 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems
Mar 11, 2026We present the design and implementation of a RAG-based AI system benchmarking (RAGPerf) framework for characterizing the system behaviors of RAG pipelines. To facilitate detailed profiling and fine-grained performance analysis, RAGPerf decouples the RAG workflow into several modular components - embedding, indexing, retrieval, reranking, and generation. RAGPerf offers the flexibility for users to configure the core parameters of each component and examine their impact on the end-to-end query performance and quality. RAGPerf has a workload generator to model real-world scenarios by supporting diverse datasets (e.g., text, pdf, code, and audio), different retrieval and update ratios, and query distributions. RAGPerf also supports different embedding models, major vector databases such as LanceDB, Milvus, Qdrant, Chroma, and Elasticsearch, as well as different LLMs for content generation. It automates the collection of performance metrics (i.e., end-to-end query throughput, host/GPU memory footprint, and CPU/GPU utilization) and accuracy metrics (i.e., context recall, query accuracy, and factual consistency). We demonstrate the capabilities of RAGPerf through a comprehensive set of experiments and open source its codebase at GitHub. Our evaluation shows that RAGPerf incurs negligible performance overhead.
Data-Agnostic Robotic Long-Horizon Manipulation with Vision-Language-Guided Closed-Loop Feedback
Mar 27, 2025Recent advances in language-conditioned robotic manipulation have leveraged imitation and reinforcement learning to enable robots to execute tasks from human commands. However, these methods often suffer from limited generalization, adaptability, and the lack of large-scale specialized datasets, unlike data-rich domains such as computer vision, making long-horizon task execution challenging. To address these gaps, we introduce DAHLIA, a data-agnostic framework for language-conditioned long-horizon robotic manipulation, leveraging large language models (LLMs) for real-time task planning and execution. DAHLIA employs a dual-tunnel architecture, where an LLM-powered planner collaborates with co-planners to decompose tasks and generate executable plans, while a reporter LLM provides closed-loop feedback, enabling adaptive re-planning and ensuring task recovery from potential failures. Moreover, DAHLIA integrates chain-of-thought (CoT) in task reasoning and temporal abstraction for efficient action execution, enhancing traceability and robustness. Our framework demonstrates state-of-the-art performance across diverse long-horizon tasks, achieving strong generalization in both simulated and real-world scenarios. Videos and code are available at https://ghiara.github.io/DAHLIA/.
Pick-and-place Manipulation Across Grippers Without Retraining: A Learning-optimization Diffusion Policy Approach
Feb 21, 2025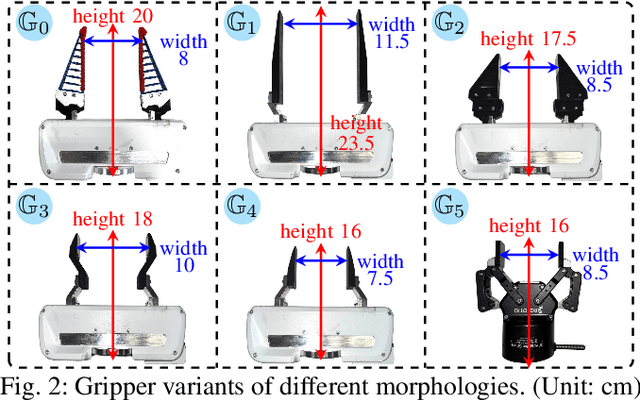
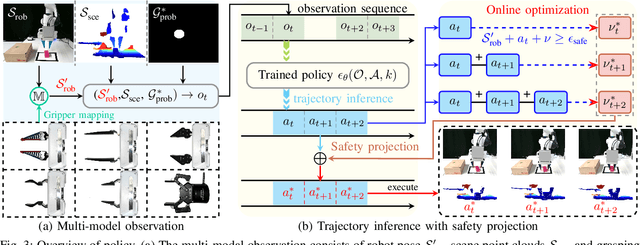

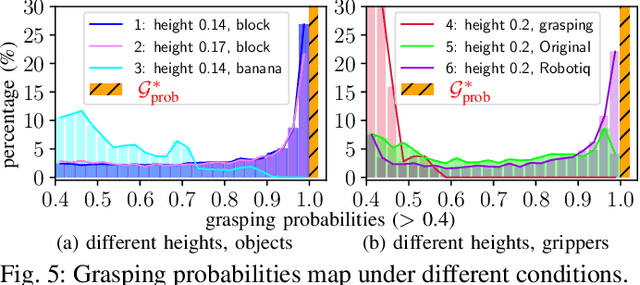
Current robotic pick-and-place policies typically require consistent gripper configurations across training and inference. This constraint imposes high retraining or fine-tuning costs, especially for imitation learning-based approaches, when adapting to new end-effectors. To mitigate this issue, we present a diffusion-based policy with a hybrid learning-optimization framework, enabling zero-shot adaptation to novel grippers without additional data collection for retraining policy. During training, the policy learns manipulation primitives from demonstrations collected using a base gripper. At inference, a diffusion-based optimization strategy dynamically enforces kinematic and safety constraints, ensuring that generated trajectories align with the physical properties of unseen grippers. This is achieved through a constrained denoising procedure that adapts trajectories to gripper-specific parameters (e.g., tool-center-point offsets, jaw widths) while preserving collision avoidance and task feasibility. We validate our method on a Franka Panda robot across six gripper configurations, including 3D-printed fingertips, flexible silicone gripper, and Robotiq 2F-85 gripper. Our approach achieves a 93.3% average task success rate across grippers (vs. 23.3-26.7% for diffusion policy baselines), supporting tool-center-point variations of 16-23.5 cm and jaw widths of 7.5-11.5 cm. The results demonstrate that constrained diffusion enables robust cross-gripper manipulation while maintaining the sample efficiency of imitation learning, eliminating the need for gripper-specific retraining. Video and code are available at https://github.com/yaoxt3/GADP.
Residual Chain Prediction for Autonomous Driving Path Planning
Apr 08, 2024


