 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Collision Momentum in Deep Reinforcement Learning Based Adversarial Pedestrian Modeling
Jun 13, 2023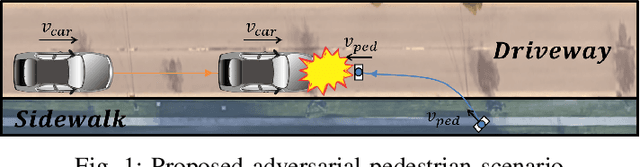

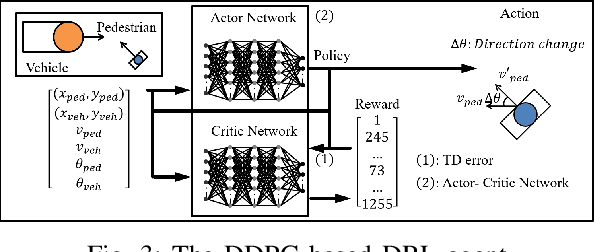
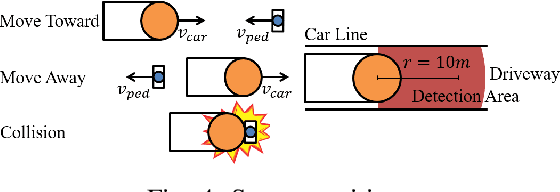
Recent research in pedestrian simulation often aims to develop realistic behaviors in various situations, but it is challenging for existing algorithms to generate behaviors that identify weaknesses in automated vehicles' performance in extreme and unlikely scenarios and edge cases. To address this, specialized pedestrian behavior algorithms are needed. Current research focuses on realistic trajectories using social force models and reinforcement learning based models. However, we propose a reinforcement learning algorithm that specifically targets collisions and better uncovers unique failure modes of automated vehicle controllers. Our algorithm is efficient and generates more severe collisions, allowing for the identification and correction of weaknesses in autonomous driving algorithms in complex and varied scenarios.
A Finite-Sampling, Operational Domain Specific, and Provably Unbiased Connected and Automated Vehicle Safety Metric
Nov 15, 2021



A connected and automated vehicle safety metric determines the performance of a subject vehicle (SV) by analyzing the data involving the interactions among the SV and other dynamic road users and environmental features. When the data set contains only a finite set of samples collected from the naturalistic mixed-traffic driving environment, a metric is expected to generalize the safety assessment outcome from the observed finite samples to the unobserved cases by specifying in what domain the SV is expected to be safe and how safe the SV is, statistically, in that domain. However, to the best of our knowledge, none of the existing safety metrics are able to justify the above properties with an operational domain specific, guaranteed complete, and provably unbiased safety evaluation outcome. In this paper, we propose a novel safety metric that involves the $\alpha$-shape and the $\epsilon$-almost robustly forward invariant set to characterize the SV's almost safe operable domain and the probability for the SV to remain inside the safe domain indefinitely, respectively. The empirical performance of the proposed method is demonstrated in several different operational design domains through a series of cases covering a variety of fidelity levels (real-world and simulators), driving environments (highway, urban, and intersections), road users (car, truck, and pedestrian), and SV driving behaviors (human driver and self driving algorithms).
