 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Explaining Knowledge Distillation: Measuring and Visualising the Knowledge Transfer Process
Dec 18, 2024
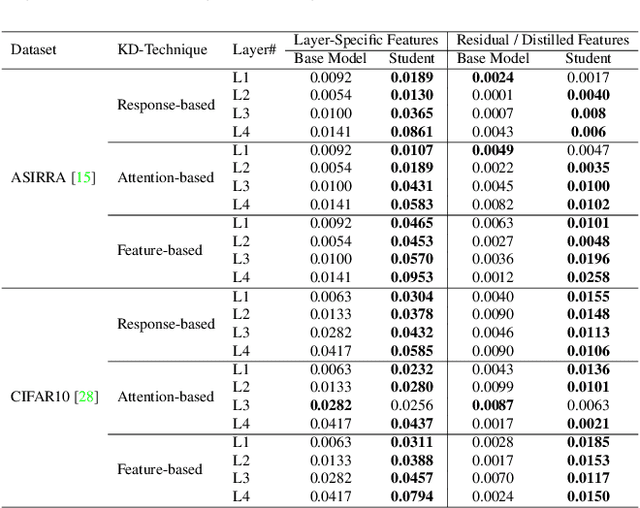
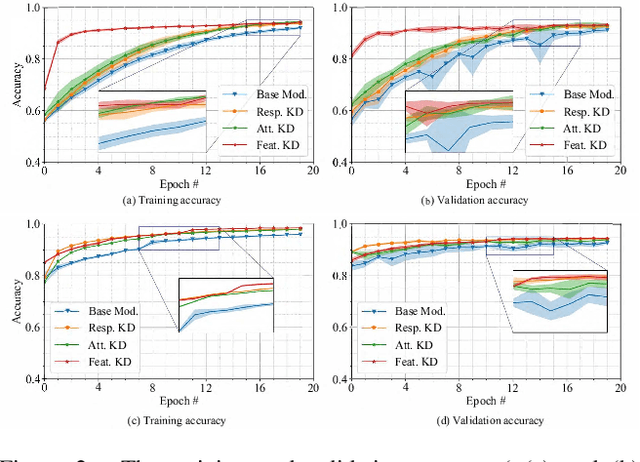
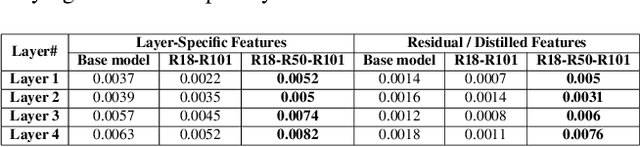
Knowledge distillation (KD) remains challenging due to the opaque nature of the knowledge transfer process from a Teacher to a Student, making it difficult to address certain issues related to KD. To address this, we proposed UniCAM, a novel gradient-based visual explanation method, which effectively interprets the knowledge learned during KD. Our experimental results demonstrate that with the guidance of the Teacher's knowledge, the Student model becomes more efficient, learning more relevant features while discarding those that are not relevant. We refer to the features learned with the Teacher's guidance as distilled features and the features irrelevant to the task and ignored by the Student as residual features. Distilled features focus on key aspects of the input, such as textures and parts of objects. In contrast, residual features demonstrate more diffused attention, often targeting irrelevant areas, including the backgrounds of the target objects. In addition, we proposed two novel metrics: the feature similarity score (FSS) and the relevance score (RS), which quantify the relevance of the distilled knowledge. Experiments on the CIFAR10, ASIRRA, and Plant Disease datasets demonstrate that UniCAM and the two metrics offer valuable insights to explain the KD process.
