 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Cohesion-Fairness Harmony: Contrastive Regularization in Individual Fair Graph Clustering
Feb 16, 2024Conventional fair graph clustering methods face two primary challenges: i) They prioritize balanced clusters at the expense of cluster cohesion by imposing rigid constraints, ii) Existing methods of both individual and group-level fairness in graph partitioning mostly rely on eigen decompositions and thus, generally lack interpretability. To address these issues, we propose iFairNMTF, an individual Fairness Nonnegative Matrix Tri-Factorization model with contrastive fairness regularization that achieves balanced and cohesive clusters. By introducing fairness regularization, our model allows for customizable accuracy-fairness trade-offs, thereby enhancing user autonomy without compromising the interpretability provided by nonnegative matrix tri-factorization. Experimental evaluations on real and synthetic datasets demonstrate the superior flexibility of iFairNMTF in achieving fairness and clustering performance.
Adversarial Reweighting Guided by Wasserstein Distance for Bias Mitigation
Nov 21, 2023



The unequal representation of different groups in a sample population can lead to discrimination of minority groups when machine learning models make automated decisions. To address these issues, fairness-aware machine learning jointly optimizes two (or more) metrics aiming at predictive effectiveness and low unfairness. However, the inherent under-representation of minorities in the data makes the disparate treatment of subpopulations less noticeable and difficult to deal with during learning. In this paper, we propose a novel adversarial reweighting method to address such \emph{representation bias}. To balance the data distribution between the majority and the minority groups, our approach deemphasizes samples from the majority group. To minimize empirical risk, our method prefers samples from the majority group that are close to the minority group as evaluated by the Wasserstein distance. Our theoretical analysis shows the effectiveness of our adversarial reweighting approach. Experiments demonstrate that our approach mitigates bias without sacrificing classification accuracy, outperforming related state-of-the-art methods on image and tabular benchmark datasets.
Affinity Clustering Framework for Data Debiasing Using Pairwise Distribution Discrepancy
Jun 02, 2023Group imbalance, resulting from inadequate or unrepresentative data collection methods, is a primary cause of representation bias in datasets. Representation bias can exist with respect to different groups of one or more protected attributes and might lead to prejudicial and discriminatory outcomes toward certain groups of individuals; in cases where a learning model is trained on such biased data. This paper presents MASC, a data augmentation approach that leverages affinity clustering to balance the representation of non-protected and protected groups of a target dataset by utilizing instances of the same protected attributes from similar datasets that are categorized in the same cluster as the target dataset by sharing instances of the protected attribute. The proposed method involves constructing an affinity matrix by quantifying distribution discrepancies between dataset pairs and transforming them into a symmetric pairwise similarity matrix. A non-parametric spectral clustering is then applied to this affinity matrix, automatically categorizing the datasets into an optimal number of clusters. We perform a step-by-step experiment as a demo of our method to show the procedure of the proposed data augmentation method and evaluate and discuss its performance. A comparison with other data augmentation methods, both pre- and post-augmentation, is conducted, along with a model evaluation analysis of each method. Our method can handle non-binary protected attributes so, in our experiments, bias is measured in a non-binary protected attribute setup w.r.t. racial groups distribution for two separate minority groups in comparison with the majority group before and after debiasing. Empirical results imply that our method of augmenting dataset biases using real (genuine) data from similar contexts can effectively debias the target datasets comparably to existing data augmentation strategies.
Context matters for fairness -- a case study on the effect of spatial distribution shifts
Jun 24, 2022
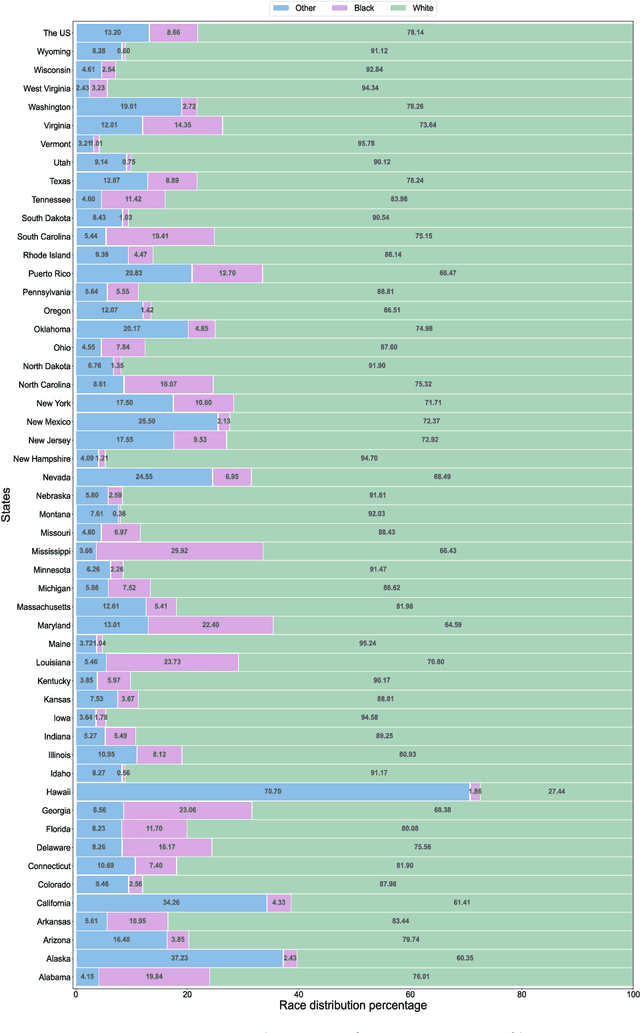
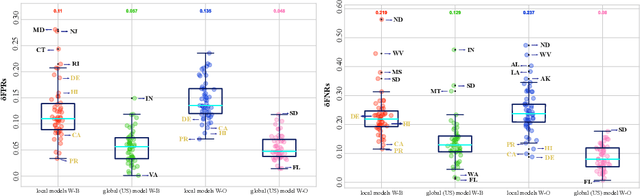
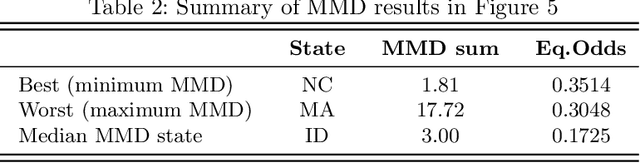
With the ever growing involvement of data-driven AI-based decision making technologies in our daily social lives, the fairness of these systems is becoming a crucial phenomenon. However, an important and often challenging aspect in utilizing such systems is to distinguish validity for the range of their application especially under distribution shifts, i.e., when a model is deployed on data with different distribution than the training set. In this paper, we present a case study on the newly released American Census datasets, a reconstruction of the popular Adult dataset, to illustrate the importance of context for fairness and show how remarkably can spatial distribution shifts affect predictive- and fairness-related performance of a model. The problem persists for fairness-aware learning models with the effects of context-specific fairness interventions differing across the states and different population groups. Our study suggests that robustness to distribution shifts is necessary before deploying a model to another context.