 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting Ready for the EU AI Act in Healthcare. A call for Sustainable AI Development and Deployment
May 10, 2025Assessments of trustworthiness have become a cornerstone of responsible AI development. Especially in high-stakes fields like healthcare, aligning technical, evidence-based, and ethical practices with forthcoming legal requirements is increasingly urgent. We argue that developers and deployers of AI systems for the medical domain should be proactive and take steps to progressively ensure that such systems, both those currently in use and those being developed or planned, respect the requirements of the AI Act, which has come into force in August 2024. This is necessary if full and effective compliance is to be ensured when the most relevant provisions of the Act become effective (August 2026). The engagement with the AI Act cannot be viewed as a formalistic exercise. Compliance with the AI Act needs to be carried out through the proactive commitment to the ethical principles of trustworthy AI. These principles provide the background for the Act, which mentions them several times and connects them to the protection of public interest. They can be used to interpret and apply the Act's provisions and to identify good practices, increasing the validity and sustainability of AI systems over time.
From Single-Hospital to Multi-Centre Applications: Enhancing the Generalisability of Deep Learning Models for Adverse Event Prediction in the ICU
Apr 07, 2023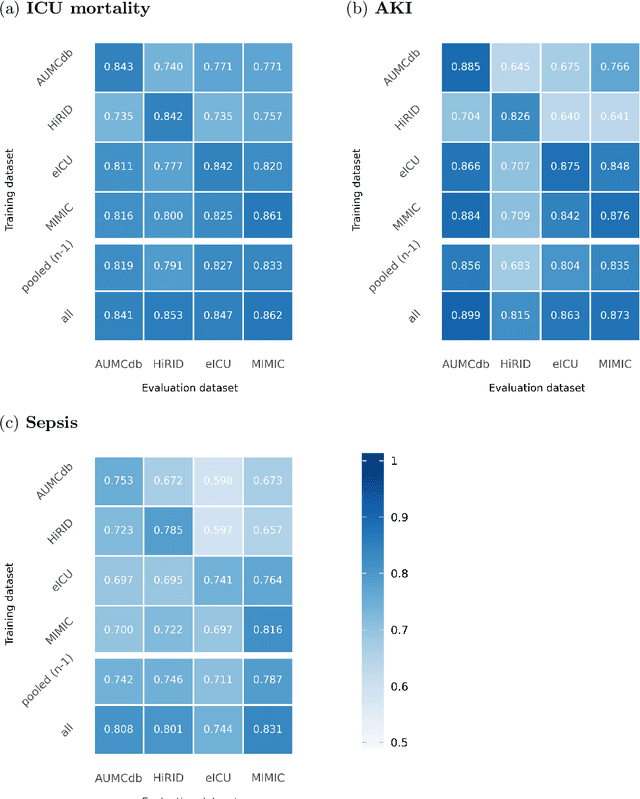

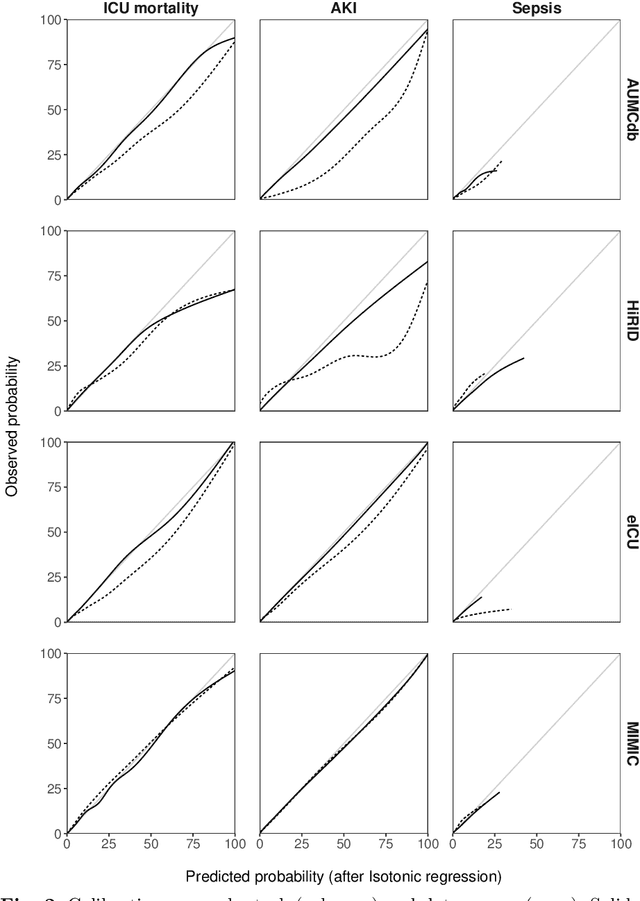
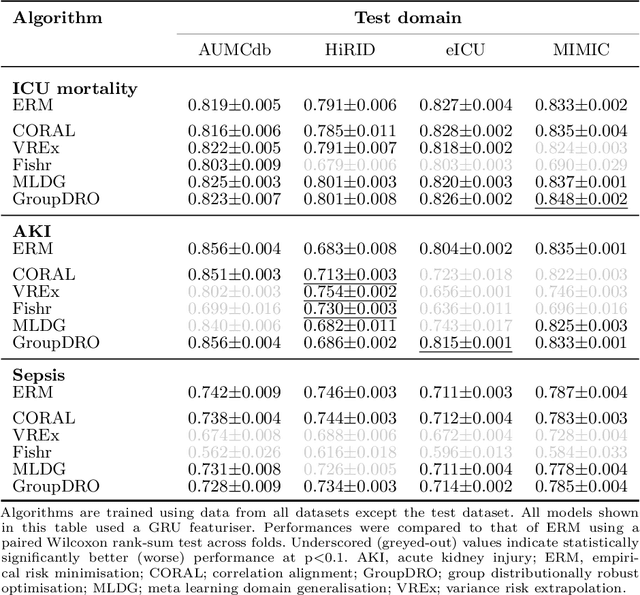
Deep learning (DL) can aid doctors in detecting worsening patient states early, affording them time to react and prevent bad outcomes. While DL-based early warning models usually work well in the hospitals they were trained for, they tend to be less reliable when applied at new hospitals. This makes it difficult to deploy them at scale. Using carefully harmonised intensive care data from four data sources across Europe and the US (totalling 334,812 stays), we systematically assessed the reliability of DL models for three common adverse events: death, acute kidney injury (AKI), and sepsis. We tested whether using more than one data source and/or explicitly