 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the use of Vision-Language models for Visual Sentiment Analysis: a study on CLIP
Oct 18, 2023This work presents a study on how to exploit the CLIP embedding space to perform Visual Sentiment Analysis. We experiment with two architectures built on top of the CLIP embedding space, which we denote by CLIP-E. We train the CLIP-E models with WEBEmo, the largest publicly available and manually labeled benchmark for Visual Sentiment Analysis, and perform two sets of experiments. First, we test on WEBEmo and compare the CLIP-E architectures with state-of-the-art (SOTA) models and with CLIP Zero-Shot. Second, we perform cross dataset evaluation, and test the CLIP-E architectures trained with WEBEmo on other Visual Sentiment Analysis benchmarks. Our results show that the CLIP-E approaches outperform SOTA models in WEBEmo fine grained categorization, and they also generalize better when tested on datasets that have not been seen during training. Interestingly, we observed that for the FI dataset, CLIP Zero-Shot produces better accuracies than SOTA models and CLIP-E trained on WEBEmo. These results motivate several questions that we discuss in this paper, such as how we should design new benchmarks and evaluate Visual Sentiment Analysis, and whether we should keep designing tailored Deep Learning models for Visual Sentiment Analysis or focus our efforts on better using the knowledge encoded in large vision-language models such as CLIP for this task.
Explainable, automated urban interventions to improve pedestrian and vehicle safety
Nov 08, 2021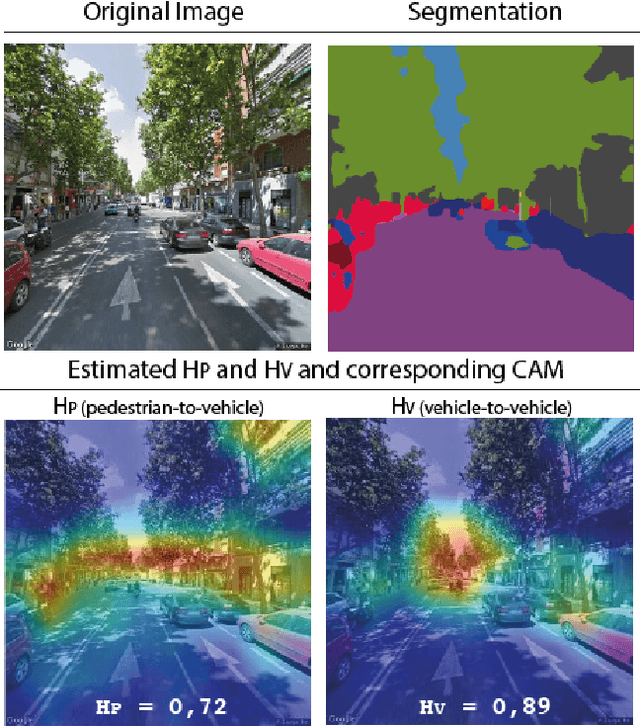
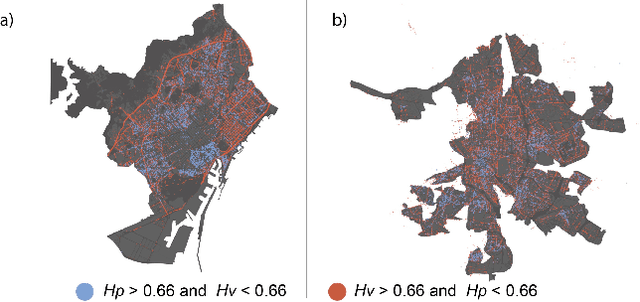
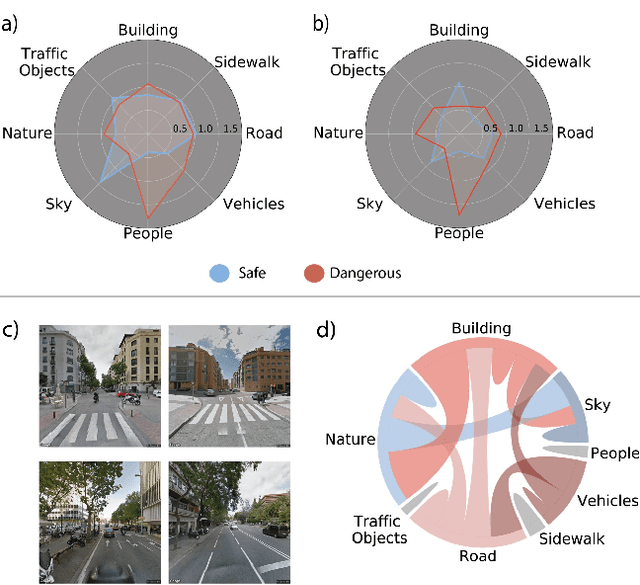
At the moment, urban mobility research and governmental initiatives are mostly focused on motor-related issues, e.g. the problems of congestion and pollution. And yet, we can not disregard the most vulnerable elements in the urban landscape: pedestrians, exposed to higher risks than other road users. Indeed, safe, accessible, and sustainable transport systems in cities are a core target of the UN's 2030 Agenda. Thus, there is an opportunity to apply advanced computational tools to the problem of traffic safety, in regards especially to pedestrians, who have been often overlooked in the past. This paper combines public data sources, large-scale street imagery and computer vision techniques to approach pedestrian and vehicle safety with an automated, relatively simple, and universally-applicable data-processing scheme. The steps involved in this pipeline include the adaptation and training of a Residual Convolutional Neural Network to determine a hazard index for each given urban scene, as well as an interpretability analysis based on image segmentation and class activation mapping on those same images. Combined, the outcome of this computational approach is a fine-grained map of hazard levels across a city, and an heuristic to identify interventions that might simultaneously improve pedestrian and vehicle safety. The proposed framework should be taken as a complement to the work of urban planners and public authorities.
