 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting Ready for the EU AI Act in Healthcare. A call for Sustainable AI Development and Deployment
May 10, 2025Assessments of trustworthiness have become a cornerstone of responsible AI development. Especially in high-stakes fields like healthcare, aligning technical, evidence-based, and ethical practices with forthcoming legal requirements is increasingly urgent. We argue that developers and deployers of AI systems for the medical domain should be proactive and take steps to progressively ensure that such systems, both those currently in use and those being developed or planned, respect the requirements of the AI Act, which has come into force in August 2024. This is necessary if full and effective compliance is to be ensured when the most relevant provisions of the Act become effective (August 2026). The engagement with the AI Act cannot be viewed as a formalistic exercise. Compliance with the AI Act needs to be carried out through the proactive commitment to the ethical principles of trustworthy AI. These principles provide the background for the Act, which mentions them several times and connects them to the protection of public interest. They can be used to interpret and apply the Act's provisions and to identify good practices, increasing the validity and sustainability of AI systems over time.
Using Sentence Embeddings and Semantic Similarity for Seeking Consensus when Assessing Trustworthy AI
Aug 09, 2022

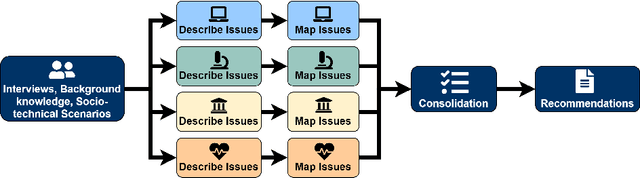
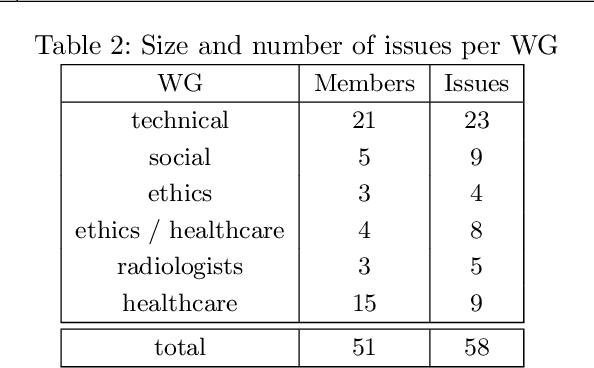
Assessing the trustworthiness of artificial intelligence systems requires knowledge from many different disciplines. These disciplines do not necessarily share concepts between them and might use words with different meanings, or even use the same words differently. Additionally, experts from different disciplines might not be aware of specialized terms readily used in other disciplines. Therefore, a core challenge of the assessment process is to identify when experts from different disciplines talk about the same problem but use different terminologies. In other words, the problem is to group problem descriptions (a.k.a. issues) with the same semantic meaning but described using slightly different terminologies. In this work, we show how we employed recent advances in natural language processing, namely sentence embeddings and semantic textual similarity, to support this identification process and to bridge communication gaps in interdisciplinary teams of experts assessing the trustworthiness of an artificial intelligence system used in healthcare.