 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Harmonic Loss: Towards Task-consistent and Time-friendly 3D Object Detection on Edge for V2X Orchestration
Nov 12, 2022



Edge computing-based 3D perception has received attention in intelligent transportation systems (ITS) because real-time monitoring of traffic candidates potentially strengthens Vehicle-to-Everything (V2X) orchestration. Thanks to the capability of precisely measuring the depth information on surroundings from LiDAR, the increasing studies focus on lidar-based 3D detection, which significantly promotes the development of 3D perception. Few methods met the real-time requirement of edge deployment because of high computation-intensive operations. Moreover, an inconsistency problem of object detection remains uncovered in the pointcloud domain due to large sparsity. This paper thoroughly analyses this problem, comprehensively roused by recent works on determining inconsistency problems in the image specialisation. Therefore, we proposed a 3D harmonic loss function to relieve the pointcloud based inconsistent predictions. Moreover, the feasibility of 3D harmonic loss is demonstrated from a mathematical optimization perspective. The KITTI dataset and DAIR-V2X-I dataset are used for simulations, and our proposed method considerably improves the performance than benchmark models. Further, the simulative deployment on an edge device (Jetson Xavier TX) validates our proposed model's efficiency.
Predicting Pedestrian Crossing Intention with Feature Fusion and Spatio-Temporal Attention
Apr 12, 2021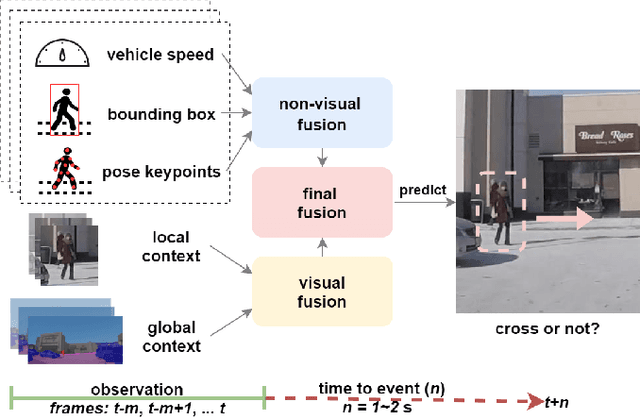
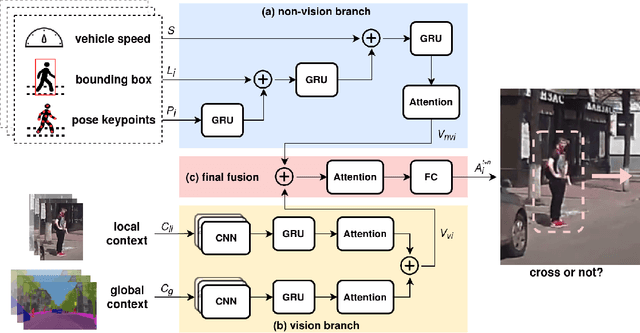
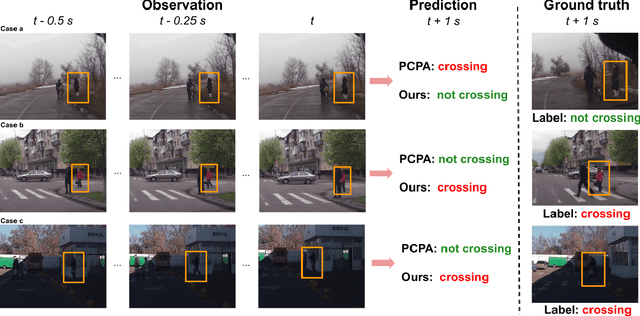
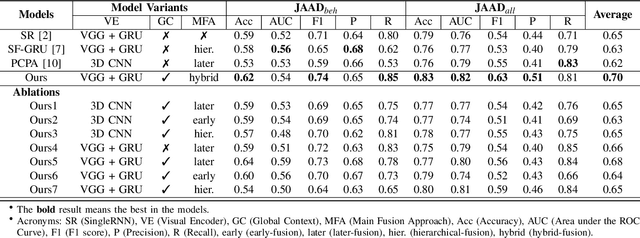
Predicting vulnerable road user behavior is an essential prerequisite for deploying Automated Driving Systems (ADS) in the real-world. Pedestrian crossing intention should be recognized in real-time, especially for urban driving. Recent works have shown the potential of using vision-based deep neural network models for this task. However, these models are not robust and certain issues still need to be resolved. First, the global spatio-temproal context that accounts for the interaction between the target pedestrian and the scene has not been properly utilized. Second, the optimum strategy for fusing different sensor data has not been thoroughly investigated. This work addresses the above limitations by introducing a novel neural network architecture to fuse inherently different spatio-temporal features for pedestrian crossing intention prediction. We fuse different phenomena such as sequences of RGB imagery, semantic segmentation masks, and ego-vehicle speed in an optimum way using attention mechanisms and a stack of recurrent neural networks. The optimum architecture was obtained through exhaustive ablation and comparison studies. Extensive comparative experiments on the JAAD pedestrian action prediction benchmark demonstrate the effectiveness of the proposed method, where state-of-the-art performance was achieved. Our code is open-source and publicly available.
