 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2E Parking Dataset: An Open Benchmark for End-to-End Autonomous Parking
Apr 15, 2025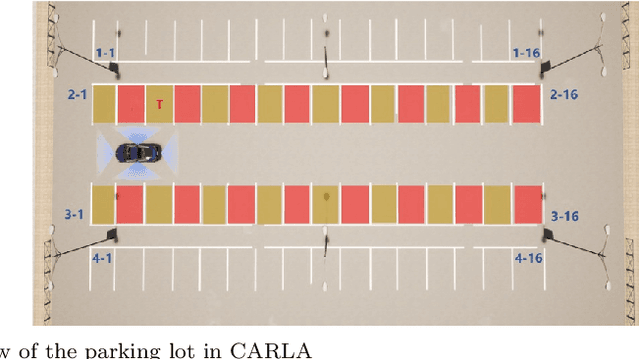
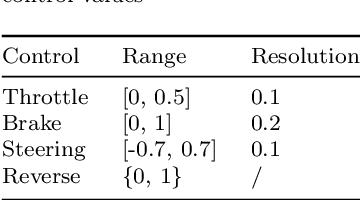
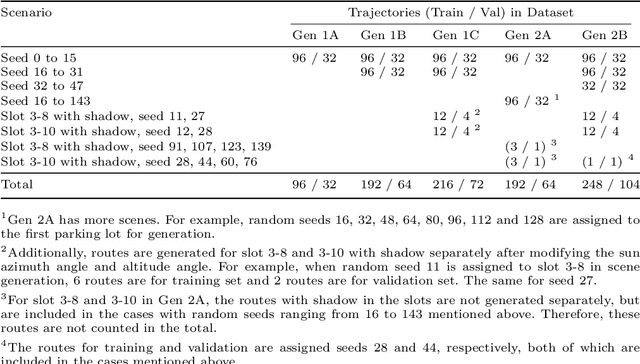
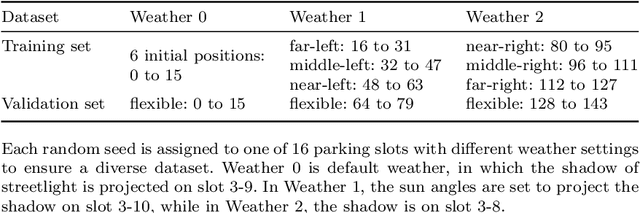
End-to-end learning has shown great potential in autonomous parking, yet the lack of publicly available datasets limits reproducibility and benchmarking. While prior work introduced a visual-based parking model and a pipeline for data generation, training, and close-loop test, the dataset itself was not released. To bridge this gap, we create and open-source a high-quality dataset for end-to-end autonomous parking. Using the original model, we achieve an overall success rate of 85.16% with lower average position and orientation errors (0.24 meters and 0.34 degrees).
Residual Chain Prediction for Autonomous Driving Path Planning
Apr 08, 2024


In the rapidly evolving field of autonomous driving systems, the refinement of path planning algorithms is paramount for navigating vehicles through dynamic environments, particularly in complex urban scenarios. Traditional path planning algorithms, which are heavily reliant on static rules and manually defined parameters, often fall short in such contexts, highlighting the need for more adaptive, learning-based approaches. Among these, behavior cloning emerges as a noteworthy strategy for its simplicity and efficiency, especially within the realm of end-to-end path planning. However, behavior cloning faces challenges, such as covariate shift when employing traditional Manhattan distance as the metric. Addressing this, our study introduces the novel concept of Residual Chain Loss. Residual Chain Loss dynamically adjusts the loss calculation process to enhance the temporal dependency and accuracy of predicted path points, significantly improving the model's performance without additional computational overhead. Through testing on the nuScenes dataset, we underscore the method's substantial advancements in addressing covariate shift, facilitating dynamic loss adjustments, and ensuring seamless integration with end-to-end path planning frameworks. Our findings highlight the potential of Residual Chain Loss to revolutionize planning component of autonomous driving systems, marking a significant step forward in the quest for level 5 autonomous driving system.