Spatial-aware Transformer-GRU Framework for Enhanced Glaucoma Diagnosis from 3D OCT Imaging
Mar 08, 2024Glaucoma, a leading cause of irreversible blindness, necessitates early detection for accurate and timely intervention to prevent irreversible vision loss. In this study, we present a novel deep learning framework that leverages the diagnostic value of 3D Optical Coherence Tomography (OCT) imaging for automated glaucoma detection. In this framework, we integrate a pre-trained Vision Transformer on retinal data for rich slice-wise feature extraction and a bidirectional Gated Recurrent Unit for capturing inter-slice spatial dependencies. This dual-component approach enables comprehensive analysis of local nuances and global structural integrity, crucial for accurate glaucoma diagnosis. Experimental results on a large dataset demonstrate the superior performance of the proposed method over state-of-the-art ones, achieving an F1-score of 93.58%, Matthews Correlation Coefficient (MCC) of 73.54%, and AUC of 95.24%. The framework's ability to leverage the valuable information in 3D OCT data holds significant potential for enhancing clinical decision support systems and improving patient outcomes in glaucoma management.
BEE-NET: A deep neural network to identify in-the-wild Bodily Expression of Emotions
Feb 21, 2024



In this study, we investigate how environmental factors, specifically the scenes and objects involved, can affect the expression of emotions through body language. To this end, we introduce a novel multi-stream deep convolutional neural network named BEE-NET. We also propose a new late fusion strategy that incorporates meta-information on places and objects as prior knowledge in the learning process. Our proposed probabilistic pooling model leverages this information to generate a joint probability distribution of both available and anticipated non-available contextual information in latent space. Importantly, our fusion strategy is differentiable, allowing for end-to-end training and capturing of hidden associations among data points without requiring further post-processing or regularisation. To evaluate our deep model, we use the Body Language Database (BoLD), which is currently the largest available database for the Automatic Identification of the in-the-wild Bodily Expression of Emotions (AIBEE). Our experimental results demonstrate that our proposed approach surpasses the current state-of-the-art in AIBEE by a margin of 2.07%, achieving an Emotional Recognition Score of 66.33%.
Deep Learning and Computer Vision for Glaucoma Detection: A Review
Jul 31, 2023Glaucoma is the leading cause of irreversible blindness worldwide and poses significant diagnostic challenges due to its reliance on subjective evaluation. However, recent advances in computer vision and deep learning have demonstrated the potential for automated assessment. In this paper, we survey recent studies on AI-based glaucoma diagnosis using fundus, optical coherence tomography, and visual field images, with a particular emphasis on deep learning-based methods. We provide an updated taxonomy that organizes methods into architectural paradigms and includes links to available source code to enhance the reproducibility of the methods. Through rigorous benchmarking on widely-used public datasets, we reveal performance gaps in generalizability, uncertainty estimation, and multimodal integration. Additionally, our survey curates key datasets while highlighting limitations such as scale, labeling inconsistencies, and bias. We outline open research challenges and detail promising directions for future studies. This survey is expected to be useful for both AI researchers seeking to translate advances into practice and ophthalmologists aiming to improve clinical workflows and diagnosis using the latest AI outcomes.