A Formal Characterization of Black-Box System Safety Performance with Scenario Sampling
Oct 05, 2021
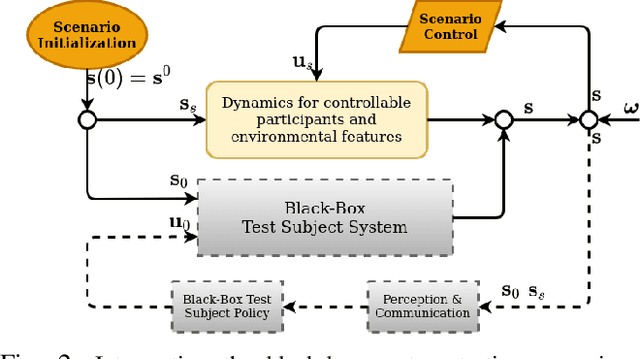


A typical scenario-based evaluation framework seeks to characterize a black-box system's safety performance (e.g., failure rate) through repeatedly sampling initialization configurations (scenario sampling) and executing a certain test policy for scenario propagation (scenario testing) with the black-box system involved as the test subject. In this letter, we first present a novel safety evaluation criterion that seeks to characterize the actual operational domain within which the test subject would remain safe indefinitely with high probability. By formulating the black-box testing scenario as a dynamic system, we show that the presented problem is equivalent to finding a certain "almost" robustly forward invariant set for the given system. Second, for an arbitrary scenario testing strategy, we propose a scenario sampling algorithm that is provably asymptotically optimal in obtaining the safe invariant set with arbitrarily high accuracy. Moreover, as one considers different testing strategies (e.g., biased sampling of safety-critical cases), we show that the proposed algorithm still converges to the unbiased approximation of the safety characterization outcome if the scenario testing satisfies a certain condition. Finally, the effectiveness of the presented scenario sampling algorithms and various theoretical properties are demonstrated in a case study of the safety evaluation of a control barrier function-based mobile robot collision avoidance system.
Pedestrian Emergence Estimation and Occlusion-Aware Risk Assessment for Urban Autonomous Driving
Jul 06, 2021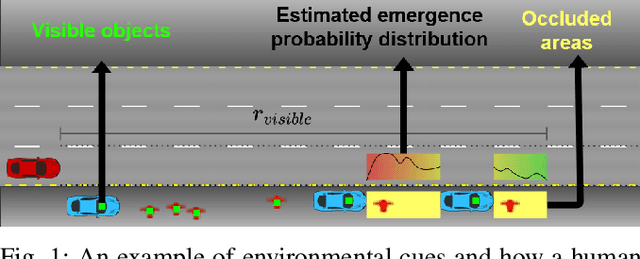

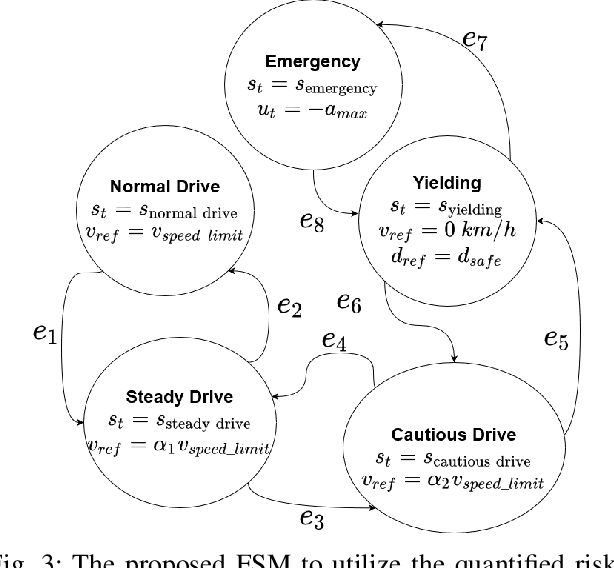
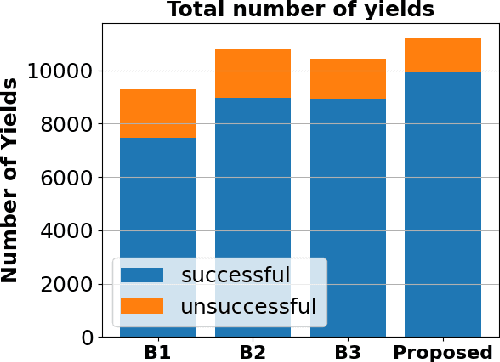
Avoiding unseen or partially occluded vulnerable road users (VRUs) is a major challenge for fully autonomous driving in urban scenes. However, occlusion-aware risk assessment systems have not been widely studied. Here, we propose a pedestrian emergence estimation and occlusion-aware risk assessment system for urban autonomous driving. First, the proposed system utilizes available contextual information, such as visible cars and pedestrians, to estimate pedestrian emergence probabilities in occluded regions. These probabilities are then used in a risk assessment framework, and incorporated into a longitudinal motion controller. The proposed controller is tested against several baseline controllers that recapitulate some commonly observed driving styles. The simulated test scenarios include randomly placed parked cars and pedestrians, most of whom are occluded from the ego vehicle's view and emerges randomly. The proposed controller outperformed the baselines in terms of safety and comfort measures.