Path Planning based on 2D Object Bounding-box
Feb 22, 2024
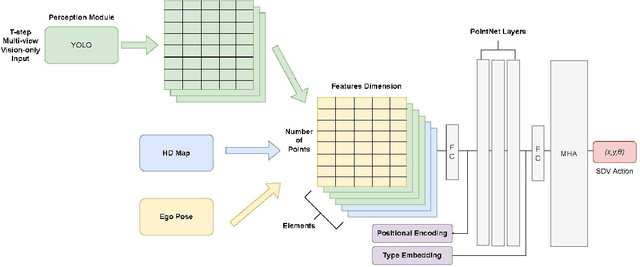
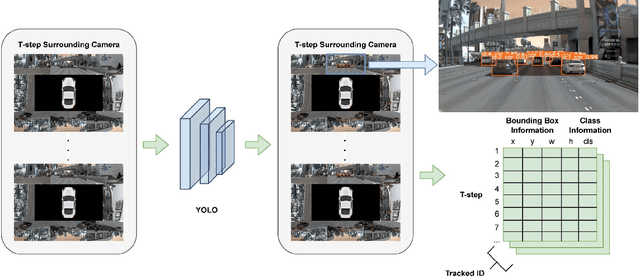
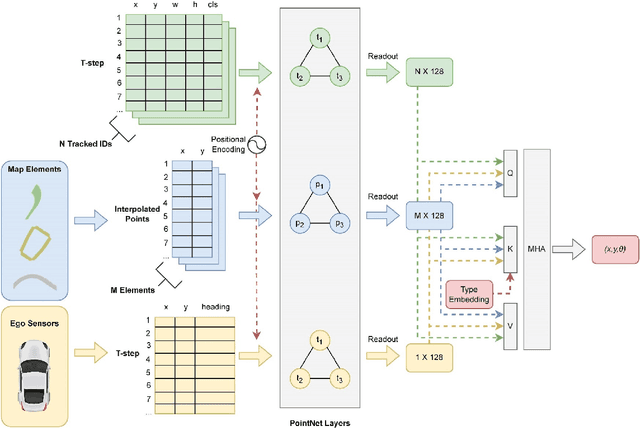
The implementation of Autonomous Driving (AD) technologies within urban environments presents significant challenges. These challenges necessitate the development of advanced perception systems and motion planning algorithms capable of managing situations of considerable complexity. Although the end-to-end AD method utilizing LiDAR sensors has achieved significant success in this scenario, we argue that its drawbacks may hinder its practical application. Instead, we propose the vision-centric AD as a promising alternative offering a streamlined model without compromising performance. In this study, we present a path planning method that utilizes 2D bounding boxes of objects, developed through imitation learning in urban driving scenarios. This is achieved by integrating high-definition (HD) map data with images captured by surrounding cameras. Subsequent perception tasks involve bounding-box detection and tracking, while the planning phase employs both local embeddings via Graph Neural Network (GNN) and global embeddings via Transformer for temporal-spatial feature aggregation, ultimately producing optimal path planning information. We evaluated our model on the nuPlan planning task and observed that it performs competitively in comparison to existing vision-centric methods.
GarchingSim: An Autonomous Driving Simulator with Photorealistic Scenes and Minimalist Workflow
Jan 30, 2024



Conducting real road testing for autonomous driving algorithms can be expensive and sometimes impractical, particularly for small startups and research institutes. Thus, simulation becomes an important method for evaluating these algorithms. However, the availability of free and open-source simulators is limited, and the installation and configuration process can be daunting for beginners and interdisciplinary researchers. We introduce an autonomous driving simulator with photorealistic scenes, meanwhile keeping a user-friendly workflow. The simulator is able to communicate with external algorithms through ROS2 or Socket.IO, making it compatible with existing software stacks. Furthermore, we implement a highly accurate vehicle dynamics model within the simulator to enhance the realism of the vehicle's physical effects. The simulator is able to serve various functions, including generating synthetic data and driving with machine learning-based algorithms. Moreover, we prioritize simplicity in the deployment process, ensuring that beginners find it approachable and user-friendly.
