 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-aware Transformer-GRU Framework for Enhanced Glaucoma Diagnosis from 3D OCT Imaging
Mar 08, 2024Glaucoma, a leading cause of irreversible blindness, necessitates early detection for accurate and timely intervention to prevent irreversible vision loss. In this study, we present a novel deep learning framework that leverages the diagnostic value of 3D Optical Coherence Tomography (OCT) imaging for automated glaucoma detection. In this framework, we integrate a pre-trained Vision Transformer on retinal data for rich slice-wise feature extraction and a bidirectional Gated Recurrent Unit for capturing inter-slice spatial dependencies. This dual-component approach enables comprehensive analysis of local nuances and global structural integrity, crucial for accurate glaucoma diagnosis. Experimental results on a large dataset demonstrate the superior performance of the proposed method over state-of-the-art ones, achieving an F1-score of 93.58%, Matthews Correlation Coefficient (MCC) of 73.54%, and AUC of 95.24%. The framework's ability to leverage the valuable information in 3D OCT data holds significant potential for enhancing clinical decision support systems and improving patient outcomes in glaucoma management.
Deep Learning and Computer Vision for Glaucoma Detection: A Review
Jul 31, 2023Glaucoma is the leading cause of irreversible blindness worldwide and poses significant diagnostic challenges due to its reliance on subjective evaluation. However, recent advances in computer vision and deep learning have demonstrated the potential for automated assessment. In this paper, we survey recent studies on AI-based glaucoma diagnosis using fundus, optical coherence tomography, and visual field images, with a particular emphasis on deep learning-based methods. We provide an updated taxonomy that organizes methods into architectural paradigms and includes links to available source code to enhance the reproducibility of the methods. Through rigorous benchmarking on widely-used public datasets, we reveal performance gaps in generalizability, uncertainty estimation, and multimodal integration. Additionally, our survey curates key datasets while highlighting limitations such as scale, labeling inconsistencies, and bias. We outline open research challenges and detail promising directions for future studies. This survey is expected to be useful for both AI researchers seeking to translate advances into practice and ophthalmologists aiming to improve clinical workflows and diagnosis using the latest AI outcomes.
A multi-stream convolutional neural network for classification of progressive MCI in Alzheimer's disease using structural MRI images
Mar 03, 2022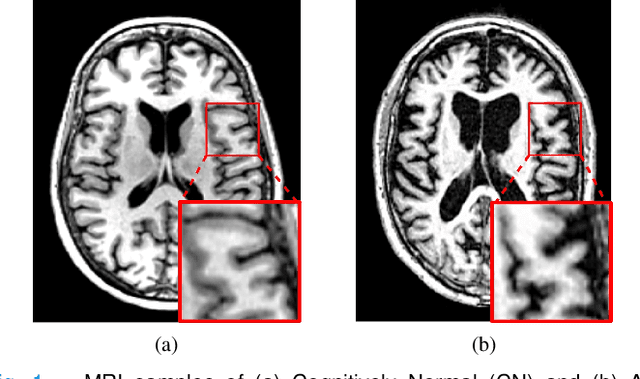
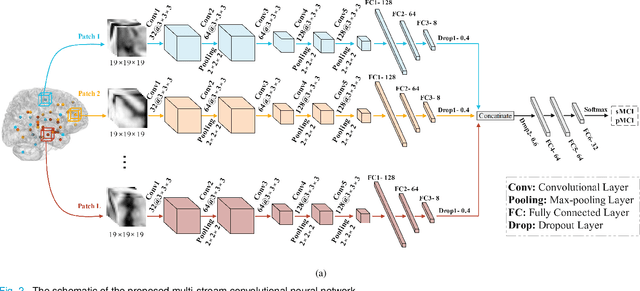

Early diagnosis of Alzheimer's disease and its prodromal stage, also known as mild cognitive impairment (MCI), is critical since some patients with progressive MCI will develop the disease. We propose a multi-stream deep convolutional neural network fed with patch-based imaging data to classify stable MCI and progressive MCI. First, we compare MRI images of Alzheimer's disease with cognitively normal subjects to identify distinct anatomical landmarks using a multivariate statistical test. These landmarks are then used to extract patches that are fed into the proposed multi-stream convolutional neural network to classify MRI images. Next, we train the architecture in a separate scenario using samples from Alzheimer's disease images, which are anatomically similar to the progressive MCI ones and cognitively normal images to compensate for the lack of progressive MCI training data. Finally, we transfer the trained model weights to the proposed architecture in order to fine-tune the model using progressive MCI and stable MCI data. Experimental results on the ADNI-1 dataset indicate that our method outperforms existing methods for MCI classification, with an F1-score of 85.96%.