Towards Guaranteed Safety Assurance of Automated Driving Systems with Scenario Sampling: An Invariant Set Perspective (Extended Version)
Apr 23, 2021
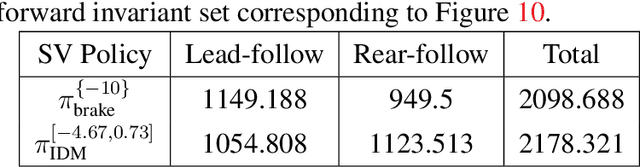
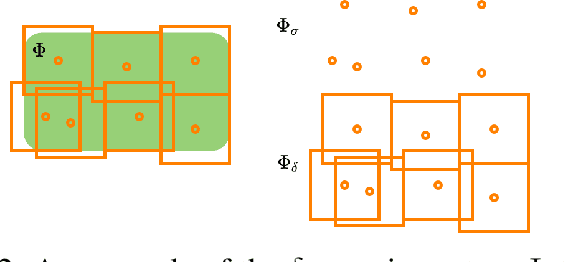
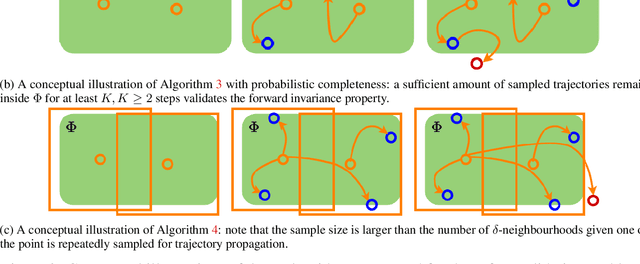
How many scenarios are sufficient to validate the safe Operational Design Domain (ODD) of an Automated Driving System (ADS) equipped vehicle? Is a more significant number of sampled scenarios guaranteeing a more accurate safety assessment of the ADS? Despite the various empirical success of ADS safety evaluation with scenario sampling in practice, some of the fundamental properties are largely unknown. This paper seeks to remedy this gap by formulating and tackling the scenario sampling safety assurance problem from a set invariance perspective. First, a novel conceptual equivalence is drawn between the scenario sampling safety assurance problem and the data-driven robustly controlled forward invariant set validation and quantification problem. This paper then provides a series of resolution complete and probabilistic complete solutions with finite-sampling analyses for the safety validation problem that authenticates a given ODD. On the other hand, the quantification problem escalates the validation challenge and starts looking for a safe sub-domain of a particular property. This inspires various algorithms that are provably probabilistic incomplete, probabilistic complete but sub-optimal, and asymptotically optimal. Finally, the proposed asymptotically optimal scenario sampling safety quantification algorithm is also empirically demonstrated through simulation experiments.
