 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Uncertainty-Weighted Decision Transformer for Navigation in Dense, Complex Driving Scenarios
Sep 16, 2025Autonomous driving in dense, dynamic environments requires decision-making systems that can exploit both spatial structure and long-horizon temporal dependencies while remaining robust to uncertainty. This work presents a novel framework that integrates multi-channel bird's-eye-view occupancy grids with transformer-based sequence modeling for tactical driving in complex roundabout scenarios. To address the imbalance between frequent low-risk states and rare safety-critical decisions, we propose the Uncertainty-Weighted Decision Transformer (UWDT). UWDT employs a frozen teacher transformer to estimate per-token predictive entropy, which is then used as a weight in the student model's loss function. This mechanism amplifies learning from uncertain, high-impact states while maintaining stability across common low-risk transitions. Experiments in a roundabout simulator, across varying traffic densities, show that UWDT consistently outperforms other baselines in terms of reward, collision rate, and behavioral stability. The results demonstrate that uncertainty-aware, spatial-temporal transformers can deliver safer and more efficient decision-making for autonomous driving in complex traffic environments.
Bootstrapping Reinforcement Learning with Sub-optimal Policies for Autonomous Driving
Sep 04, 2025Automated vehicle control using reinforcement learning (RL) has attracted significant attention due to its potential to learn driving policies through environment interaction. However, RL agents often face training challenges in sample efficiency and effective exploration, making it difficult to discover an optimal driving strategy. To address these issues, we propose guiding the RL driving agent with a demonstration policy that need not be a highly optimized or expert-level controller. Specifically, we integrate a rule-based lane change controller with the Soft Actor Critic (SAC) algorithm to enhance exploration and learning efficiency. Our approach demonstrates improved driving performance and can be extended to other driving scenarios that can similarly benefit from demonstration-based guidance.
Extensive Exploration in Complex Traffic Scenarios using Hierarchical Reinforcement Learning
Jan 25, 2025Developing an automated driving system capable of navigating complex traffic environments remains a formidable challenge. Unlike rule-based or supervised learning-based methods, Deep Reinforcement Learning (DRL) based controllers eliminate the need for domain-specific knowledge and datasets, thus providing adaptability to various scenarios. Nonetheless, a common limitation of existing studies on DRL-based controllers is their focus on driving scenarios with simple traffic patterns, which hinders their capability to effectively handle complex driving environments with delayed, long-term rewards, thus compromising the generalizability of their findings. In response to these limitations, our research introduces a pioneering hierarchical framework that efficiently decomposes intricate decision-making problems into manageable and interpretable subtasks. We adopt a two step training process that trains the high-level controller and low-level controller separately. The high-level controller exhibits an enhanced exploration potential with long-term delayed rewards, and the low-level controller provides longitudinal and lateral control ability using short-term instantaneous rewards. Through simulation experiments, we demonstrate the superiority of our hierarchical controller in managing complex highway driving situations.
GraphRelate3D: Context-Dependent 3D Object Detection with Inter-Object Relationship Graphs
May 10, 2024



Accurate and effective 3D object detection is critical for ensuring the driving safety of autonomous vehicles. Recently, state-of-the-art two-stage 3D object detectors have exhibited promising performance. However, these methods refine proposals individually, ignoring the rich contextual information in the object relationships between the neighbor proposals. In this study, we introduce an object relation module, consisting of a graph generator and a graph neural network (GNN), to learn the spatial information from certain patterns to improve 3D object detection. Specifically, we create an inter-object relationship graph based on proposals in a frame via the graph generator to connect each proposal with its neighbor proposals. Afterward, the GNN module extracts edge features from the generated graph and iteratively refines proposal features with the captured edge features. Ultimately, we leverage the refined features as input to the detection head to obtain detection results. Our approach improves upon the baseline PV-RCNN on the KITTI validation set for the car class across easy, moderate, and hard difficulty levels by 0.82%, 0.74%, and 0.58%, respectively. Additionally, our method outperforms the baseline by more than 1% under the moderate and hard levels BEV AP on the test server.
A Survey on Autonomous Driving Datasets: Data Statistic, Annotation, and Outlook
Jan 02, 2024