On the Generalizability of Motion Models for Road Users in Heterogeneous Shared Traffic Spaces
Jan 18, 2021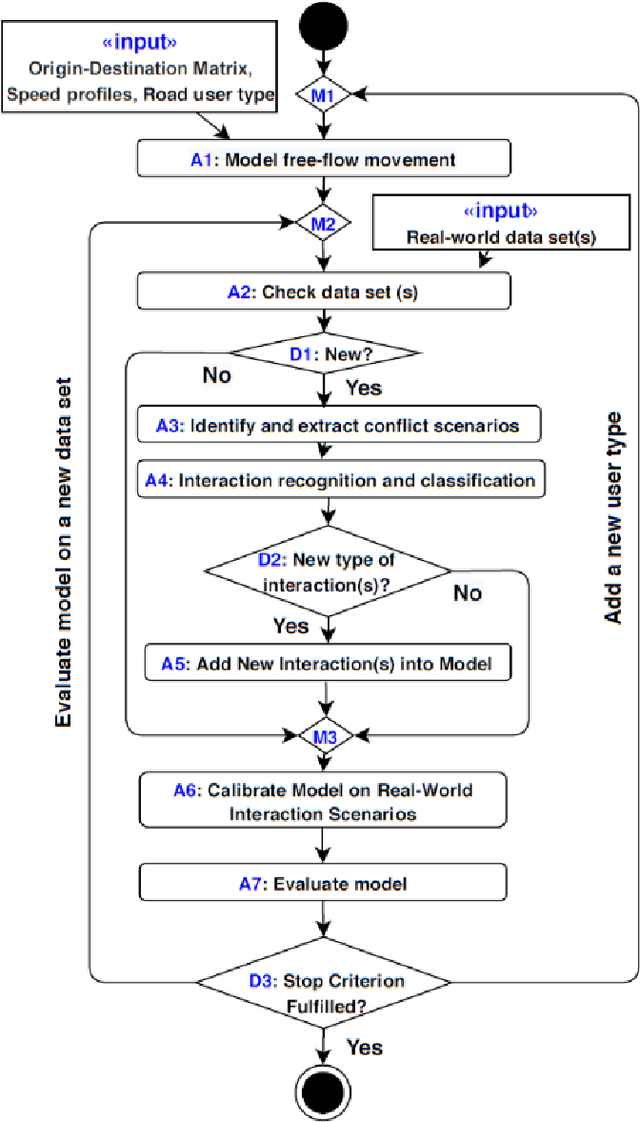
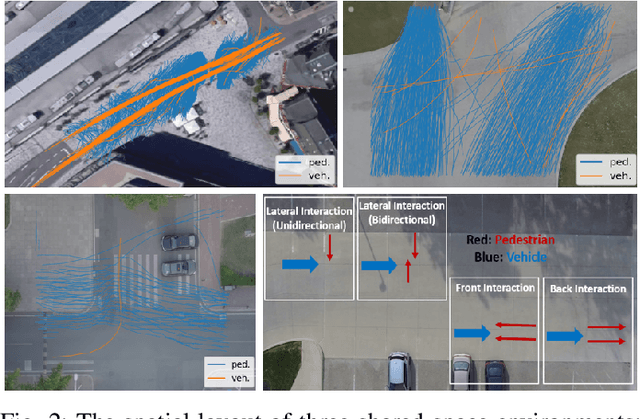

Modeling mixed-traffic motion and interactions is crucial to assess safety, efficiency, and feasibility of future urban areas. The lack of traffic regulations, diverse transport modes, and the dynamic nature of mixed-traffic zones like shared spaces make realistic modeling of such environments challenging. This paper focuses on the generalizability of the motion model, i.e., its ability to generate realistic behavior in different environmental settings, an aspect which is lacking in existing works. Specifically, our first contribution is a novel and systematic process of formulating general motion models and application of this process is to extend our Game-Theoretic Social Force Model (GSFM) towards a general model for generating a large variety of motion behaviors of pedestrians and cars from different shared spaces. Our second contribution is to consider different motion patterns of pedestrians by calibrating motion-related features of individual pedestrian and clustering them into groups. We analyze two clustering approaches. The calibration and evaluation of our model are performed on three different shared space data sets. The results indicate that our model can realistically simulate a wide range of motion behaviors and interaction scenarios, and that adding different motion patterns of pedestrians into our model improves its performance.