Explanation Shift: Investigating Interactions between Models and Shifting Data Distributions
Mar 14, 2023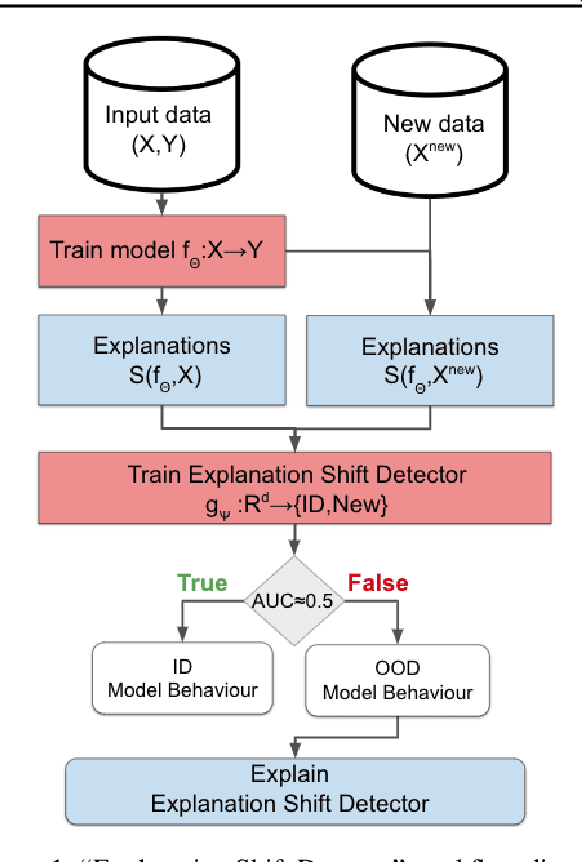
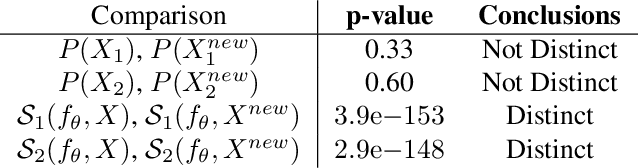
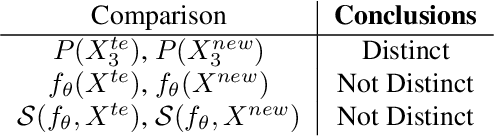
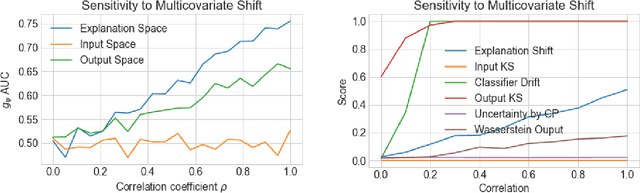
As input data distributions evolve, the predictive performance of machine learning models tends to deteriorate. In practice, new input data tend to come without target labels. Then, state-of-the-art techniques model input data distributions or model prediction distributions and try to understand issues regarding the interactions between learned models and shifting distributions. We suggest a novel approach that models how explanation characteristics shift when affected by distribution shifts. We find that the modeling of explanation shifts can be a better indicator for detecting out-of-distribution model behaviour than state-of-the-art techniques. We analyze different types of distribution shifts using synthetic examples and real-world data sets. We provide an algorithmic method that allows us to inspect the interaction between data set features and learned models and compare them to the state-of-the-art. We release our methods in an open-source Python package, as well as the code used to reproduce our experiments.
ADVISE: ADaptive Feature Relevance and VISual Explanations for Convolutional Neural Networks
Mar 02, 2022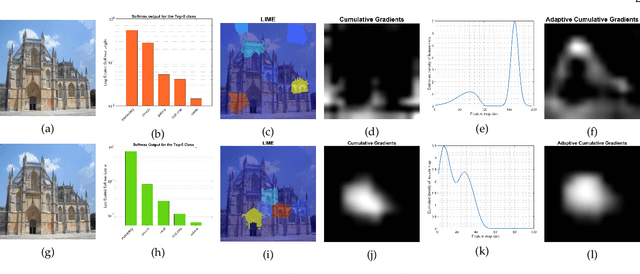
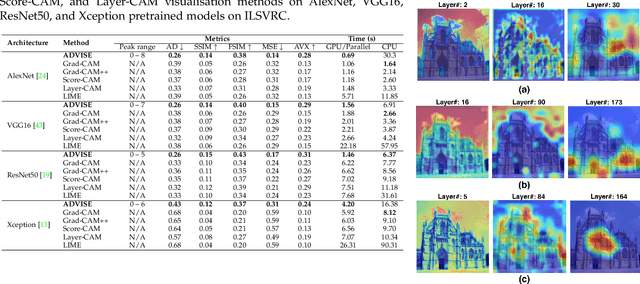
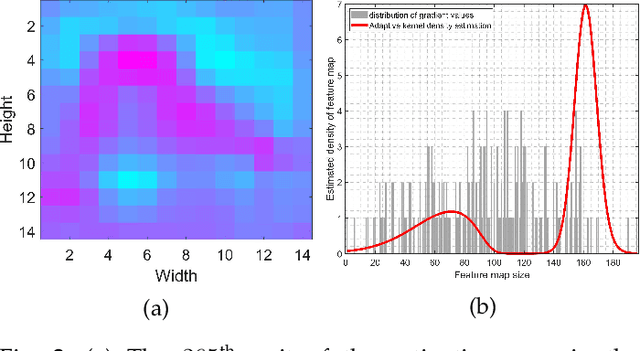
