 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Counterfactual Explanations under Predictive Multiplicity
Paper and Code



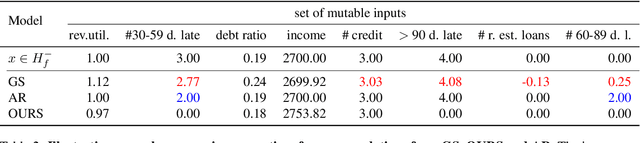
Counterfactual explanations are usually obtained by identifying the smallest change made to an input to change a prediction made by a fixed model (hereafter called sparse methods). Recent work, however, has revitalized an old insight: there often does not exist one superior solution to a prediction problem with respect to commonly used measures of interest (e.g. error rate). In fact, often multiple different classifiers give almost equal solutions. This phenomenon is known as predictive multiplicity (Breiman, 2001; Marx et al., 2019). In this work, we derive a general upper bound for the costs of counterfactual explanations under predictive multiplicity. Most notably, it depends on a discrepancy notion between two classifiers, which describes how differently they treat negatively predicted individuals. We then compare sparse and data support approaches empirically on real-world data. The results show that data support methods are more robust to multiplicity of different models. At the same time, we show that those methods have provably higher cost of generating counterfactual explanations under one fixed model. In summary, our theoretical and empiricaln results challenge the commonly held view that counterfactual recommendations should be sparse in general.