YOLO-BEV: Generating Bird's-Eye View in the Same Way as 2D Object Detection
Oct 26, 2023



Vehicle perception systems strive to achieve comprehensive and rapid visual interpretation of their surroundings for improved safety and navigation. We introduce YOLO-BEV, an efficient framework that harnesses a unique surrounding cameras setup to generate a 2D bird's-eye view of the vehicular environment. By strategically positioning eight cameras, each at a 45-degree interval, our system captures and integrates imagery into a coherent 3x3 grid format, leaving the center blank, providing an enriched spatial representation that facilitates efficient processing. In our approach, we employ YOLO's detection mechanism, favoring its inherent advantages of swift response and compact model structure. Instead of leveraging the conventional YOLO detection head, we augment it with a custom-designed detection head, translating the panoramically captured data into a unified bird's-eye view map of ego car. Preliminary results validate the feasibility of YOLO-BEV in real-time vehicular perception tasks. With its streamlined architecture and potential for rapid deployment due to minimized parameters, YOLO-BEV poses as a promising tool that may reshape future perspectives in autonomous driving systems.
Fast and Accurate Object Detection on Asymmetrical Receptive Field
Mar 15, 2023



Object detection has been used in a wide range of industries. For example, in autonomous driving, the task of object detection is to accurately and efficiently identify and locate a large number of predefined classes of object instances (vehicles, pedestrians, traffic signs, etc.) from videos of roads. In robotics, the industry robot needs to recognize specific machine elements. In the security field, the camera should accurately recognize each face of people. With the wide application of deep learning, the accuracy and efficiency of object detection have been greatly improved, but object detection based on deep learning still faces challenges. Different applications of object detection have different requirements, including highly accurate detection, multi-category object detection, real-time detection, robustness to occlusions, etc. To address the above challenges, based on extensive literature research, this paper analyzes methods for improving and optimizing mainstream object detection algorithms from the perspective of evolution of one-stage and two-stage object detection algorithms. Furthermore, this article proposes methods for improving object detection accuracy from the perspective of changing receptive fields. The new model is based on the original YOLOv5 (You Look Only Once) with some modifications. The structure of the head part of YOLOv5 is modified by adding asymmetrical pooling layers. As a result, the accuracy of the algorithm is improved while ensuring the speed. The performances of the new model in this article are compared with original YOLOv5 model and analyzed from several parameters. And the evaluation of the new model is presented in four situations. Moreover, the summary and outlooks are made on the problems to be solved and the research directions in the future.