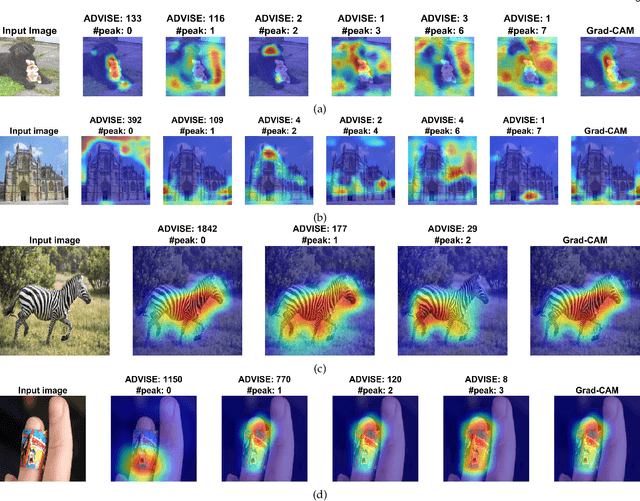
To equip Convolutional Neural Networks (CNNs) with explainability, it is essential to interpret how opaque models take specific decisions, understand what causes the errors, improve the architecture design, and identify unethical biases in the classifiers. This paper introduces ADVISE, a new explainability method that quantifies and leverages the relevance of each unit of the feature map to provide better visual explanations. To this end, we propose using adaptive bandwidth kernel density estimation to assign a relevance score to each unit of the feature map with respect to the predicted class. We also propose an evaluation protocol to quantitatively assess the visual explainability of CNN models. We extensively evaluate our idea in the image classification task using AlexNet, VGG16, ResNet50, and Xception pretrained on ImageNet. We compare ADVISE with the state-of-the-art visual explainable methods and show that the proposed method outperforms competing approaches in quantifying feature-relevance and visual explainability while maintaining competitive time complexity. Our experiments further show that ADVISE fulfils the sensitivity and implementation independence axioms while passing the sanity checks. The implementation is accessible for reproducibility purposes on https://github.com/dehshibi/ADVISE.
Explainable, automated urban interventions to improve pedestrian and vehicle safety
Nov 08, 2021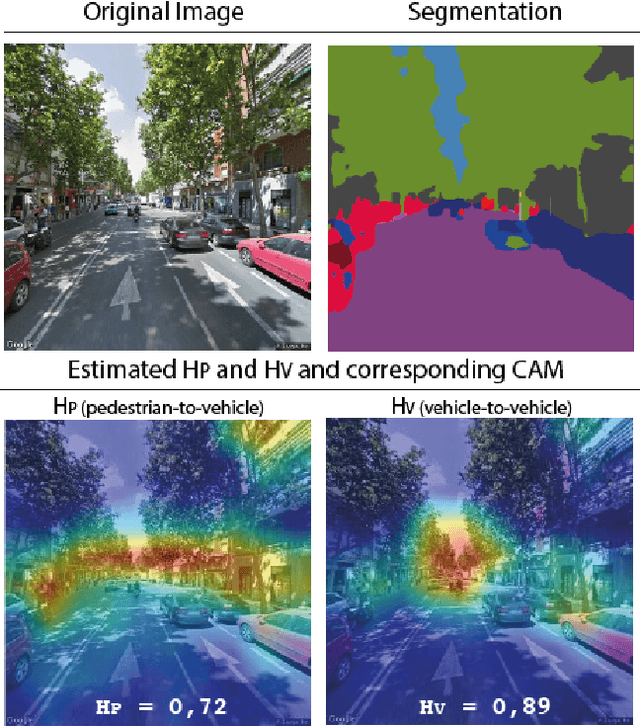
