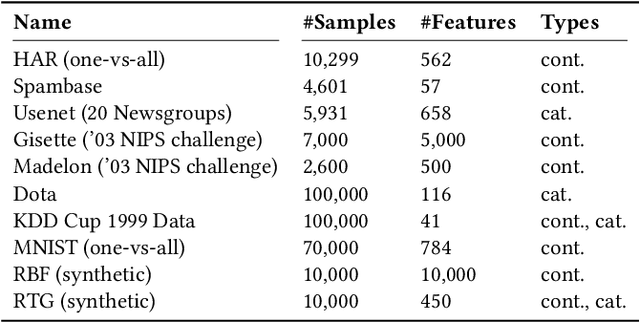
Feature selection can be a crucial factor in obtaining robust and accurate predictions. Online feature selection models, however, operate under considerable restrictions; they need to efficiently extract salient input features based on a bounded set of observations, while enabling robust and accurate predictions. In this work, we introduce FIRES, a novel framework for online feature selection. The proposed feature weighting mechanism leverages the importance information inherent in the parameters of a predictive model. By treating model parameters as random variables, we can penalize features with high uncertainty and thus generate more stable feature sets. Our framework is generic in that it leaves the choice of the underlying model to the user. Strikingly, experiments suggest that the model complexity has only a minor effect on the discriminative power and stability of the selected feature sets. In fact, using a simple linear model, FIRES obtains feature sets that compete with state-of-the-art methods, while dramatically reducing computation time. In addition, experiments show that the proposed framework is clearly superior in terms of feature selection stability.