Sequential Spatial Network for Collision Avoidance in Autonomous Driving
Mar 12, 2023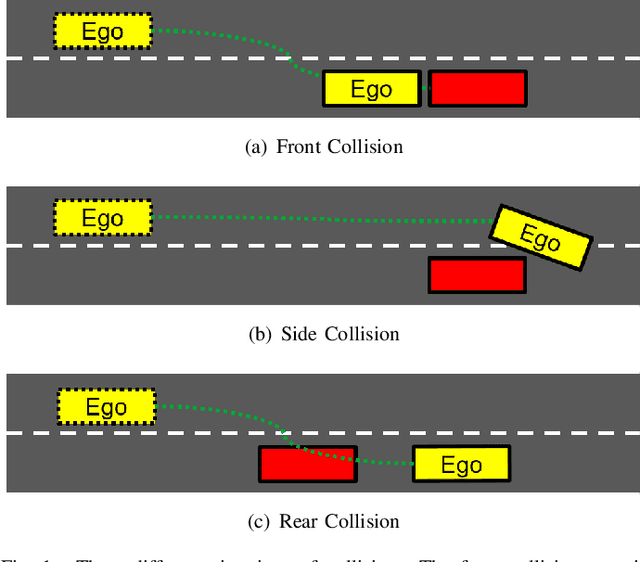
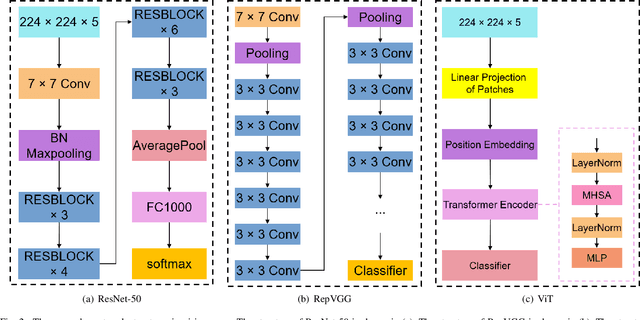
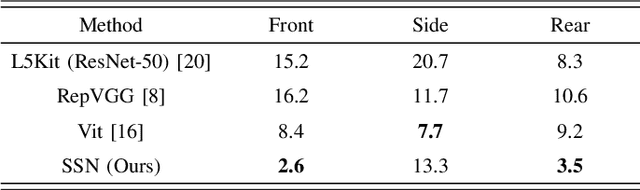
Several autonomous driving strategies have been applied to autonomous vehicles, especially in the collision avoidance area. The purpose of collision avoidance is achieved by adjusting the trajectory of autonomous vehicles (AV) to avoid intersection or overlap with the trajectory of surrounding vehicles. A large number of sophisticated vision algorithms have been designed for target inspection, classification, and other tasks, such as ResNet, YOLO, etc., which have achieved excellent performance in vision tasks because of their ability to accurately and quickly capture regional features. However, due to the variability of different tasks, the above models achieve good performance in capturing small regions but are still insufficient in correlating the regional features of the input image with each other. In this paper, we aim to solve this problem and develop an algorithm that takes into account the advantages of CNN in capturing regional features while establishing feature correlation between regions using variants of attention. Finally, our model achieves better performance in the test set of L5Kit compared to the other vision models. The average number of collisions is 19.4 per 10000 frames of driving distance, which greatly improves the success rate of collision avoidance.
BCSSN: Bi-direction Compact Spatial Separable Network for Collision Avoidance in Autonomous Driving
Mar 12, 2023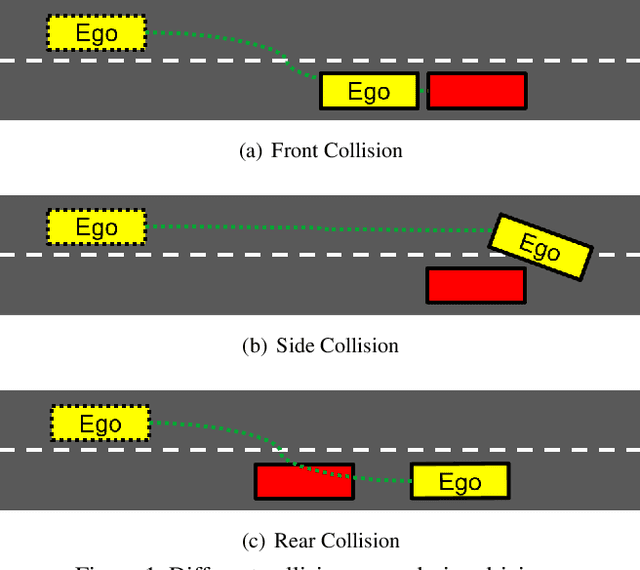
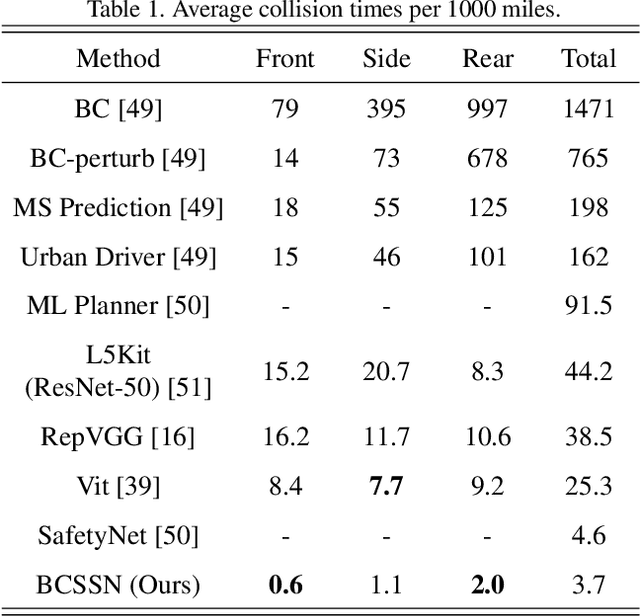