In the rapidly evolving field of autonomous driving systems, the refinement of path planning algorithms is paramount for navigating vehicles through dynamic environments, particularly in complex urban scenarios. Traditional path planning algorithms, which are heavily reliant on static rules and manually defined parameters, often fall short in such contexts, highlighting the need for more adaptive, learning-based approaches. Among these, behavior cloning emerges as a noteworthy strategy for its simplicity and efficiency, especially within the realm of end-to-end path planning. However, behavior cloning faces challenges, such as covariate shift when employing traditional Manhattan distance as the metric. Addressing this, our study introduces the novel concept of Residual Chain Loss. Residual Chain Loss dynamically adjusts the loss calculation process to enhance the temporal dependency and accuracy of predicted path points, significantly improving the model's performance without additional computational overhead. Through testing on the nuScenes dataset, we underscore the method's substantial advancements in addressing covariate shift, facilitating dynamic loss adjustments, and ensuring seamless integration with end-to-end path planning frameworks. Our findings highlight the potential of Residual Chain Loss to revolutionize planning component of autonomous driving systems, marking a significant step forward in the quest for level 5 autonomous driving system.
Rethinking Adversarial Inverse Reinforcement Learning: From the Angles of Policy Imitation and Transferable Reward Recovery
Mar 21, 2024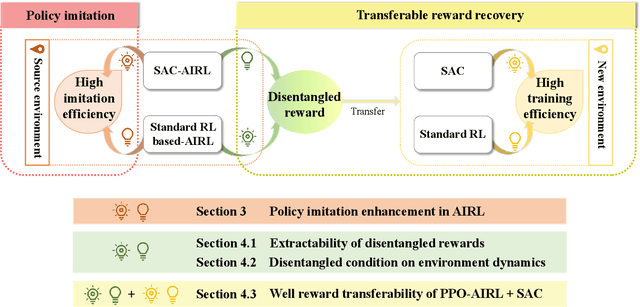
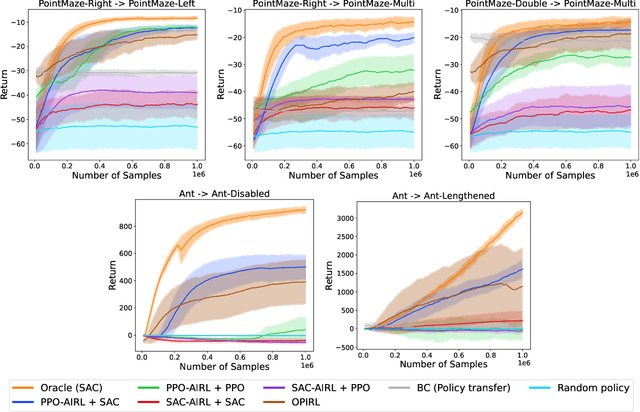

Adversarial inverse reinforcement learning (AIRL) stands as a cornerstone approach in imitation learning. This paper rethinks the two different angles of AIRL: policy imitation and transferable reward recovery. We begin with substituting the built-in algorithm in AIRL with soft actor-critic (SAC) during the policy optimization process to enhance sample efficiency, thanks to the off-policy formulation of SAC and identifiable Markov decision process (MDP) models with respect to AIRL. It indeed exhibits a significant improvement in policy imitation but accidentally brings drawbacks to transferable reward recovery. To learn this issue, we illustrate that the SAC algorithm itself is not feasible to disentangle the reward function comprehensively during the AIRL training process, and propose a hybrid framework, PPO-AIRL + SAC, for satisfactory transfer effect. Additionally, we analyze the capability of environments to extract disentangled rewards from an algebraic theory perspective.
Exploring Gradient Explosion in Generative Adversarial Imitation Learning: A Probabilistic Perspective
Dec 18, 2023



Generative Adversarial Imitation Learning (GAIL) stands as a cornerstone approach in imitation learning. This paper investigates the gradient explosion in two types of GAIL: GAIL with deterministic policy (DE-GAIL) and GAIL with stochastic policy (ST-GAIL). We begin with the observation that the training can be highly unstable for DE-GAIL at the beginning of the training phase and end up divergence. Conversely, the ST-GAIL training trajectory remains consistent, reliably converging. To shed light on these disparities, we provide an explanation from a theoretical perspective. By establishing a probabilistic lower bound for GAIL, we demonstrate that gradient explosion is an inevitable outcome for DE-GAIL due to occasionally large expert-imitator policy disparity, whereas ST-GAIL does not have the issue with it. To substantiate our assertion, we illustrate how modifications in the reward function can mitigate the gradient explosion challenge. Finally, we propose CREDO, a simple yet effective strategy that clips the reward function during the training phase, allowing the GAIL to enjoy high data efficiency and stable trainability.