 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreaming the Unseen: World Model-regularized Diffusion Policy for Out-of-Distribution Robustness
Mar 22, 2026Diffusion policies excel at visuomotor control but often fail catastrophically under severe out-of-distribution (OOD) disturbances, such as unexpected object displacements or visual corruptions. To address this vulnerability, we introduce the Dream Diffusion Policy (DDP), a framework that deeply integrates a diffusion world model into the policy's training objective via a shared 3D visual encoder. This co-optimization endows the policy with robust state-prediction capabilities. When encountering sudden OOD anomalies during inference, DDP detects the real-imagination discrepancy and actively abandons the corrupted visual stream. Instead, it relies on its internal "imagination" (autoregressively forecasted latent dynamics) to safely bypass the disruption, generating imagined trajectories before smoothly realigning with physical reality. Extensive evaluations demonstrate DDP's exceptional resilience. Notably, DDP achieves a 73.8% OOD success rate on MetaWorld (vs. 23.9% without predictive imagination) and an 83.3% success rate under severe real-world spatial shifts (vs. 3.3% without predictive imagination). Furthermore, as a stress test, DDP maintains a 76.7% real-world success rate even when relying entirely on open-loop imagination post-initialization.
USIS-PGM: Photometric Gaussian Mixtures for Underwater Salient Instance Segmentation
Mar 17, 2026Underwater salient instance segmentation (USIS) is crucial for marine robotic systems, as it enables both underwater salient object detection and instance-level mask prediction for visual scene understanding. Compared with its terrestrial counterpart, USIS is more challenging due to the underwater image degradation. To address this issue, this paper proposes USIS-PGM, a single-stage framework for USIS. Specifically, the encoder enhances boundary cues through a frequency-aware module and performs content-adaptive feature reweighting via a dynamic weighting module. The decoder incorporates a Transformer-based instance activation module to better distinguish salient instances. In addition, USIS-PGM employs multi-scale Gaussian heatmaps generated from ground-truth masks through Photometric Gaussian Mixture (PGM) to supervise intermediate decoder features, thereby improving salient instance localization and producing more structurally coherent mask predictions. Experimental results demonstrate the superiority and practical applicability of the proposed USIS-PGM model.
AffordanceGrasp-R1:Leveraging Reasoning-Based Affordance Segmentation with Reinforcement Learning for Robotic Grasping
Feb 03, 2026We introduce AffordanceGrasp-R1, a reasoning-driven affordance segmentation framework for robotic grasping that combines a chain-of-thought (CoT) cold-start strategy with reinforcement learning to enhance deduction and spatial grounding. In addition, we redesign the grasping pipeline to be more context-aware by generating grasp candidates from the global scene point cloud and subsequently filtering them using instruction-conditioned affordance masks. Extensive experiments demonstrate that AffordanceGrasp-R1 consistently outperforms state-of-the-art (SOTA) methods on benchmark datasets, and real-world robotic grasping evaluations further validate its robustness and generalization under complex language-conditioned manipulation scenarios.
Language-Guided Grasp Detection with Coarse-to-Fine Learning for Robotic Manipulation
Dec 24, 2025Grasping is one of the most fundamental challenging capabilities in robotic manipulation, especially in unstructured, cluttered, and semantically diverse environments. Recent researches have increasingly explored language-guided manipulation, where robots not only perceive the scene but also interpret task-relevant natural language instructions. However, existing language-conditioned grasping methods typically rely on shallow fusion strategies, leading to limited semantic grounding and weak alignment between linguistic intent and visual grasp reasoning.In this work, we propose Language-Guided Grasp Detection (LGGD) with a coarse-to-fine learning paradigm for robotic manipulation. LGGD leverages CLIP-based visual and textual embeddings within a hierarchical cross-modal fusion pipeline, progressively injecting linguistic cues into the visual feature reconstruction process. This design enables fine-grained visual-semantic alignment and improves the feasibility of the predicted grasps with respect to task instructions. In addition, we introduce a language-conditioned dynamic convolution head (LDCH) that mixes multiple convolution experts based on sentence-level features, enabling instruction-adaptive coarse mask and grasp predictions. A final refinement module further enhances grasp consistency and robustness in complex scenes.Experiments on the OCID-VLG and Grasp-Anything++ datasets show that LGGD surpasses existing language-guided grasping methods, exhibiting strong generalization to unseen objects and diverse language queries. Moreover, deployment on a real robotic platform demonstrates the practical effectiveness of our approach in executing accurate, instruction-conditioned grasp actions. The code will be released publicly upon acceptance.