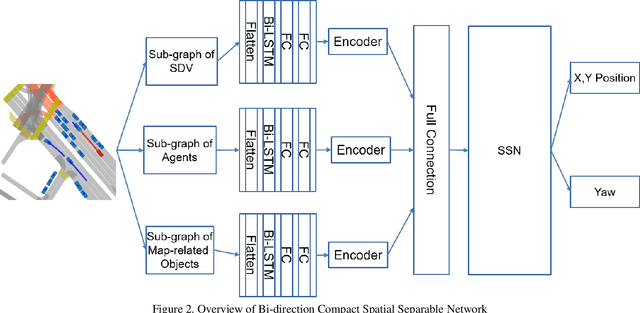
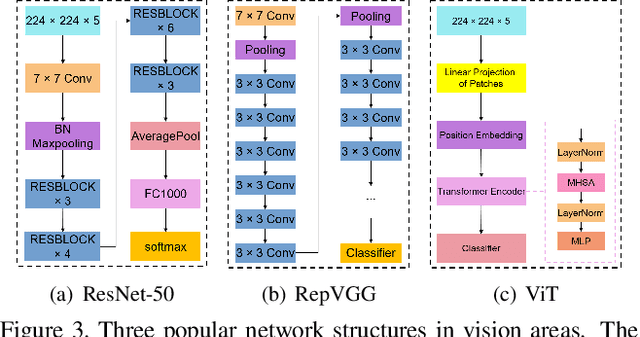
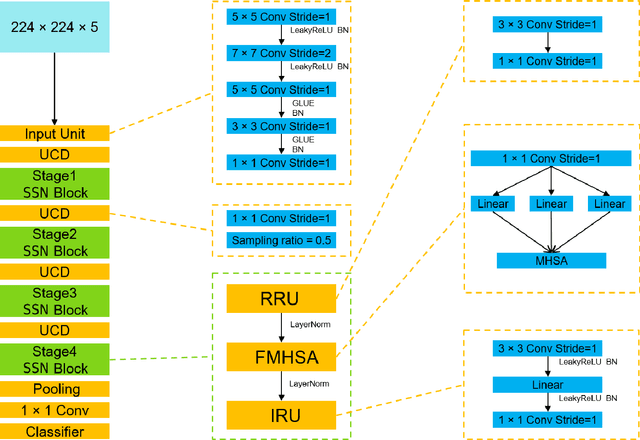
Autonomous driving has been an active area of research and development, with various strategies being explored for decision-making in autonomous vehicles. Rule-based systems, decision trees, Markov decision processes, and Bayesian networks have been some of the popular methods used to tackle the complexities of traffic conditions and avoid collisions. However, with the emergence of deep learning, many researchers have turned towards CNN-based methods to improve the performance of collision avoidance. Despite the promising results achieved by some CNN-based methods, the failure to establish correlations between sequential images often leads to more collisions. In this paper, we propose a CNN-based method that overcomes the limitation by establishing feature correlations between regions in sequential images using variants of attention. Our method combines the advantages of CNN in capturing regional features with a bi-directional LSTM to enhance the relationship between different local areas. Additionally, we use an encoder to improve computational efficiency. Our method takes "Bird's Eye View" graphs generated from camera and LiDAR sensors as input, simulates the position (x, y) and head offset angle (Yaw) to generate future trajectories. Experiment results demonstrate that our proposed method outperforms existing vision-based strategies, achieving an average of only 3.7 collisions per 1000 miles of driving distance on the L5kit test set. This significantly improves the success rate of collision avoidance and provides a promising solution for autonomous driving.
