 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELICT: A Replica Detection Framework for Medical Image Generation
Feb 24, 2025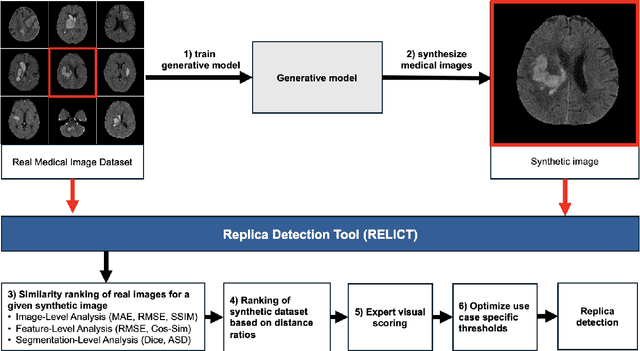
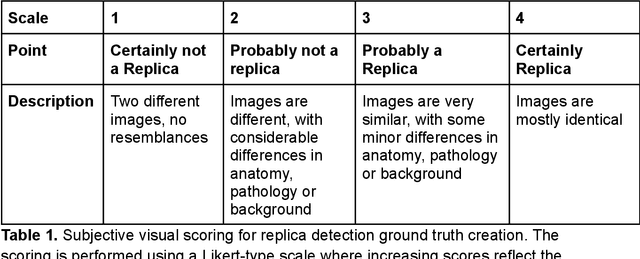
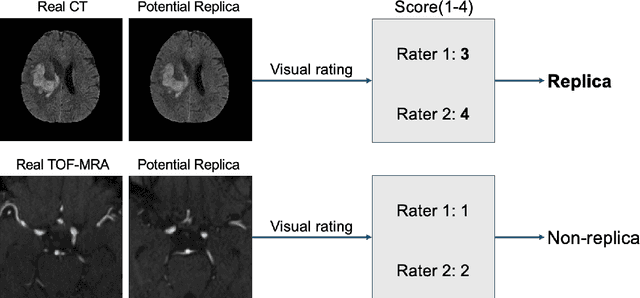
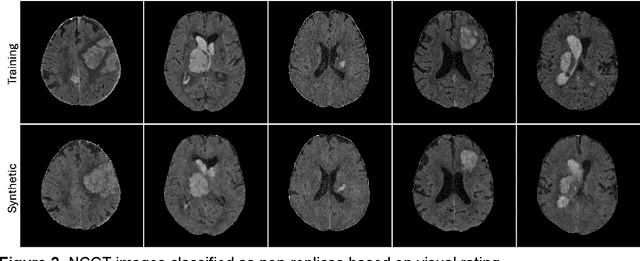
Despite the potential of synthetic medical data for augmenting and improving the generalizability of deep learning models, memorization in generative models can lead to unintended leakage of sensitive patient information and limit model utility. Thus, the use of memorizing generative models in the medical domain can jeopardize patient privacy. We propose a framework for identifying replicas, i.e. nearly identical copies of the training data, in synthetic medical image datasets. Our REpLIca deteCTion (RELICT) framework for medical image generative models evaluates image similarity using three complementary approaches: (1) voxel-level analysis, (2) feature-level analysis by a pretrained medical foundation model, and (3) segmentation-level analysis. Two clinically relevant 3D generative modelling use cases were investigated: non-contrast head CT with intracerebral hemorrhage (N=774) and time-of-flight MR angiography of the Circle of Willis (N=1,782). Expert visual scoring was used as the reference standard to assess the presence of replicas. We report the balanced accuracy at the optimal threshold to assess replica classification performance. The reference visual rating identified 45 of 50 and 5 of 50 generated images as replicas for the NCCT and TOF-MRA use cases, respectively. Image-level and feature-level measures perfectly classified replicas with a balanced accuracy of 1 when an optimal threshold was selected for the NCCT use case. A perfect classification of replicas for the TOF-MRA case was not possible at any threshold, with the segmentation-level analysis achieving a balanced accuracy of 0.79. Replica detection is a crucial but neglected validation step for the development of generative models in medical imaging. The proposed RELICT framework provides a standardized, easy-to-use tool for replica detection and aims to facilitate responsible and ethical medical image synthesis.