UOPSL: Unpaired OCT Predilection Sites Learning for Fundus Image Diagnosis Augmentation
Sep 10, 2025Significant advancements in AI-driven multimodal medical image diagnosis have led to substantial improvements in ophthalmic disease identification in recent years. However, acquiring paired multimodal ophthalmic images remains prohibitively expensive. While fundus photography is simple and cost-effective, the limited availability of OCT data and inherent modality imbalance hinder further progress. Conventional approaches that rely solely on fundus or textual features often fail to capture fine-grained spatial information, as each imaging modality provides distinct cues about lesion predilection sites. In this study, we propose a novel unpaired multimodal framework \UOPSL that utilizes extensive OCT-derived spatial priors to dynamically identify predilection sites, enhancing fundus image-based disease recognition. Our approach bridges unpaired fundus and OCTs via extended disease text descriptions. Initially, we employ contrastive learning on a large corpus of unpaired OCT and fundus images while simultaneously learning the predilection sites matrix in the OCT latent space. Through extensive optimization, this matrix captures lesion localization patterns within the OCT feature space. During the fine-tuning or inference phase of the downstream classification task based solely on fundus images, where paired OCT data is unavailable, we eliminate OCT input and utilize the predilection sites matrix to assist in fundus image classification learning. Extensive experiments conducted on 9 diverse datasets across 28 critical categories demonstrate that our framework outperforms existing benchmarks.
CLAPS: A CLIP-Unified Auto-Prompt Segmentation for Multi-Modal Retinal Imaging
Sep 10, 2025Recent advancements in foundation models, such as the Segment Anything Model (SAM), have significantly impacted medical image segmentation, especially in retinal imaging, where precise segmentation is vital for diagnosis. Despite this progress, current methods face critical challenges: 1) modality ambiguity in textual disease descriptions, 2) a continued reliance on manual prompting for SAM-based workflows, and 3) a lack of a unified framework, with most methods being modality- and task-specific. To overcome these hurdles, we propose CLIP-unified Auto-Prompt Segmentation (\CLAPS), a novel method for unified segmentation across diverse tasks and modalities in retinal imaging. Our approach begins by pre-training a CLIP-based image encoder on a large, multi-modal retinal dataset to handle data scarcity and distribution imbalance. We then leverage GroundingDINO to automatically generate spatial bounding box prompts by detecting local lesions. To unify tasks and resolve ambiguity, we use text prompts enhanced with a unique "modality signature" for each imaging modality. Ultimately, these automated textual and spatial prompts guide SAM to execute precise segmentation, creating a fully automated and unified pipeline. Extensive experiments on 12 diverse datasets across 11 critical segmentation categories show that CLAPS achieves performance on par with specialized expert models while surpassing existing benchmarks across most metrics, demonstrating its broad generalizability as a foundation model.
Pretrained Bayesian Non-parametric Knowledge Prior in Robotic Long-Horizon Reinforcement Learning
Mar 27, 2025



Reinforcement learning (RL) methods typically learn new tasks from scratch, often disregarding prior knowledge that could accelerate the learning process. While some methods incorporate previously learned skills, they usually rely on a fixed structure, such as a single Gaussian distribution, to define skill priors. This rigid assumption can restrict the diversity and flexibility of skills, particularly in complex, long-horizon tasks. In this work, we introduce a method that models potential primitive skill motions as having non-parametric properties with an unknown number of underlying features. We utilize a Bayesian non-parametric model, specifically Dirichlet Process Mixtures, enhanced with birth and merge heuristics, to pre-train a skill prior that effectively captures the diverse nature of skills. Additionally, the learned skills are explicitly trackable within the prior space, enhancing interpretability and control. By integrating this flexible skill prior into an RL framework, our approach surpasses existing methods in long-horizon manipulation tasks, enabling more efficient skill transfer and task success in complex environments. Our findings show that a richer, non-parametric representation of skill priors significantly improves both the learning and execution of challenging robotic tasks. All data, code, and videos are available at https://ghiara.github.io/HELIOS/.
Data-Agnostic Robotic Long-Horizon Manipulation with Vision-Language-Guided Closed-Loop Feedback
Mar 27, 2025Recent advances in language-conditioned robotic manipulation have leveraged imitation and reinforcement learning to enable robots to execute tasks from human commands. However, these methods often suffer from limited generalization, adaptability, and the lack of large-scale specialized datasets, unlike data-rich domains such as computer vision, making long-horizon task execution challenging. To address these gaps, we introduce DAHLIA, a data-agnostic framework for language-conditioned long-horizon robotic manipulation, leveraging large language models (LLMs) for real-time task planning and execution. DAHLIA employs a dual-tunnel architecture, where an LLM-powered planner collaborates with co-planners to decompose tasks and generate executable plans, while a reporter LLM provides closed-loop feedback, enabling adaptive re-planning and ensuring task recovery from potential failures. Moreover, DAHLIA integrates chain-of-thought (CoT) in task reasoning and temporal abstraction for efficient action execution, enhancing traceability and robustness. Our framework demonstrates state-of-the-art performance across diverse long-horizon tasks, achieving strong generalization in both simulated and real-world scenarios. Videos and code are available at https://ghiara.github.io/DAHLIA/.
