 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELICT: A Replica Detection Framework for Medical Image Generation
Feb 24, 2025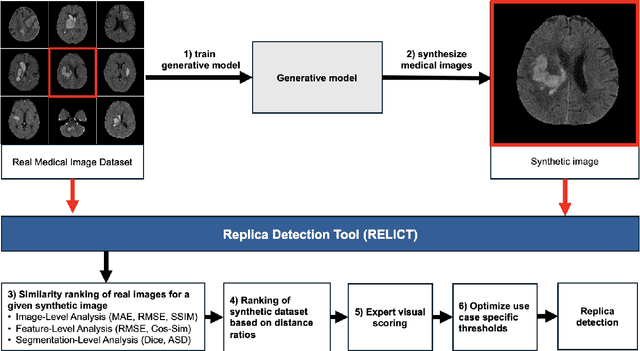
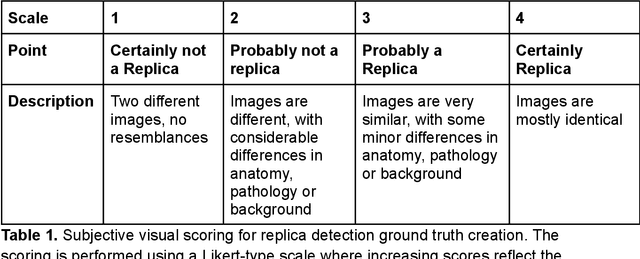
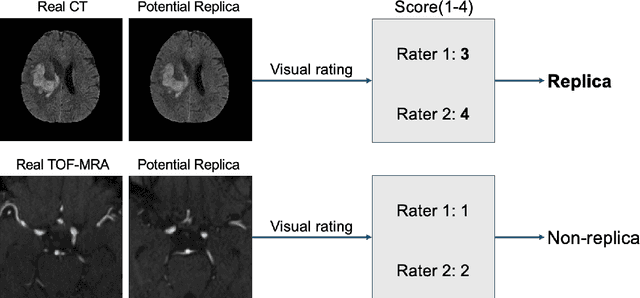
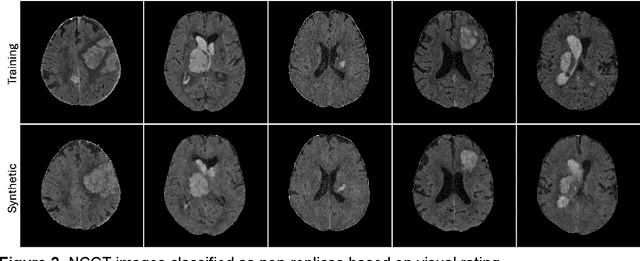
Despite the potential of synthetic medical data for augmenting and improving the generalizability of deep learning models, memorization in generative models can lead to unintended leakage of sensitive patient information and limit model utility. Thus, the use of memorizing generative models in the medical domain can jeopardize patient privacy. We propose a framework for identifying replicas, i.e. nearly identical copies of the training data, in synthetic medical image datasets. Our REpLIca deteCTion (RELICT) framework for medical image generative models evaluates image similarity using three complementary approaches: (1) voxel-level analysis, (2) feature-level analysis by a pretrained medical foundation model, and (3) segmentation-level analysis. Two clinically relevant 3D generative modelling use cases were investigated: non-contrast head CT with intracerebral hemorrhage (N=774) and time-of-flight MR angiography of the Circle of Willis (N=1,782). Expert visual scoring was used as the reference standard to assess the presence of replicas. We report the balanced accuracy at the optimal threshold to assess replica classification performance. The reference visual rating identified 45 of 50 and 5 of 50 generated images as replicas for the NCCT and TOF-MRA use cases, respectively. Image-level and feature-level measures perfectly classified replicas with a balanced accuracy of 1 when an optimal threshold was selected for the NCCT use case. A perfect classification of replicas for the TOF-MRA case was not possible at any threshold, with the segmentation-level analysis achieving a balanced accuracy of 0.79. Replica detection is a crucial but neglected validation step for the development of generative models in medical imaging. The proposed RELICT framework provides a standardized, easy-to-use tool for replica detection and aims to facilitate responsible and ethical medical image synthesis.