Predicting Driver Self-Reported Stress by Analyzing the Road Scene
Sep 27, 2021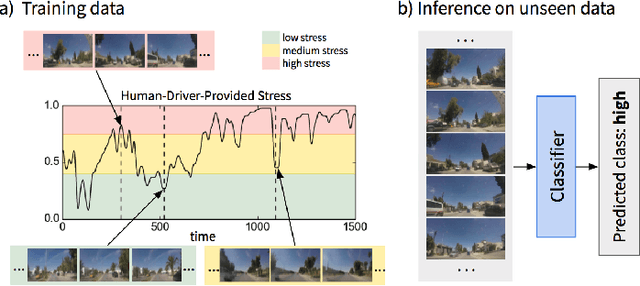
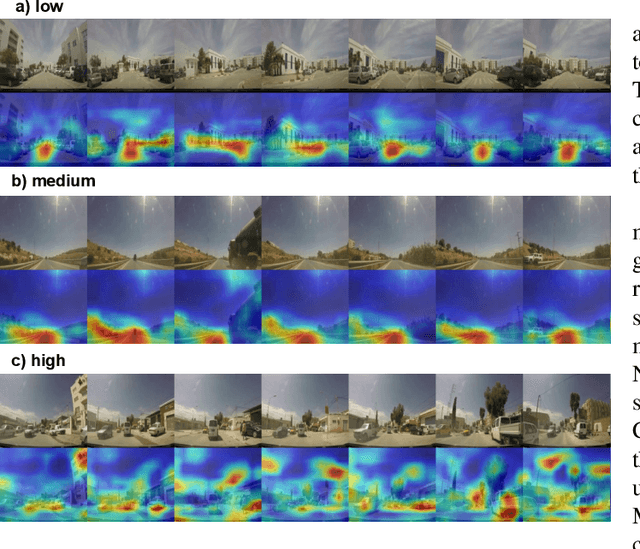
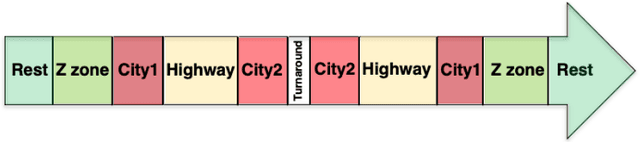
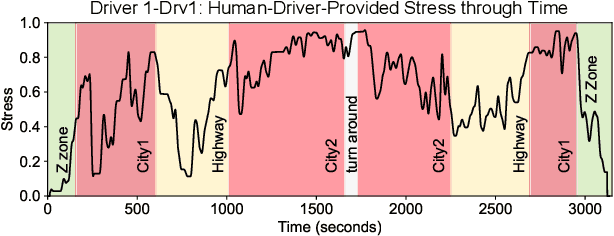
Several studies have shown the relevance of biosignals in driver stress recognition. In this work, we examine something important that has been less frequently explored: We develop methods to test if the visual driving scene can be used to estimate a drivers' subjective stress levels. For this purpose, we use the AffectiveROAD video recordings and their corresponding stress labels, a continuous human-driver-provided stress metric. We use the common class discretization for stress, dividing its continuous values into three classes: low, medium, and high. We design and evaluate three computer vision modeling approaches to classify the driver's stress levels: (1) object presence features, where features are computed using automatic scene segmentation; (2) end-to-end image classification; and (3) end-to-end video classification. All three approaches show promising results, suggesting that it is possible to approximate the drivers' subjective stress from the information found in the visual scene. We observe that the video classification, which processes the temporal information integrated with the visual information, obtains the highest accuracy of $0.72$, compared to a random baseline accuracy of $0.33$ when tested on a set of nine drivers.