Predicting the Road Ahead: A Knowledge Graph based Foundation Model for Scene Understanding in Autonomous Driving
Mar 24, 2025The autonomous driving field has seen remarkable advancements in various topics, such as object recognition, trajectory prediction, and motion planning. However, current approaches face limitations in effectively comprehending the complex evolutions of driving scenes over time. This paper proposes FM4SU, a novel methodology for training a symbolic foundation model (FM) for scene understanding in autonomous driving. It leverages knowledge graphs (KGs) to capture sensory observation along with domain knowledge such as road topology, traffic rules, or complex interactions between traffic participants. A bird's eye view (BEV) symbolic representation is extracted from the KG for each driving scene, including the spatio-temporal information among the objects across the scenes. The BEV representation is serialized into a sequence of tokens and given to pre-trained language models (PLMs) for learning an inherent understanding of the co-occurrence among driving scene elements and generating predictions on the next scenes. We conducted a number of experiments using the nuScenes dataset and KG in various scenarios. The results demonstrate that fine-tuned models achieve significantly higher accuracy in all tasks. The fine-tuned T5 model achieved a next scene prediction accuracy of 86.7%. This paper concludes that FM4SU offers a promising foundation for developing more comprehensive models for scene understanding in autonomous driving.
Pick-and-place Manipulation Across Grippers Without Retraining: A Learning-optimization Diffusion Policy Approach
Feb 21, 2025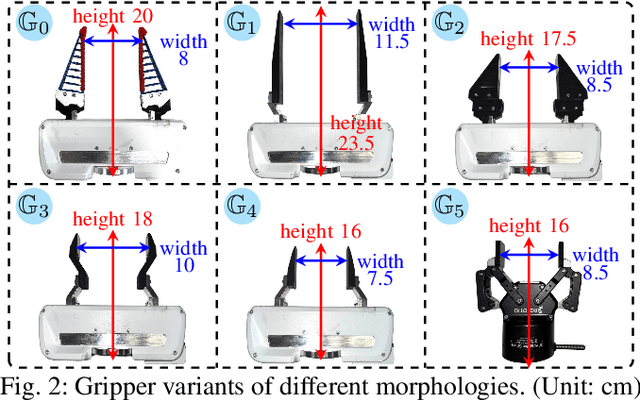
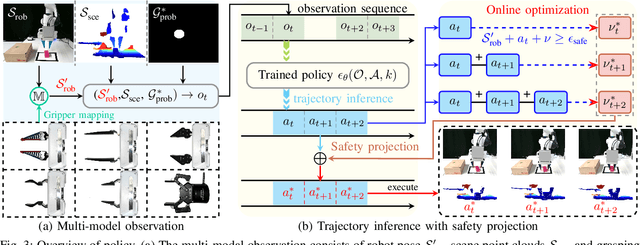

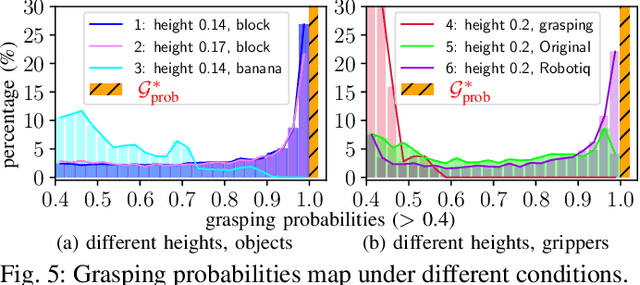
Current robotic pick-and-place policies typically require consistent gripper configurations across training and inference. This constraint imposes high retraining or fine-tuning costs, especially for imitation learning-based approaches, when adapting to new end-effectors. To mitigate this issue, we present a diffusion-based policy with a hybrid learning-optimization framework, enabling zero-shot adaptation to novel grippers without additional data collection for retraining policy. During training, the policy learns manipulation primitives from demonstrations collected using a base gripper. At inference, a diffusion-based optimization strategy dynamically enforces kinematic and safety constraints, ensuring that generated trajectories align with the physical properties of unseen grippers. This is achieved through a constrained denoising procedure that adapts trajectories to gripper-specific parameters (e.g., tool-center-point offsets, jaw widths) while preserving collision avoidance and task feasibility. We validate our method on a Franka Panda robot across six gripper configurations, including 3D-printed fingertips, flexible silicone gripper, and Robotiq 2F-85 gripper. Our approach achieves a 93.3% average task success rate across grippers (vs. 23.3-26.7% for diffusion policy baselines), supporting tool-center-point variations of 16-23.5 cm and jaw widths of 7.5-11.5 cm. The results demonstrate that constrained diffusion enables robust cross-gripper manipulation while maintaining the sample efficiency of imitation learning, eliminating the need for gripper-specific retraining. Video and code are available at https://github.com/yaoxt3/GADP.