A Modeled Approach for Online Adversarial Test of Operational Vehicle Safety
Sep 28, 2020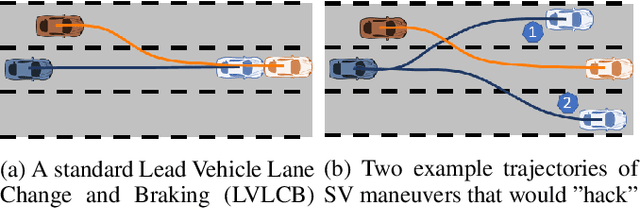
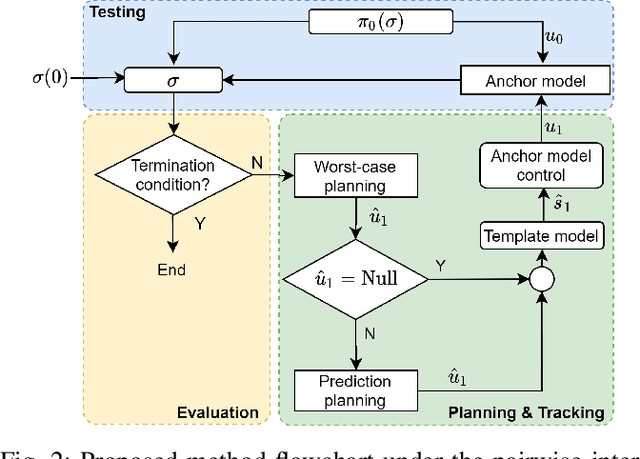
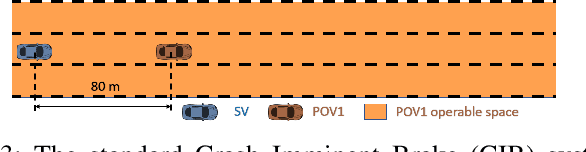
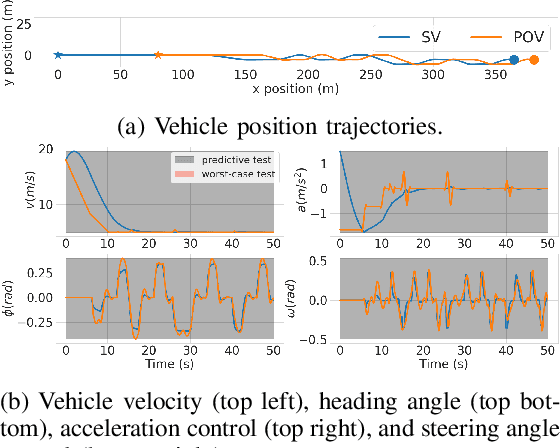
The scenario-based testing of operational vehicle safety presents a set of principal other vehicle (POV) trajectories that seek to force the subject vehicle (SV) into a certain safety-critical situation. Current scenarios are mostly (i) statistics-driven: inspired by human driver crash data, (ii) deterministic: POV trajectories are pre-determined and are independent of SV responses, and (iii) overly simplified: defined over a finite set of actions performed at the abstracted motion planning level. Such scenario-based testing (i) lacks severity guarantees, (ii) is easy for SV to game the test with intelligent driving policies, and (iii) is inefficient in producing safety-critical instances with limited and expensive testing effort. In this paper, the authors propose a model-driven online feedback control policy for multiple POVs which propagates efficient adversarial trajectories while respecting traffic rules and other concerns formulated as an admissible state-action space. The proposed approach is formulated in an anchor-template hierarchy structure, with the template model planning inducing a theoretical SV capturing guarantee under standard assumptions. The planned adversarial trajectory is then tracked by a lower-level controller applied to the full-system or the anchor model. The effectiveness of the proposed methodology is illustrated through various simulated examples with the SV controlled by either parameterized self-driving policies or human drivers.
An online evolving framework for advancing reinforcement-learning based automated vehicle control
Jun 16, 2020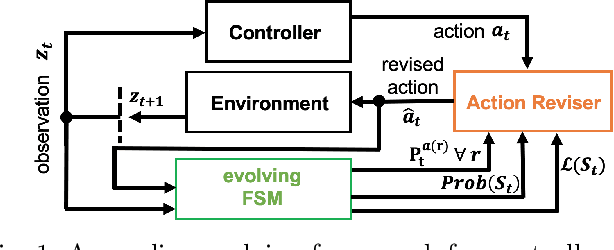

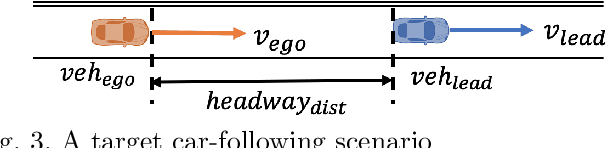
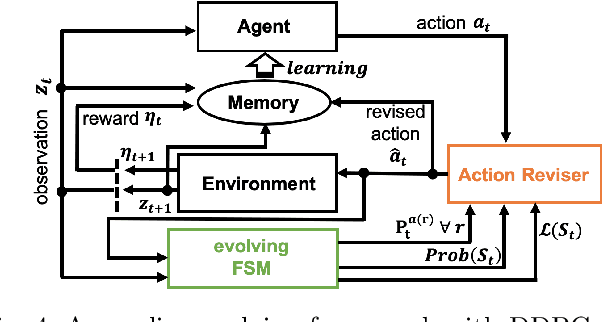
In this paper, an online evolving framework is proposed to detect and revise a controller's imperfect decision-making in advance. The framework consists of three modules: the evolving Finite State Machine (e-FSM), action-reviser, and controller modules. The e-FSM module evolves a stochastic model (e.g., Discrete-Time Markov Chain) from scratch by determining new states and identifying transition probabilities repeatedly. With the latest stochastic model and given criteria, the action-reviser module checks validity of the controller's chosen action by predicting future states. Then, if the chosen action is not appropriate, another action is inspected and selected. In order to show the advantage of the proposed framework, the Deep Deterministic Policy Gradient (DDPG) w/ and w/o the online evolving framework are applied to control an ego-vehicle in the car-following scenario where control criteria are set by speed and safety. Experimental results show that inappropriate actions chosen by the DDPG controller are detected and revised appropriately through our proposed framework, resulting in no control failures after a few iterations.