ADVISE: ADaptive Feature Relevance and VISual Explanations for Convolutional Neural Networks
Mar 02, 2022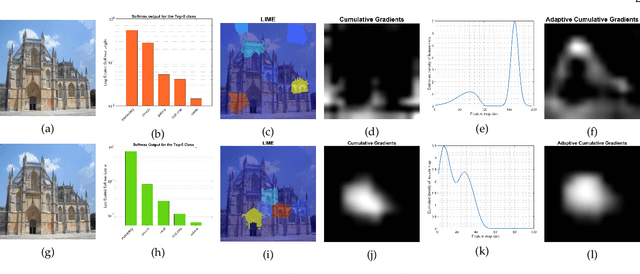
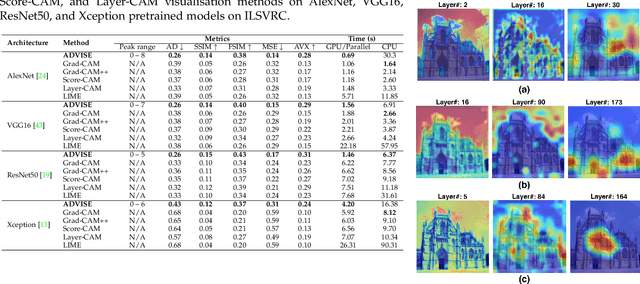
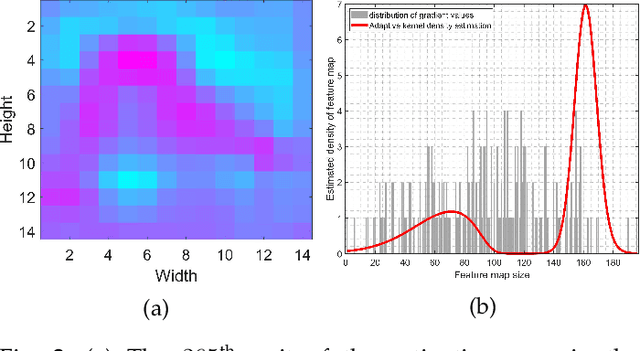
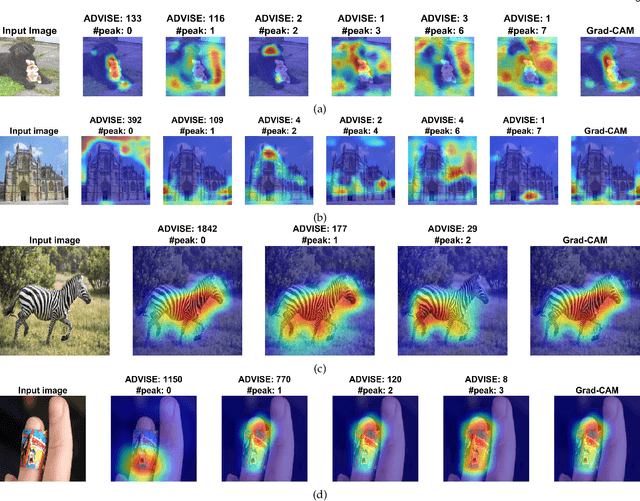
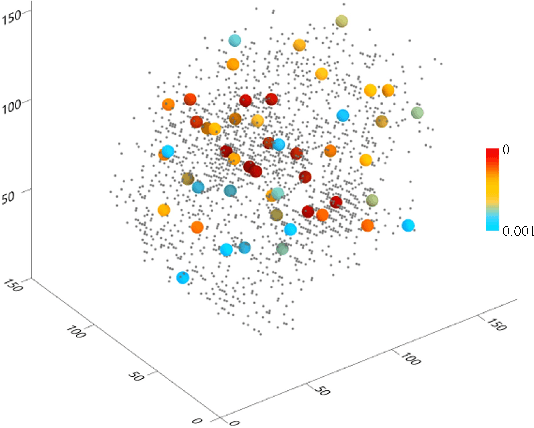
To equip Convolutional Neural Networks (CNNs) with explainability, it is essential to interpret how opaque models take specific decisions, understand what causes the errors, improve the architecture design, and identify unethical biases in the classifiers. This paper introduces ADVISE, a new explainability method that quantifies and leverages the relevance of each unit of the feature map to provide better visual explanations. To this end, we propose using adaptive bandwidth kernel density estimation to assign a relevance score to each unit of the feature map with respect to the predicted class. We also propose an evaluation protocol to quantitatively assess the visual explainability of CNN models. We extensively evaluate our idea in the image classification task using AlexNet, VGG16, ResNet50, and Xception pretrained on ImageNet. We compare ADVISE with the state-of-the-art visual explainable methods and show that the proposed method outperforms competing approaches in quantifying feature-relevance and visual explainability while maintaining competitive time complexity. Our experiments further show that ADVISE fulfils the sensitivity and implementation independence axioms while passing the sanity checks. The implementation is accessible for reproducibility purposes on https://github.com/dehshibi/ADVISE.