Cross-modality image synthesis from TOF-MRA to CTA using diffusion-based models
Sep 16, 2024



Cerebrovascular disease often requires multiple imaging modalities for accurate diagnosis, treatment, and monitoring. Computed Tomography Angiography (CTA) and Time-of-Flight Magnetic Resonance Angiography (TOF-MRA) are two common non-invasive angiography techniques, each with distinct strengths in accessibility, safety, and diagnostic accuracy. While CTA is more widely used in acute stroke due to its faster acquisition times and higher diagnostic accuracy, TOF-MRA is preferred for its safety, as it avoids radiation exposure and contrast agent-related health risks. Despite the predominant role of CTA in clinical workflows, there is a scarcity of open-source CTA data, limiting the research and development of AI models for tasks such as large vessel occlusion detection and aneurysm segmentation. This study explores diffusion-based image-to-image translation models to generate synthetic CTA images from TOF-MRA input. We demonstrate the modality conversion from TOF-MRA to CTA and show that diffusion models outperform a traditional U-Net-based approach. Our work compares different state-of-the-art diffusion architectures and samplers, offering recommendations for optimal model performance in this cross-modality translation task.
Meta-Reinforcement Learning via Language Instructions
Sep 15, 2022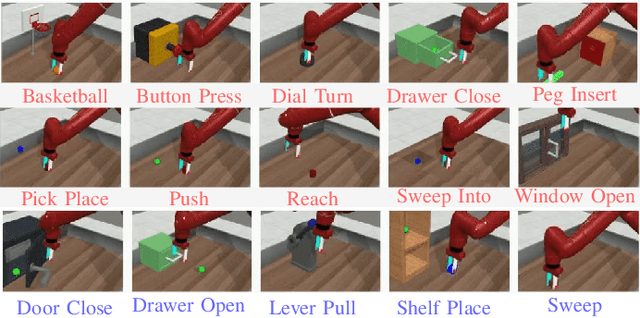
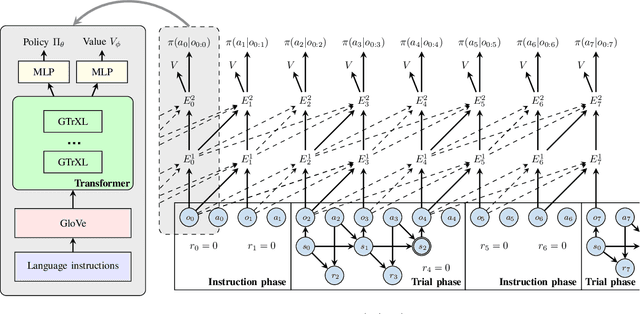
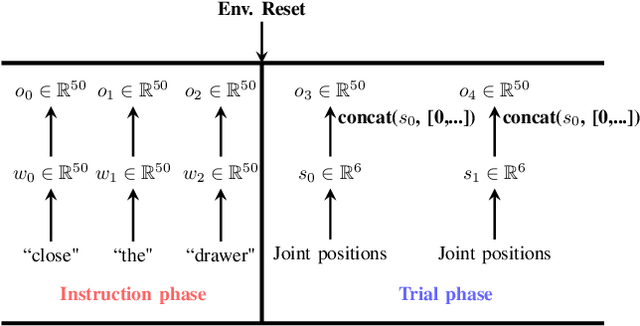
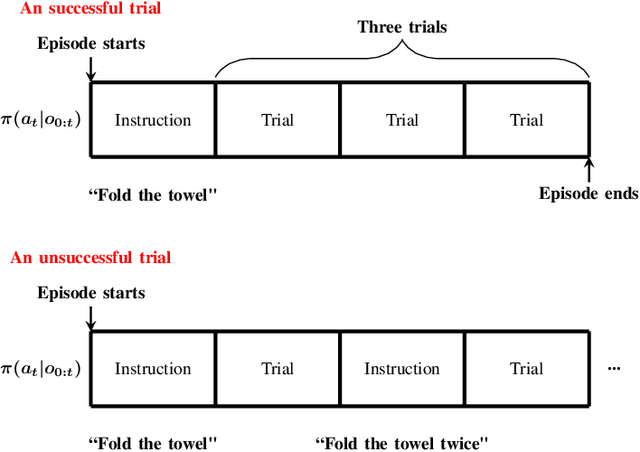
Although deep reinforcement learning has recently been very successful at learning complex behaviors, it requires a tremendous amount of data to learn a task. One of the fundamental reasons causing this limitation lies in the nature of the trial-and-error learning paradigm of reinforcement learning, where the agent communicates with the environment and progresses in the learning only relying on the reward signal. This is implicit and rather insufficient to learn a task well. On the contrary, humans are usually taught new skills via natural language instructions. Utilizing language instructions for robotic motion control to improve the adaptability is a recently emerged topic and challenging. In this paper, we present a meta-RL algorithm that addresses the challenge of learning skills with language instructions in multiple manipulation tasks. On the one hand, our algorithm utilizes the language instructions to shape its interpretation of the task, on the other hand, it still learns to solve task in a trial-and-error process. We evaluate our algorithm on the robotic manipulation benchmark (Meta-World) and it significantly outperforms state-of-the-art methods in terms of training and testing task success rates. Codes are available at \url{https://tumi6robot.wixsite.com/million}.