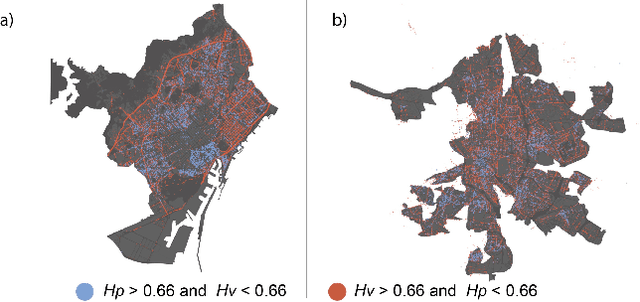
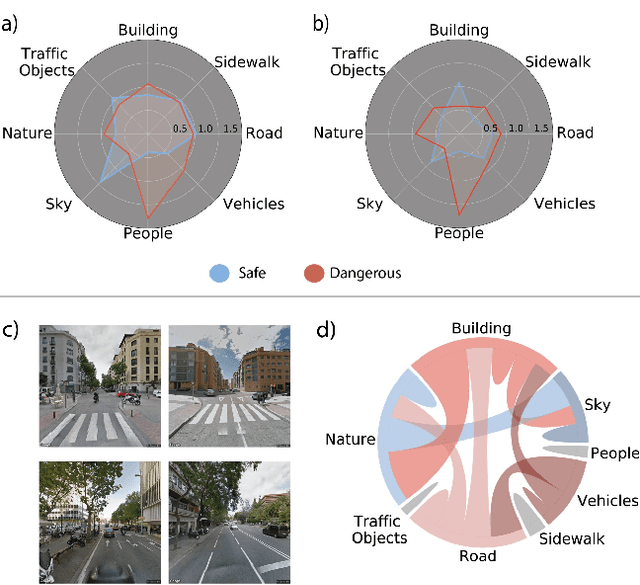
At the moment, urban mobility research and governmental initiatives are mostly focused on motor-related issues, e.g. the problems of congestion and pollution. And yet, we can not disregard the most vulnerable elements in the urban landscape: pedestrians, exposed to higher risks than other road users. Indeed, safe, accessible, and sustainable transport systems in cities are a core target of the UN's 2030 Agenda. Thus, there is an opportunity to apply advanced computational tools to the problem of traffic safety, in regards especially to pedestrians, who have been often overlooked in the past. This paper combines public data sources, large-scale street imagery and computer vision techniques to approach pedestrian and vehicle safety with an automated, relatively simple, and universally-applicable data-processing scheme. The steps involved in this pipeline include the adaptation and training of a Residual Convolutional Neural Network to determine a hazard index for each given urban scene, as well as an interpretability analysis based on image segmentation and class activation mapping on those same images. Combined, the outcome of this computational approach is a fine-grained map of hazard levels across a city, and an heuristic to identify interventions that might simultaneously improve pedestrian and vehicle safety. The proposed framework should be taken as a complement to the work of urban planners and public authorities.