Cross-modality image synthesis from TOF-MRA to CTA using diffusion-based models
Sep 16, 2024



Cerebrovascular disease often requires multiple imaging modalities for accurate diagnosis, treatment, and monitoring. Computed Tomography Angiography (CTA) and Time-of-Flight Magnetic Resonance Angiography (TOF-MRA) are two common non-invasive angiography techniques, each with distinct strengths in accessibility, safety, and diagnostic accuracy. While CTA is more widely used in acute stroke due to its faster acquisition times and higher diagnostic accuracy, TOF-MRA is preferred for its safety, as it avoids radiation exposure and contrast agent-related health risks. Despite the predominant role of CTA in clinical workflows, there is a scarcity of open-source CTA data, limiting the research and development of AI models for tasks such as large vessel occlusion detection and aneurysm segmentation. This study explores diffusion-based image-to-image translation models to generate synthetic CTA images from TOF-MRA input. We demonstrate the modality conversion from TOF-MRA to CTA and show that diffusion models outperform a traditional U-Net-based approach. Our work compares different state-of-the-art diffusion architectures and samplers, offering recommendations for optimal model performance in this cross-modality translation task.
On The Usage Of Average Hausdorff Distance For Segmentation Performance Assessment: Hidden Bias When Used For Ranking
Sep 13, 2020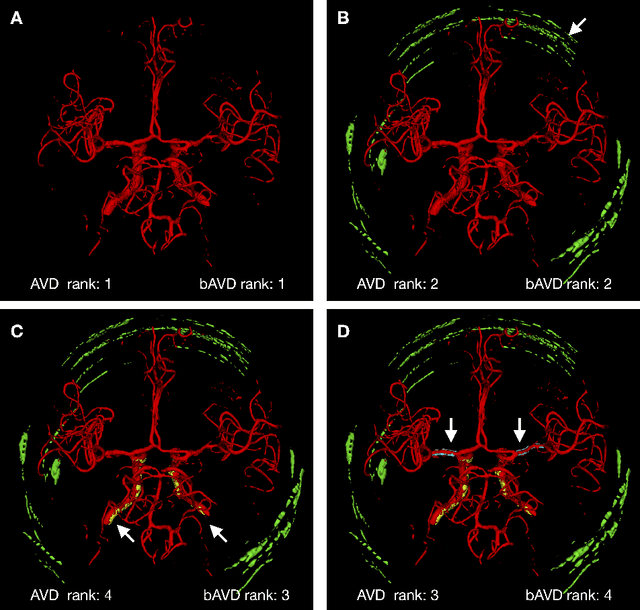
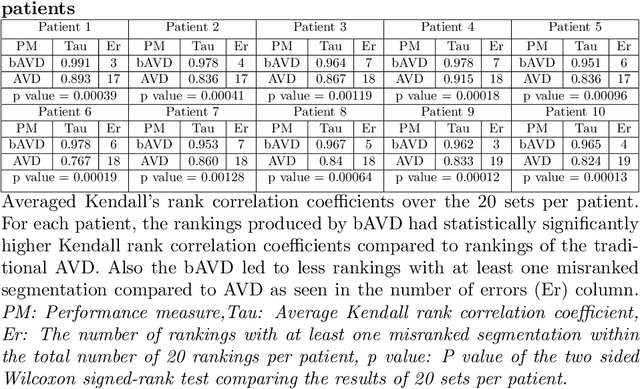
Average Hausdorff Distance (AVD) is a widely used performance measure to calculate the distance between two point sets. In medical image segmentation, AVD is used to compare ground truth images with segmentation results allowing their ranking. We identified, however, a ranking bias of AVD making it less suitable for segmentation ranking. To mitigate this bias, we present a modified calculation of AVD that we have coined balanced AVD (bAVD). To simulate segmentations for ranking, we manually created non-overlapping segmentation errors common in cerebral vessel segmentation as our use-case. Adding the created errors consecutively and randomly to the ground truth, we created sets of simulated segmentations with increasing number of errors. Each set of simulated segmentations was ranked using AVD and bAVD. We calculated the Kendall-rank-correlation-coefficient between the segmentation ranking and the number of errors in each simulated segmentation. The rankings produced by bAVD had a significantly higher average correlation (0.969) than those of AVD (0.847). In 200 total rankings, bAVD misranked 52 and AVD misranked 179 segmentations. Our proposed evaluation measure, bAVD, alleviates AVDs ranking bias making it more suitable for rankings and quality assessment of segmentations.