Sub-Goal Social Force Model for Collective Pedestrian Motion Under Vehicle Influence
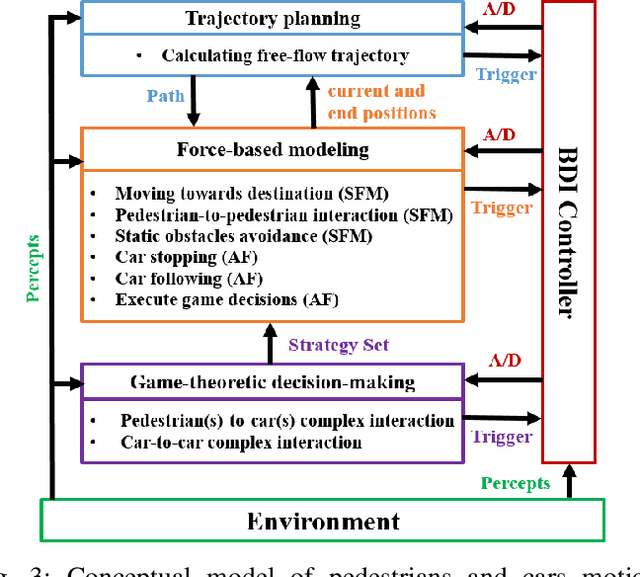
Jan 10, 2021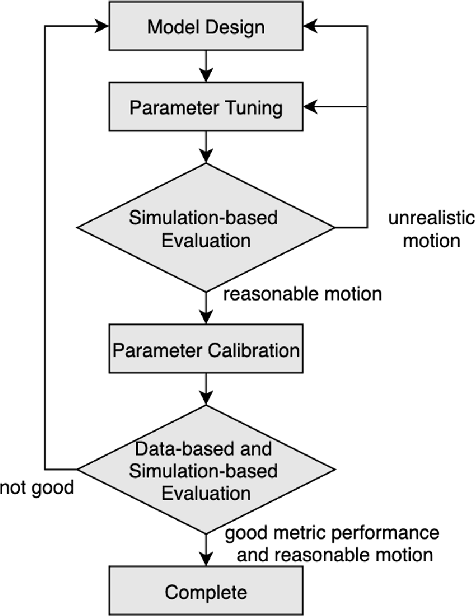
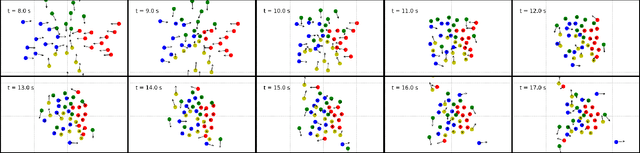
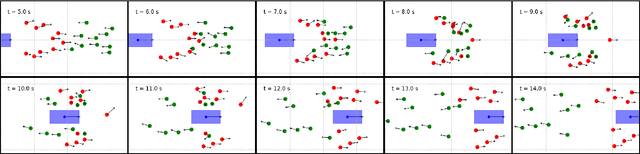
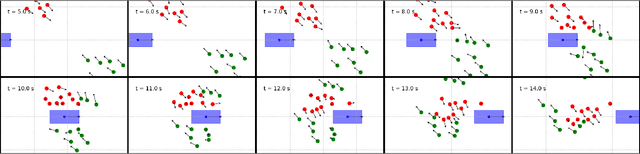
In mixed traffic scenarios, a certain number of pedestrians might coexist in a small area while interacting with vehicles. In this situation, every pedestrian must simultaneously react to the surrounding pedestrians and vehicles. Analytical modeling of such collective pedestrian motion can benefit intelligent transportation practices like shared space design and urban autonomous driving. This work proposed the sub-goal social force model (SG-SFM) to describe the collective pedestrian motion under vehicle influence. The proposed model introduced a new design of vehicle influence on pedestrian motion, which was smoothly combined with the influence of surrounding pedestrians using the sub-goal concept. This model aims to describe generalized pedestrian motion, i.e., it is applicable to various vehicle-pedestrian interaction patterns. The generalization was verified by both quantitative and qualitative evaluation. The quantitative evaluation was conducted to reproduce pedestrian motion in three different datasets, HBS, CITR, and DUT. It also compared two different ways of calibrating the model parameters. The qualitative evaluation examined the simulation of collective pedestrian motion in a series of fundamental vehicle-pedestrian interaction scenarios. The above evaluation results demonstrated the effectiveness of the proposed model.