A deep convolutional neural network for classification of Aedes albopictus mosquitoes
Oct 29, 2021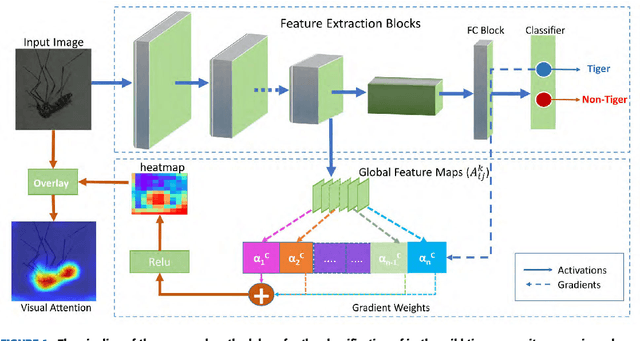
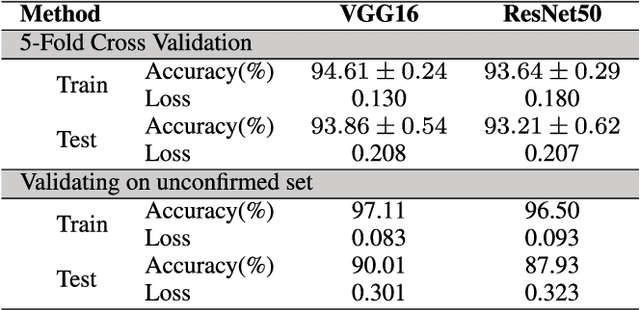
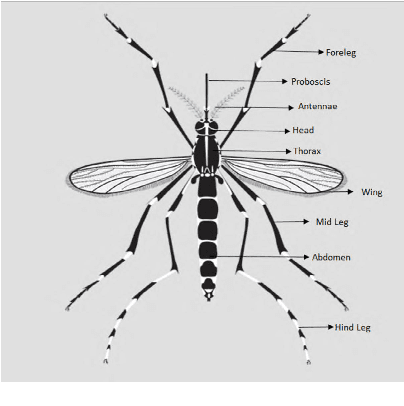

Monitoring the spread of disease-carrying mosquitoes is a first and necessary step to control severe diseases such as dengue, chikungunya, Zika or yellow fever. Previous citizen science projects have been able to obtain large image datasets with linked geo-tracking information. As the number of international collaborators grows, the manual annotation by expert entomologists of the large amount of data gathered by these users becomes too time demanding and unscalable, posing a strong need for automated classification of mosquito species from images. We introduce the application of two Deep Convolutional Neural Networks in a comparative study to automate this classification task. We use the transfer learning principle to train two state-of-the-art architectures on the data provided by the Mosquito Alert project, obtaining testing accuracy of 94%. In addition, we applied explainable models based on the Grad-CAM algorithm to visualise the most discriminant regions of the classified images, which coincide with the white band stripes located at the legs, abdomen, and thorax of mosquitoes of the Aedes albopictus species. The model allows us to further analyse the classification errors. Visual Grad-CAM models show that they are linked to poor acquisition conditions and strong image occlusions.
On the use of uncertainty in classifying Aedes Albopictus mosquitoes
Oct 29, 2021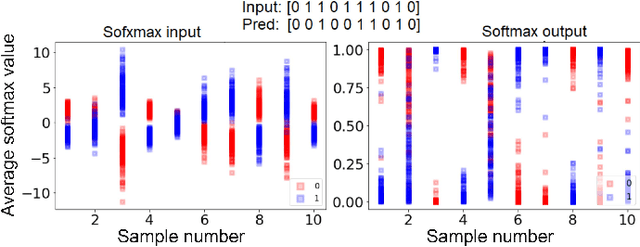
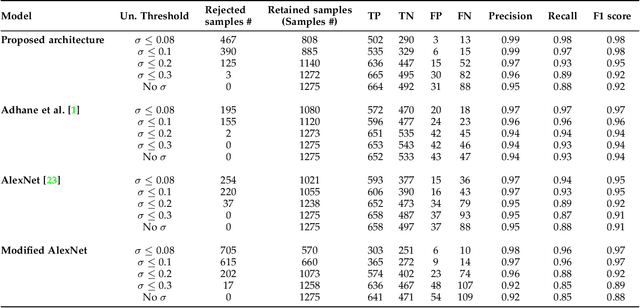


The re-emergence of mosquito-borne diseases (MBDs), which kill hundreds of thousands of people each year, has been attributed to increased human population, migration, and environmental changes. Convolutional neural networks (CNNs) have been used by several studies to recognise mosquitoes in images provided by projects such as Mosquito Alert to assist entomologists in identifying, monitoring, and managing MBD. Nonetheless, utilising CNNs to automatically label input samples could involve incorrect predictions, which may mislead future epidemiological studies. Furthermore, CNNs require large numbers of manually annotated data. In order to address the mentioned issues, this paper proposes using the Monte Carlo Dropout method to estimate the uncertainty scores in order to rank the classified samples to reduce the need for human supervision in recognising Aedes albopictus mosquitoes. The estimated uncertainty was also used in an active learning framework, where just a portion of the data from large training sets was manually labelled. The experimental results show that the proposed classification method with rejection outperforms the competing methods by improving overall performance and reducing entomologist annotation workload. We also provide explainable visualisations of the different regions that contribute to a set of samples' uncertainty assessment.