optimising for generalisability during training improves model performance at new hospitals. We found that models achieved high AUROC for mortality (0.838-0.869), AKI (0.823-0.866), and sepsis (0.749-0.824) at the training hospital. As expected, performance dropped at new hospitals, sometimes by as much as -0.200. Using more than one data source for training mitigated the performance drop, with multi-source models performing roughly on par with the best single-source model. This suggests that as data from more hospitals become available for training, model robustness is likely to increase, lower-bounding robustness with the performance of the most applicable data source in the training data. Dedicated methods promoting generalisability did not noticeably improve performance in our experiments.
On The Usage Of Average Hausdorff Distance For Segmentation Performance Assessment: Hidden Bias When Used For Ranking
Sep 13, 2020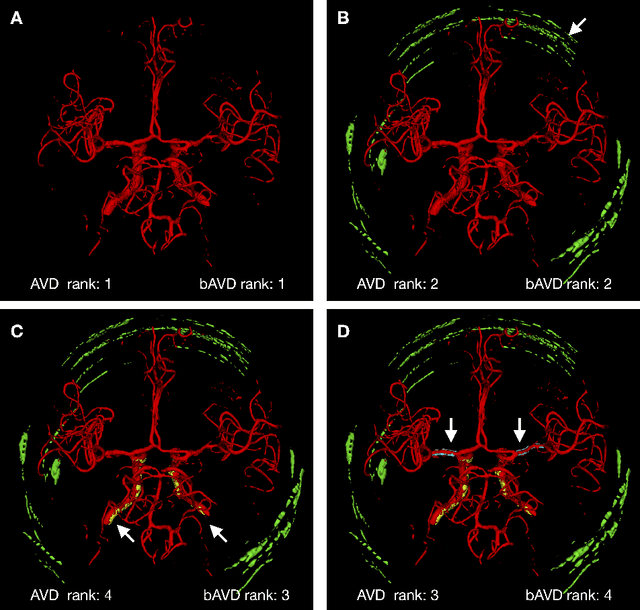
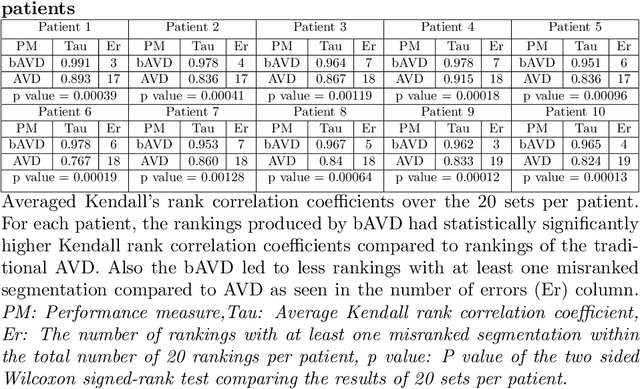
Average Hausdorff Distance (AVD) is a widely used performance measure to calculate the distance between two point sets. In medical image segmentation, AVD is used to compare ground truth images with segmentation results allowing their ranking. We identified, however, a ranking bias of AVD making it less suitable for segmentation ranking. To mitigate this bias, we present a modified calculation of AVD that we have coined balanced AVD (bAVD). To simulate segmentations for ranking, we manually created non-overlapping segmentation errors common in cerebral vessel segmentation as our use-case. Adding the created errors consecutively and randomly to the ground truth, we created sets of simulated segmentations with increasing number of errors. Each set of simulated segmentations was ranked using AVD and bAVD. We calculated the Kendall-rank-correlation-coefficient between the segmentation ranking and the number of errors in each simulated segmentation. The rankings produced by bAVD had a significantly higher average correlation (0.969) than those of AVD (0.847). In 200 total rankings, bAVD misranked 52 and AVD misranked 179 segmentations. Our proposed evaluation measure, bAVD, alleviates AVDs ranking bias making it more suitable for rankings and quality assessment of segmentations.