Faraway-Frustum: Dealing with Lidar Sparsity for 3D Object Detection using Fusion
Nov 03, 2020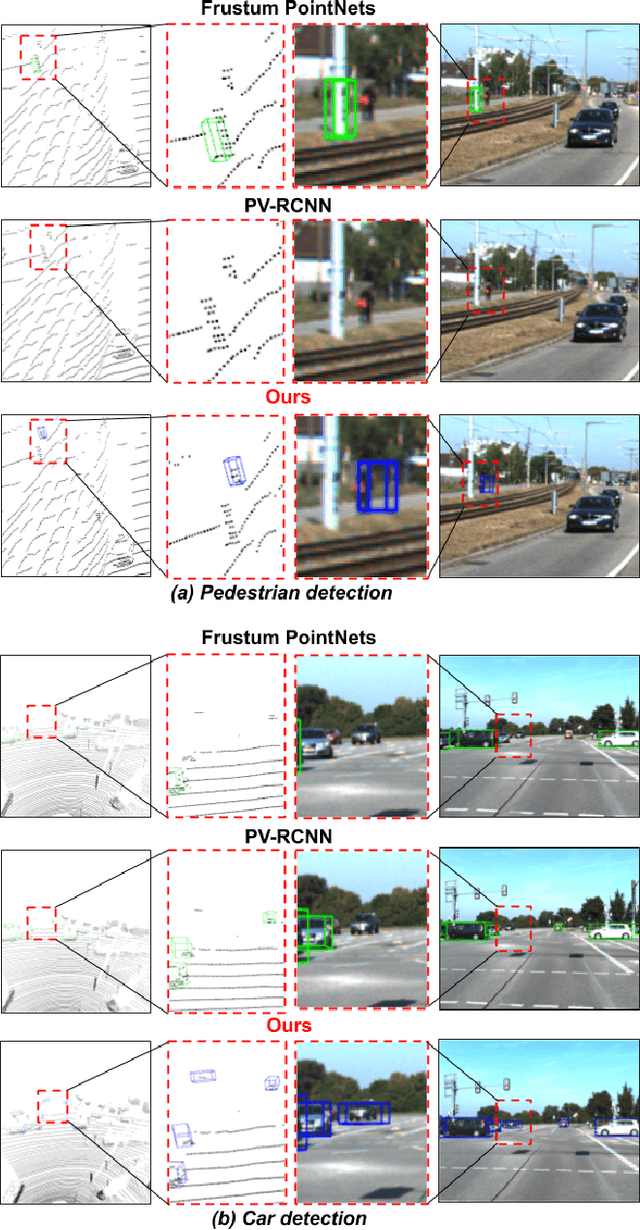
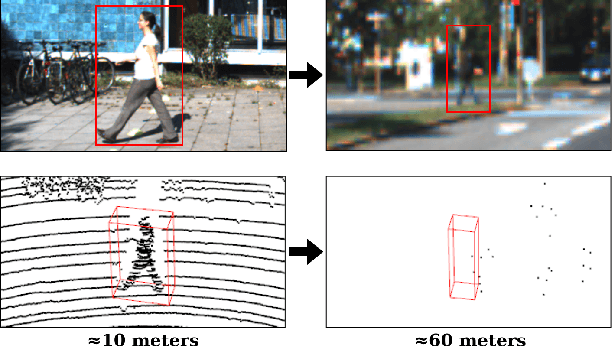

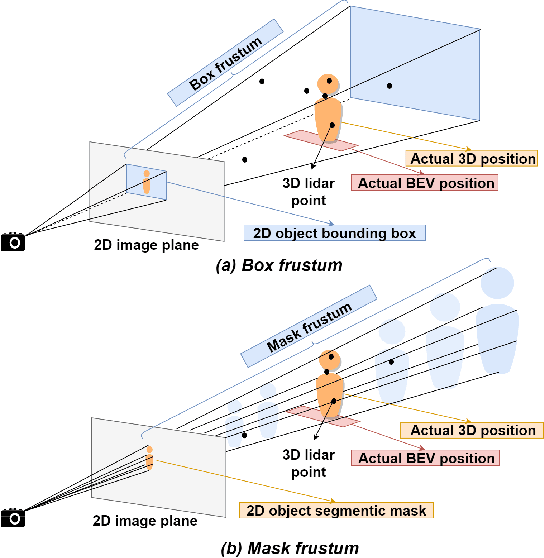
Learned pointcloud representations do not generalize well with an increase in distance to the sensor. For example, at a range greater than 60 meters, the sparsity of lidar pointclouds reaches to a point where even humans cannot discern object shapes from each other. However, this distance should not be considered very far for fast-moving vehicles: A vehicle can traverse 60 meters under two seconds while moving at 70 mph. For safe and robust driving automation, acute 3D object detection at these ranges is indispensable. Against this backdrop, we introduce faraway-frustum: a novel fusion strategy for detecting faraway objects. The main strategy is to depend solely on the 2D vision for recognizing object class, as object shape does not change drastically with an increase in depth, and use pointcloud data for object localization in the 3D space for faraway objects. For closer objects, we use learned pointcloud representations instead, following state-of-the-art. This strategy alleviates the main shortcoming of object detection with learned pointcloud representations. Experiments on the KITTI dataset demonstrate that our method outperforms state-of-the-art by a considerable margin for faraway object detection in bird's-eye-view and 3D.