Optical Flow based Visual Potential Field for Autonomous Driving
May 30, 2020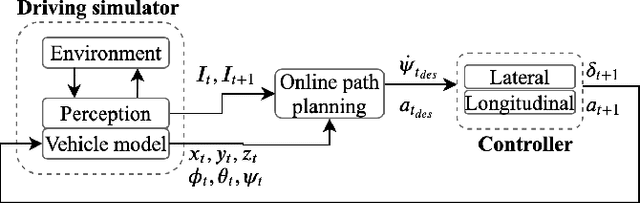


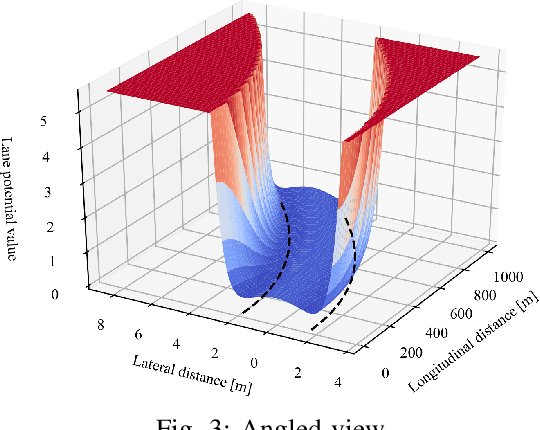
Monocular vision-based navigation for automated driving is a challenging task due to the lack of enough information to compute temporal relationships among objects on the road. Optical flow is an option to obtain temporal information from monocular camera images and has been used widely with the purpose of identifying objects and their relative motion. This work proposes to generate an artificial potential field, i.e. visual potential field, from a sequence of images using sparse optical flow, which is used together with a gradient tracking sliding mode controller to navigate the vehicle to destination without collision with obstacles. The angular reference for the vehicle is computed online. This work considers that the vehicle does not require to have a priori information from the map or obstacles to navigate successfully. The proposed technique is tested both in synthetic and real images.