Autonomous driving has rapidly developed and shown promising performance with recent advances in hardware and deep learning methods. High-quality datasets are fundamental for developing reliable autonomous driving algorithms. Previous dataset surveys tried to review the datasets but either focused on a limited number or lacked detailed investigation of the characters of datasets. To this end, we present an exhaustive study of over 200 autonomous driving datasets from multiple perspectives, including sensor modalities, data size, tasks, and contextual conditions. We introduce a novel metric to evaluate the impact of each dataset, which can also be a guide for establishing new datasets. We further analyze the annotation process and quality of datasets. Additionally, we conduct an in-depth analysis of the data distribution of several vital datasets. Finally, we discuss the development trend of the future autonomous driving datasets.
Vision Language Models in Autonomous Driving and Intelligent Transportation Systems
Oct 22, 2023



The applications of Vision-Language Models (VLMs) in the fields of Autonomous Driving (AD) and Intelligent Transportation Systems (ITS) have attracted widespread attention due to their outstanding performance and the ability to leverage Large Language Models (LLMs). By integrating language data, the vehicles, and transportation systems are able to deeply understand real-world environments, improving driving safety and efficiency. In this work, we present a comprehensive survey of the advances in language models in this domain, encompassing current models and datasets. Additionally, we explore the potential applications and emerging research directions. Finally, we thoroughly discuss the challenges and research gap. The paper aims to provide researchers with the current work and future trends of VLMs in AD and ITS.
3D Understanding of Deformable Linear Objects: Datasets and Transferability Benchmark
Oct 13, 2023



Deformable linear objects are vastly represented in our everyday lives. It is often challenging even for humans to visually understand them, as the same object can be entangled so that it appears completely different. Examples of deformable linear objects include blood vessels and wiring harnesses, vital to the functioning of their corresponding systems, such as the human body and a vehicle. However, no point cloud datasets exist for studying 3D deformable linear objects. Therefore, we are introducing two point cloud datasets, PointWire and PointVessel. We evaluated state-of-the-art methods on the proposed large-scale 3D deformable linear object benchmarks. Finally, we analyzed the generalization capabilities of these methods by conducting transferability experiments on the PointWire and PointVessel datasets.
Using Collision Momentum in Deep Reinforcement Learning Based Adversarial Pedestrian Modeling
Jun 13, 2023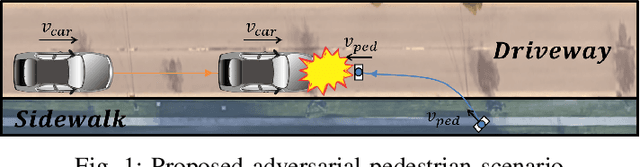

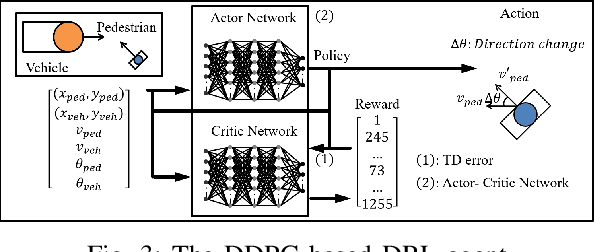
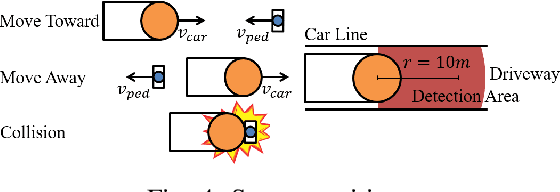
Recent research in pedestrian simulation often aims to develop realistic behaviors in various situations, but it is challenging for existing algorithms to generate behaviors that identify weaknesses in automated vehicles' performance in extreme and unlikely scenarios and edge cases. To address this, specialized pedestrian behavior algorithms are needed. Current research focuses on realistic trajectories using social force models and reinforcement learning based models. However, we propose a reinforcement learning algorithm that specifically targets collisions and better uncovers unique failure modes of automated vehicle controllers. Our algorithm is efficient and generates more severe collisions, allowing for the identification and correction of weaknesses in autonomous driving algorithms in complex and varied scenarios.
3D Object Detection with a Self-supervised Lidar Scene Flow Backbone
May 02, 2022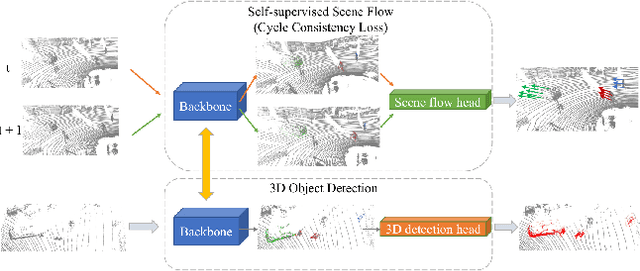