Blending Generative Adversarial Image Synthesis with Rendering for Computer Graphics
Jul 31, 2020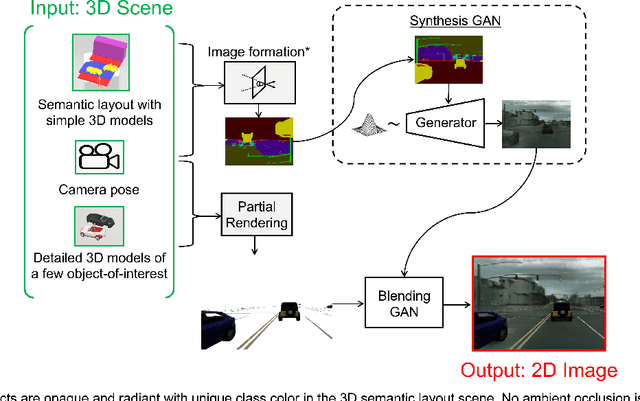
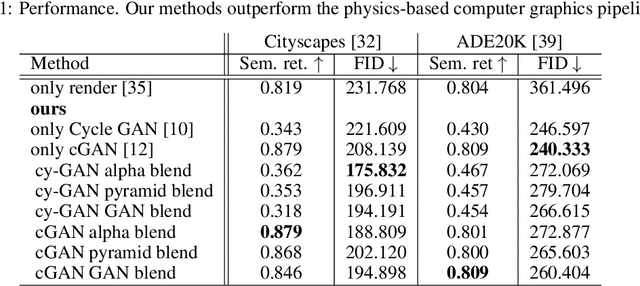
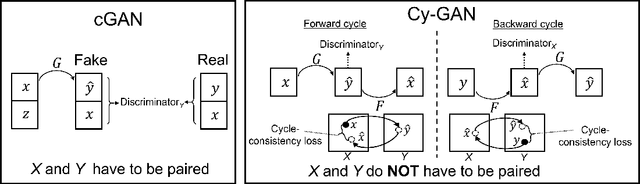

Conventional computer graphics pipelines require detailed 3D models, meshes, textures, and rendering engines to generate 2D images from 3D scenes. These processes are labor-intensive. We introduce Hybrid Neural Computer Graphics (HNCG) as an alternative. The contribution is a novel image formation strategy to reduce the 3D model and texture complexity of computer graphics pipelines. Our main idea is straightforward: Given a 3D scene, render only important objects of interest and use generative adversarial processes for synthesizing the rest of the image. To this end, we propose a novel image formation strategy to form 2D semantic images from 3D scenery consisting of simple object models without textures. These semantic images are then converted into photo-realistic RGB images with a state-of-the-art conditional Generative Adversarial Network (cGAN) based image synthesizer trained on real-world data. Meanwhile, objects of interest are rendered using a physics-based graphics engine. This is necessary as we want to have full control over the appearance of objects of interest. Finally, the partially-rendered and cGAN synthesized images are blended with a blending GAN. We show that the proposed framework outperforms conventional rendering with ablation and comparison studies. Semantic retention and Fr\'echet Inception Distance (FID) measurements were used as the main performance metrics.