A Multi-State Social Force Based Framework for Vehicle-Pedestrian Interaction in Uncontrolled Pedestrian Crossing Scenarios
May 15, 2020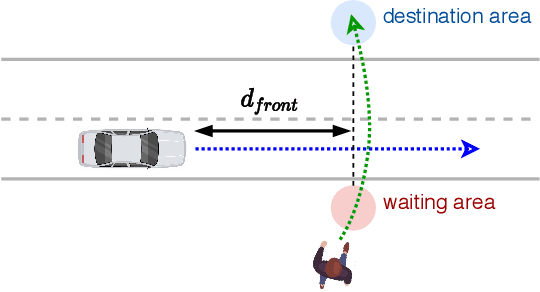
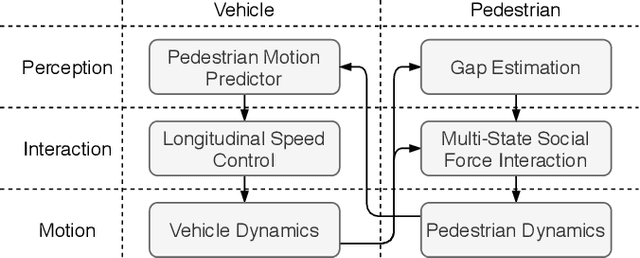
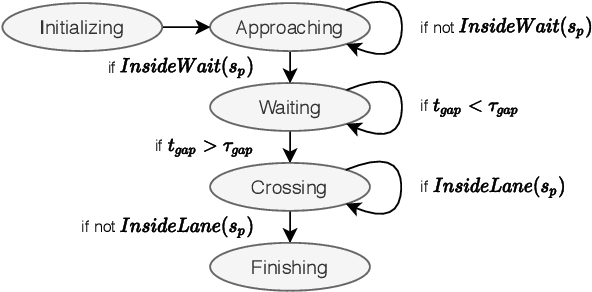
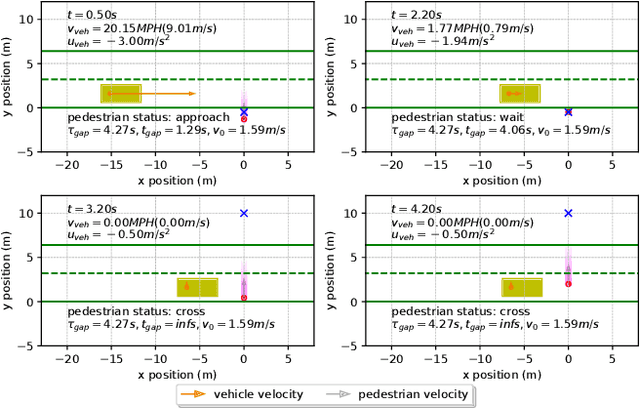
Vehicle-pedestrian interaction (VPI) is one of the most challenging tasks for automated driving systems. The design of driving strategies for such systems usually starts with verifying VPI in simulation. This work proposed an improved framework for the study of VPI in uncontrolled pedestrian crossing scenarios. The framework admits the mutual effect between the pedestrian and the vehicle. A multi-state social force based pedestrian motion model was designed to describe the microscopic motion of the pedestrian crossing behavior. The pedestrian model considers major interaction factors such as the accepted gap of the pedestrian's decision on when to start crossing, the desired speed of the pedestrian, and the effect of the vehicle on the pedestrian while the pedestrian is crossing the road. Vehicle driving strategies focus on the longitudinal motion control, for which the feedback obstacle avoidance control and the model predictive control were tested and compared in the framework. The simulation results verified that the proposed framework can generate a variety of VPI scenarios, consisting of either the pedestrian yielding to the vehicle or the vehicle yielding to the pedestrian. The framework can be easily extended to apply different approaches to the VPI problems.
Integrating Deep Reinforcement Learning with Model-based Path Planners for Automated Driving
Feb 02, 2020



Automated driving in urban settings is challenging chiefly due to the indeterministic nature of the human participants of the traffic. These behaviors are difficult to model, and conventional, rule-based Automated Driving Systems (ADSs) tend to fail when they face unmodeled dynamics. On the other hand, the more recent, end-to-end Deep Reinforcement Learning (DRL) based ADSs have shown promising results. However, pure learning-based approaches lack the hard-coded safety measures of model-based methods. Here we propose a hybrid approach that integrates a model-based path planner into a vision based DRL framework to alleviate the shortcomings of both worlds. In summary, the DRL agent learns to overrule the model-based planner's decisions if it predicts that better future rewards can be obtained while doing so, e.g., avoiding an accident. Otherwise, the DRL agent tends to follow the model-based planner as close as possible. This logic is learned, i.e., no switching model is designed here. The agent learns this by considering two penalties: the penalty of straying away from the model-based path planner and the penalty of having a collision. The latter has precedence over the former, i.e., the penalty is greater. Therefore, after training, the agent learns to follow the model-based planner when it is safe to do so, otherwise, it gets penalized. However, it also learns to sacrifice positive rewards for following the model-based planner to avoid a potential big negative penalty for making a collision in the future. Experimental results show that the proposed method can plan its path and navigate while avoiding obstacles between randomly chosen origin-destination points in CARLA, a dynamic urban simulation environment. Our code is open-source and available online.