Quantile Encoder: Tackling High Cardinality Categorical Features in Regression Problems
May 27, 2021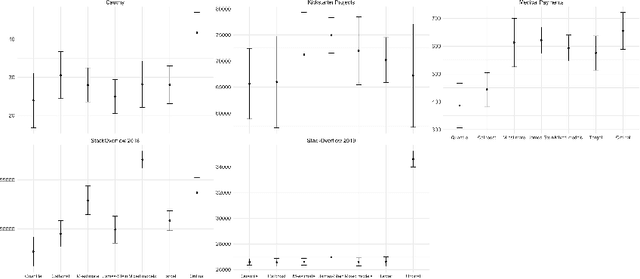
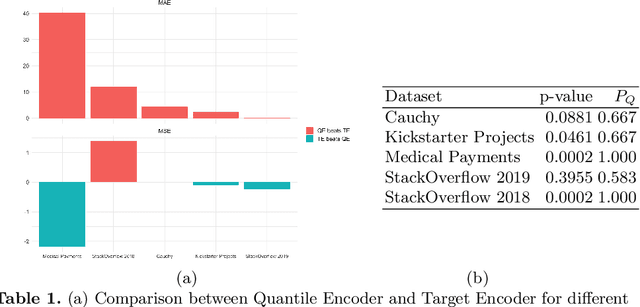
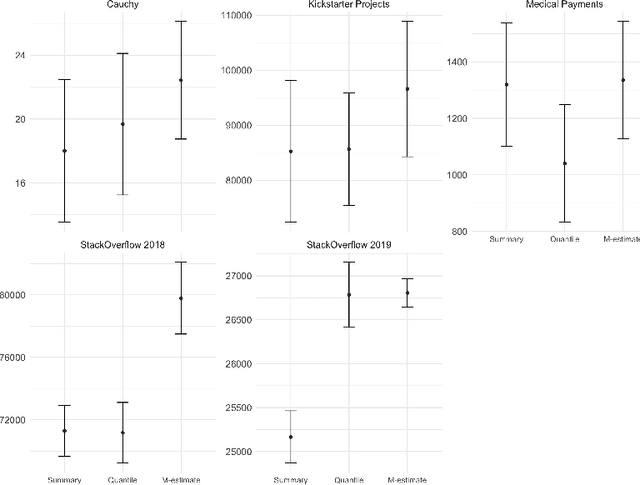
Regression problems have been widely studied in machinelearning literature resulting in a plethora of regression models and performance measures. However, there are few techniques specially dedicated to solve the problem of how to incorporate categorical features to regression problems. Usually, categorical feature encoders are general enough to cover both classification and regression problems. This lack of specificity results in underperforming regression models. In this paper,we provide an in-depth analysis of how to tackle high cardinality categor-ical features with the quantile. Our proposal outperforms state-of-the-encoders, including the traditional statistical mean target encoder, when considering the Mean Absolute Error, especially in the presence of long-tailed or skewed distributions. Besides, to deal with possible overfitting when there are categories with small support, our encoder benefits from additive smoothing. Finally, we describe how to expand the encoded values by creating a set of features with different quantiles. This expanded encoder provides a more informative output about the categorical feature in question, further boosting the performance of the regression model.