A Vision-based Social Distancing and Critical Density Detection System for COVID-19
Jul 08, 2020
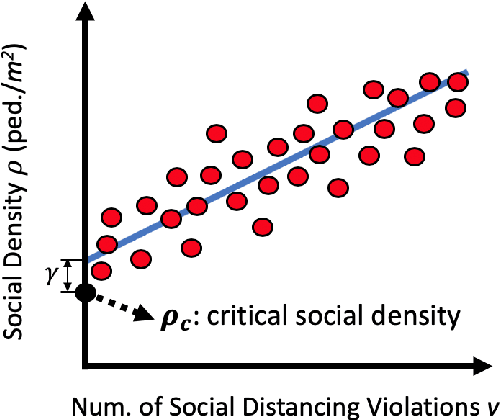
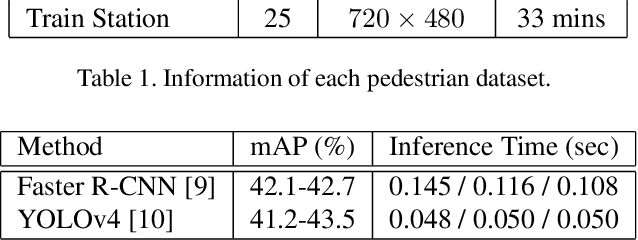
Social distancing has been proven as an effective measure against the spread of the infectious COronaVIrus Disease 2019 (COVID-19). However, individuals are not used to tracking the required 6-feet (2-meters) distance between themselves and their surroundings. An active surveillance system capable of detecting distances between individuals and warning them can slow down the spread of the deadly disease. Furthermore, measuring social density in a region of interest (ROI) and modulating inflow can decrease social distancing violation occurrence chance. On the other hand, recording data and labeling individuals who do not follow the measures will breach individuals' rights in free-societies. Here we propose an Artificial Intelligence (AI) based real-time social distancing detection and warning system considering four important ethical factors: (1) the system should never record/cache data, (2) the warnings should not target the individuals, (3) no human supervisor should be in the detection/warning loop, and (4) the code should be open-source and accessible to the public. Against this backdrop, we propose using a monocular camera and deep learning-based real-time object detectors to measure social distancing. If a violation is detected, a non-intrusive audio-visual warning signal is emitted without targeting the individual who breached the social distancing measure. Also, if the social density is over a critical value, the system sends a control signal to modulate inflow into the ROI. We tested the proposed method across real-world datasets to measure its generality and performance. The proposed method is ready for deployment, and our code is open-sourced.
A Multi-State Social Force Based Framework for Vehicle-Pedestrian Interaction in Uncontrolled Pedestrian Crossing Scenarios
May 15, 2020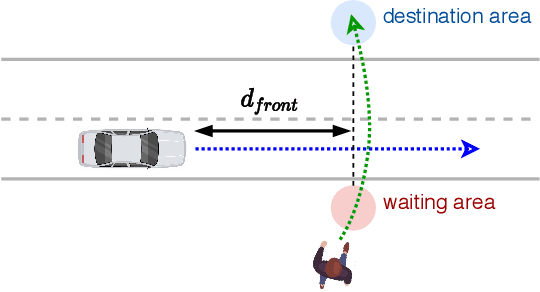
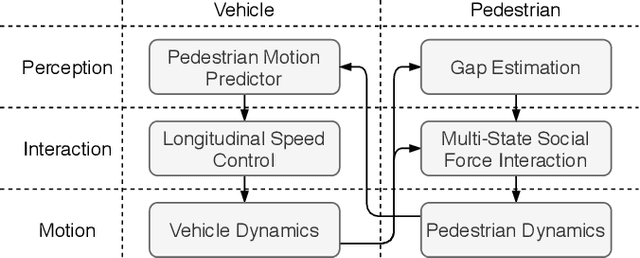
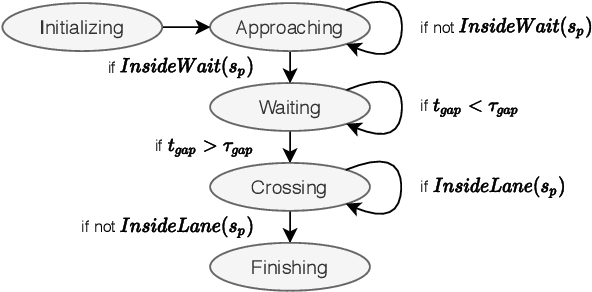
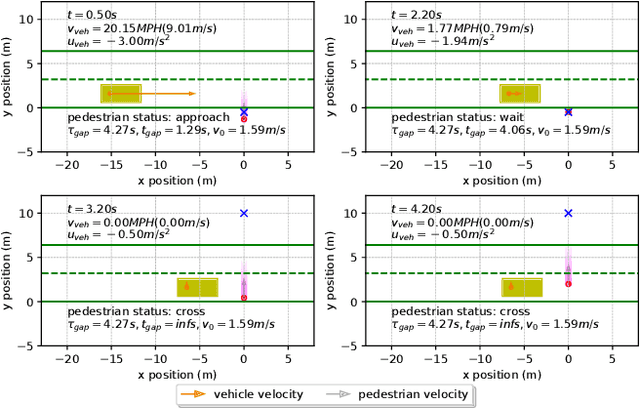
