 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Explaining Knowledge Distillation: Measuring and Visualising the Knowledge Transfer Process
Dec 18, 2024
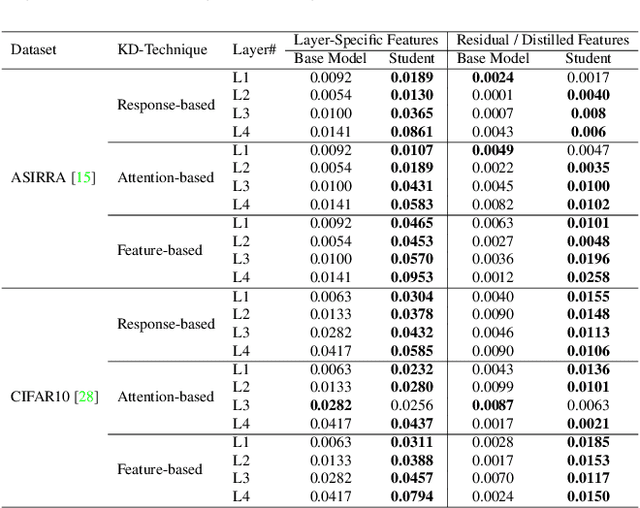
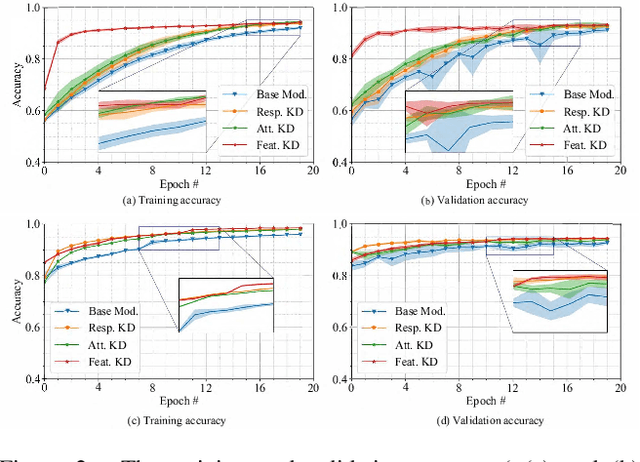
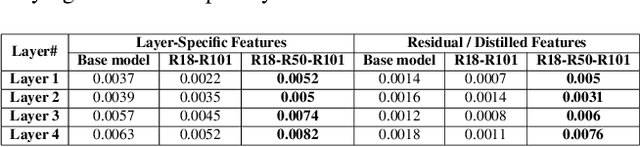
Knowledge distillation (KD) remains challenging due to the opaque nature of the knowledge transfer process from a Teacher to a Student, making it difficult to address certain issues related to KD. To address this, we proposed UniCAM, a novel gradient-based visual explanation method, which effectively interprets the knowledge learned during KD. Our experimental results demonstrate that with the guidance of the Teacher's knowledge, the Student model becomes more efficient, learning more relevant features while discarding those that are not relevant. We refer to the features learned with the Teacher's guidance as distilled features and the features irrelevant to the task and ignored by the Student as residual features. Distilled features focus on key aspects of the input, such as textures and parts of objects. In contrast, residual features demonstrate more diffused attention, often targeting irrelevant areas, including the backgrounds of the target objects. In addition, we proposed two novel metrics: the feature similarity score (FSS) and the relevance score (RS), which quantify the relevance of the distilled knowledge. Experiments on the CIFAR10, ASIRRA, and Plant Disease datasets demonstrate that UniCAM and the two metrics offer valuable insights to explain the KD process.
Classification of freshwater snails of the genus \emph{Radomaniola} with multimodal triplet networks
Jul 29, 2024In this paper, we present our first proposal of a machine learning system for the classification of freshwater snails of the genus \emph{Radomaniola}. We elaborate on the specific challenges encountered during system design, and how we tackled them; namely a small, very imbalanced dataset with a high number of classes and high visual similarity between classes. We then show how we employed triplet networks and the multiple input modalities of images, measurements, and genetic information to overcome these challenges and reach a performance comparable to that of a trained domain expert.
Using Sentence Embeddings and Semantic Similarity for Seeking Consensus when Assessing Trustworthy AI
Aug 09, 2022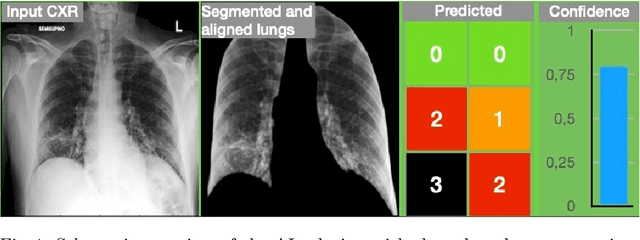

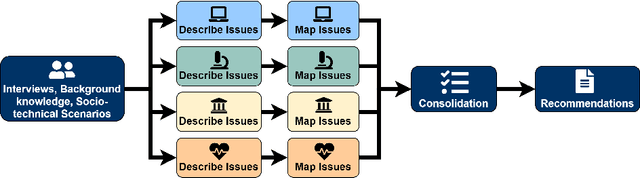
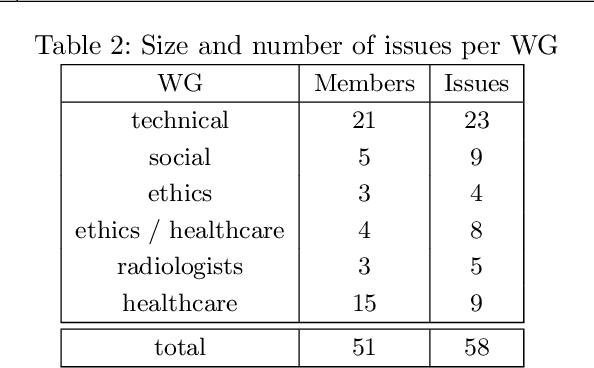
Assessing the trustworthiness of artificial intelligence systems requires knowledge from many different disciplines. These disciplines do not necessarily share concepts between them and might use words with different meanings, or even use the same words differently. Additionally, experts from different disciplines might not be aware of specialized terms readily used in other disciplines. Therefore, a core challenge of the assessment process is to identify when experts from different disciplines talk about the same problem but use different terminologies. In other words, the problem is to group problem descriptions (a.k.a. issues) with the same semantic meaning but described using slightly different terminologies. In this work, we show how we employed recent advances in natural language processing, namely sentence embeddings and semantic textual similarity, to support this identification process and to bridge communication gaps in interdisciplinary teams of experts assessing the trustworthiness of an artificial intelligence system used in healthcare.