 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoDriveVLA: Evolving Autonomous Driving Vision-Language-Action Model via Collaborative Perception-Planning Distillation
Mar 10, 2026Vision-Language-Action models have shown great promise for autonomous driving, yet they suffer from degraded perception after unfreezing the visual encoder and struggle with accumulated instability in long-term planning. To address these challenges, we propose EvoDriveVLA-a novel collaborative perception-planning distillation framework that integrates self-anchored perceptual constraints and oracle-guided trajectory optimization. Specifically, self-anchored visual distillation leverages self-anchor teacher to deliver visual anchoring constraints, regularizing student representations via trajectory-guided key-region awareness. In parallel, oracle-guided trajectory distillation employs a future-aware oracle teacher with coarse-to-fine trajectory refinement and Monte Carlo dropout sampling to produce high-quality trajectory candidates, thereby selecting the optimal trajectory to guide the student's prediction. EvoDriveVLA achieves SOTA performance in open-loop evaluation and significantly enhances performance in closed-loop evaluation. Our code is available at: https://github.com/hey-cjj/EvoDriveVLA.
Attention Mechanism for Contrastive Learning in GAN-based Image-to-Image Translation
Feb 23, 2023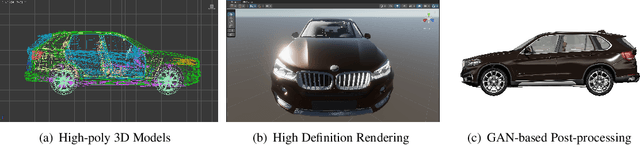

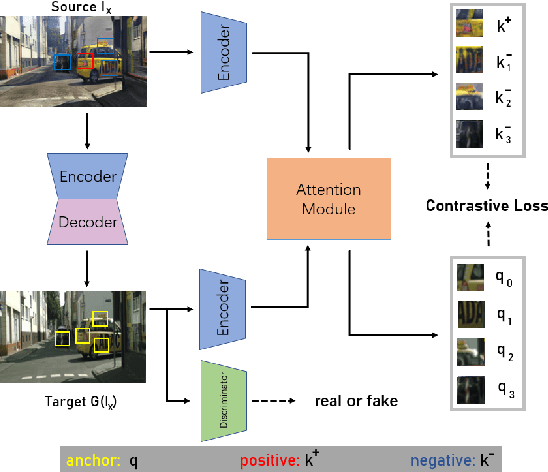
Using real road testing to optimize autonomous driving algorithms is time-consuming and capital-intensive. To solve this problem, we propose a GAN-based model that is capable of generating high-quality images across different domains. We further leverage Contrastive Learning to train the model in a self-supervised way using image data acquired in the real world using real sensors and simulated images from 3D games. In this paper, we also apply an Attention Mechanism module to emphasize features that contain more information about the source domain according to their measurement of significance. Finally, the generated images are used as datasets to train neural networks to perform a variety of downstream tasks to verify that the approach can fill in the gaps between the virtual and real worlds.
3D Object Detection with a Self-supervised Lidar Scene Flow Backbone
May 02, 2022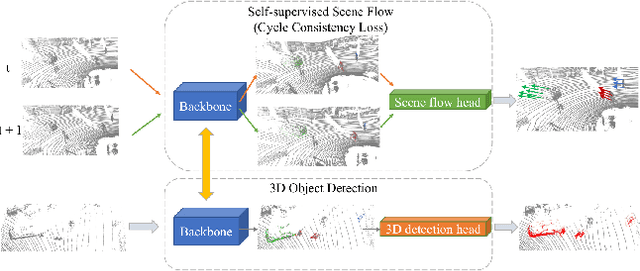

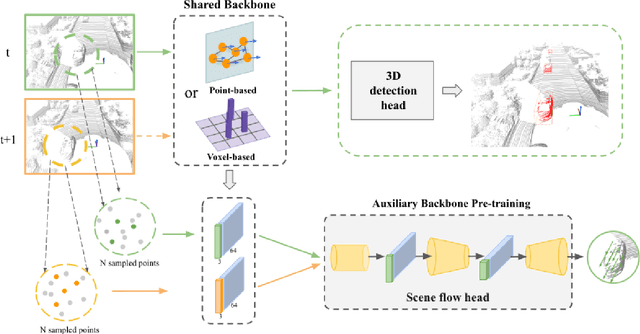
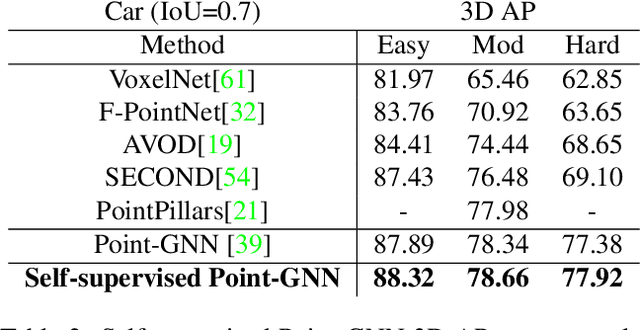
State-of-the-art 3D detection methods rely on supervised learning and large labelled datasets. However, annotating lidar data is resource-consuming, and depending only on supervised learning limits the applicability of trained models. Against this backdrop, here we propose using a self-supervised training strategy to learn a general point cloud backbone model for downstream 3D vision tasks. 3D scene flow can be estimated with self-supervised learning using cycle consistency, which removes labelled data requirements. Moreover, the perception of objects in the traffic scenarios heavily relies on making sense of the sparse data in the spatio-temporal context. Our main contribution leverages learned flow and motion representations and combines a self-supervised backbone with a 3D detection head focusing mainly on the relation between the scene flow and detection tasks. In this way, self-supervised scene flow training constructs point motion features in the backbone, which help distinguish objects based on their different motion patterns used with a 3D detection head. Experiments on KITTI and nuScenes benchmarks show that the proposed self-supervised pre-training increases 3D detection performance significantly.