Vehicle-pedestrian interaction (VPI) is one of the most challenging tasks for automated driving systems. The design of driving strategies for such systems usually starts with verifying VPI in simulation. This work proposed an improved framework for the study of VPI in uncontrolled pedestrian crossing scenarios. The framework admits the mutual effect between the pedestrian and the vehicle. A multi-state social force based pedestrian motion model was designed to describe the microscopic motion of the pedestrian crossing behavior. The pedestrian model considers major interaction factors such as the accepted gap of the pedestrian's decision on when to start crossing, the desired speed of the pedestrian, and the effect of the vehicle on the pedestrian while the pedestrian is crossing the road. Vehicle driving strategies focus on the longitudinal motion control, for which the feedback obstacle avoidance control and the model predictive control were tested and compared in the framework. The simulation results verified that the proposed framework can generate a variety of VPI scenarios, consisting of either the pedestrian yielding to the vehicle or the vehicle yielding to the pedestrian. The framework can be easily extended to apply different approaches to the VPI problems.
Road-network-based Rapid Geolocalization
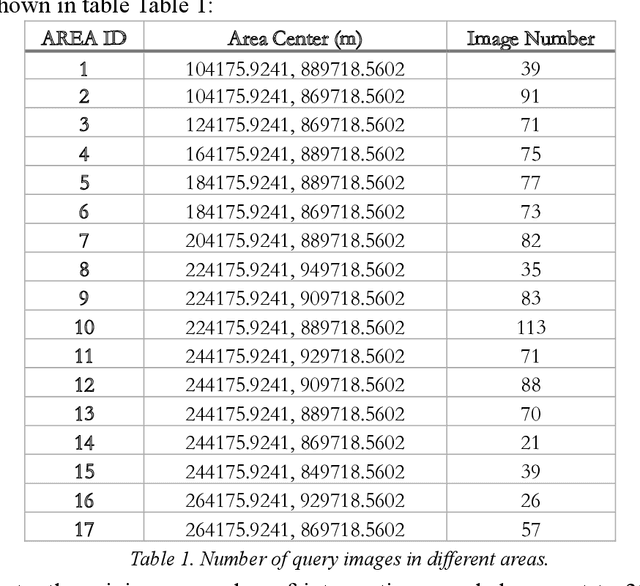
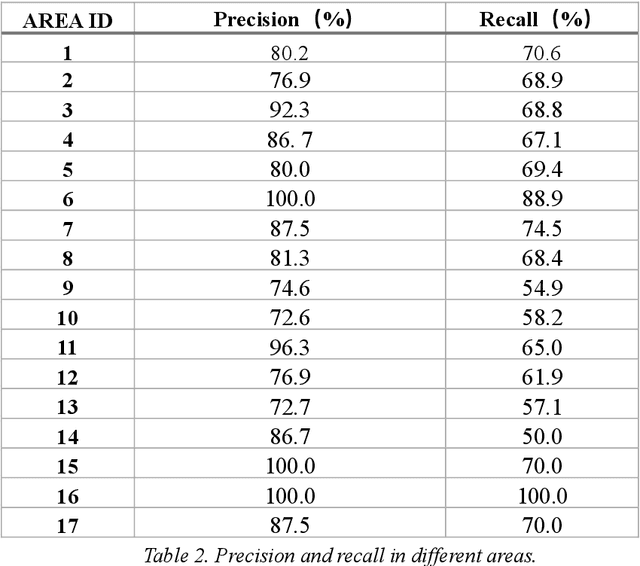
Jun 25, 2019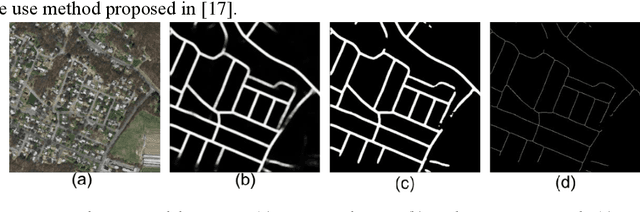

It has always been a research hotspot to use geographic information to assist the navigation of unmanned aerial vehicles. In this paper, a road-network-based localization method is proposed. We match roads in the measurement images to the reference road vector map, and realize successful localization on areas as large as a whole city. The road network matching problem is treated as a point cloud registration problem under two-dimensional projective transformation, and solved under a hypothesise-and-test framework. To deal with the projective point cloud registration problem, a global projective invariant feature is proposed, which consists of two road intersections augmented with the information of their tangents. We call it two road intersections tuple. We deduce the closed-form solution for determining the alignment transformation from a pair of matching two road intersections tuples. In addition, we propose the necessary conditions for the tuples to match. This can reduce the candidate matching tuples, thus accelerating the search to a great extent. We test all the candidate matching tuples under a hypothesise-and-test framework to search for the best match. The experiments show that our method can localize the target area over an area of 400 within 1 second on a single cpu.