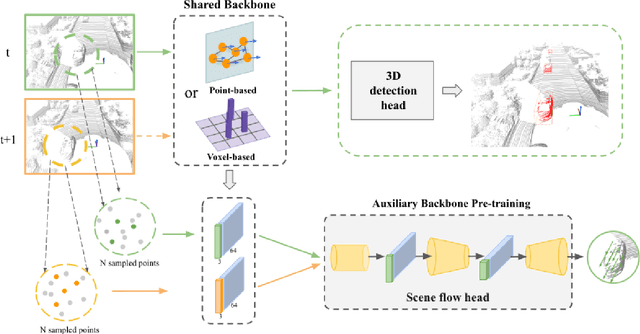
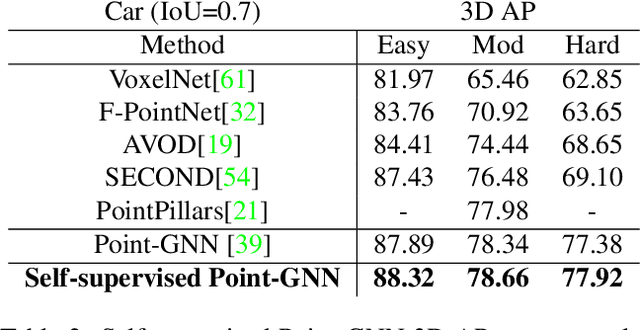
State-of-the-art 3D detection methods rely on supervised learning and large labelled datasets. However, annotating lidar data is resource-consuming, and depending only on supervised learning limits the applicability of trained models. Against this backdrop, here we propose using a self-supervised training strategy to learn a general point cloud backbone model for downstream 3D vision tasks. 3D scene flow can be estimated with self-supervised learning using cycle consistency, which removes labelled data requirements. Moreover, the perception of objects in the traffic scenarios heavily relies on making sense of the sparse data in the spatio-temporal context. Our main contribution leverages learned flow and motion representations and combines a self-supervised backbone with a 3D detection head focusing mainly on the relation between the scene flow and detection tasks. In this way, self-supervised scene flow training constructs point motion features in the backbone, which help distinguish objects based on their different motion patterns used with a 3D detection head. Experiments on KITTI and nuScenes benchmarks show that the proposed self-supervised pre-training increases 3D detection performance significantly.
Pedestrian Emergence Estimation and Occlusion-Aware Risk Assessment for Urban Autonomous Driving
Jul 06, 2021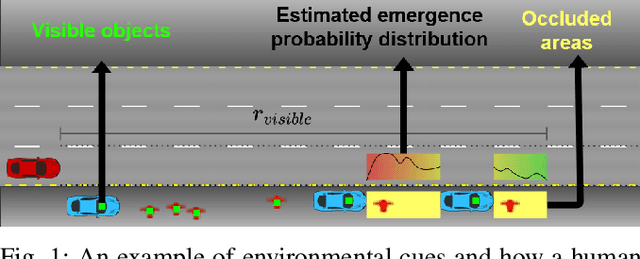

Avoiding unseen or partially occluded vulnerable road users (VRUs) is a major challenge for fully autonomous driving in urban scenes. However, occlusion-aware risk assessment systems have not been widely studied. Here, we propose a pedestrian emergence estimation and occlusion-aware risk assessment system for urban autonomous driving. First, the proposed system utilizes available contextual information, such as visible cars and pedestrians, to estimate pedestrian emergence probabilities in occluded regions. These probabilities are then used in a risk assessment framework, and incorporated into a longitudinal motion controller. The proposed controller is tested against several baseline controllers that recapitulate some commonly observed driving styles. The simulated test scenarios include randomly placed parked cars and pedestrians, most of whom are occluded from the ego vehicle's view and emerges randomly. The proposed controller outperformed the baselines in terms of safety and comfort measures.