Attention Mechanism for Contrastive Learning in GAN-based Image-to-Image Translation
Feb 23, 2023

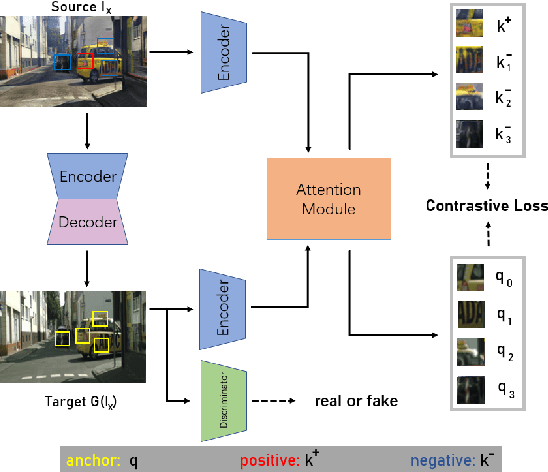
Using real road testing to optimize autonomous driving algorithms is time-consuming and capital-intensive. To solve this problem, we propose a GAN-based model that is capable of generating high-quality images across different domains. We further leverage Contrastive Learning to train the model in a self-supervised way using image data acquired in the real world using real sensors and simulated images from 3D games. In this paper, we also apply an Attention Mechanism module to emphasize features that contain more information about the source domain according to their measurement of significance. Finally, the generated images are used as datasets to train neural networks to perform a variety of downstream tasks to verify that the approach can fill in the gaps between the virtual and real worlds.
Autonomous Driving Simulator based on Neurorobotics Platform
Dec 31, 2022



There are many artificial intelligence algorithms for autonomous driving, but directly installing these algorithms on vehicles is unrealistic and expensive. At the same time, many of these algorithms need an environment to train and optimize. Simulation is a valuable and meaningful solution with training and testing functions, and it can say that simulation is a critical link in the autonomous driving world. There are also many different applications or systems of simulation from companies or academies such as SVL and Carla. These simulators flaunt that they have the closest real-world simulation, but their environment objects, such as pedestrians and other vehicles around the agent-vehicle, are already fixed programmed. They can only move along the pre-setting trajectory, or random numbers determine their movements. What is the situation when all environmental objects are also installed by Artificial Intelligence, or their behaviors are like real people or natural reactions of other drivers? This problem is a blind spot for most of the simulation applications, or these applications cannot be easy to solve this problem. The Neurorobotics Platform from the TUM team of Prof. Alois Knoll has the idea about "Engines" and "Transceiver Functions" to solve the multi-agents problem. This report will start with a little research on the Neurorobotics Platform and analyze the potential and possibility of developing a new simulator to achieve the true real-world simulation goal. Then based on the NRP-Core Platform, this initial development aims to construct an initial demo experiment. The consist of this report starts with the basic knowledge of NRP-Core and its installation, then focus on the explanation of the necessary components for a simulation experiment, at last, about the details of constructions for the autonomous driving system, which is integrated object detection and autonomous control.