Top-view Trajectories: A Pedestrian Dataset of Vehicle-Crowd Interaction from Controlled Experiments and Crowded Campus
Feb 01, 2019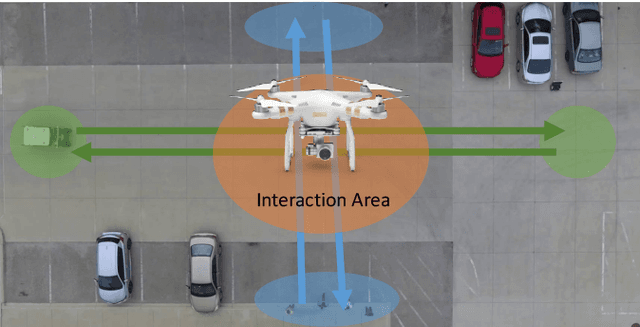
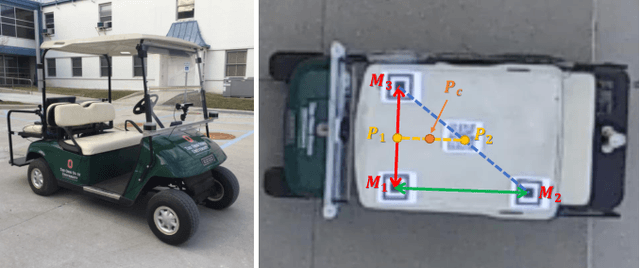
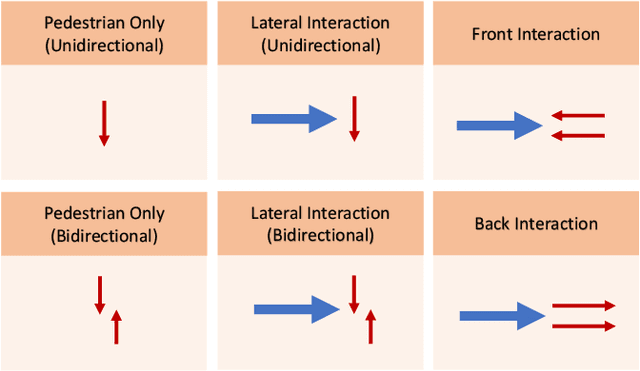
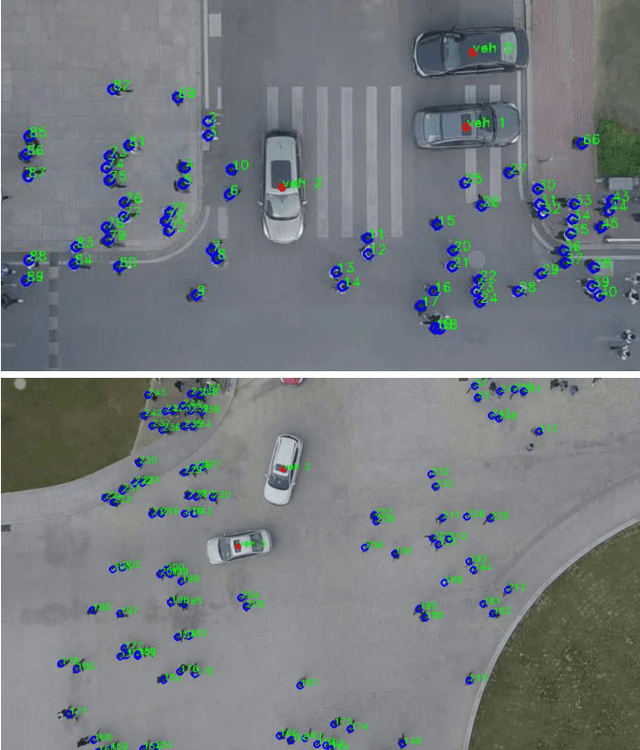
Predicting the collective motion of a group of pedestrians (a crowd) under the vehicle influence is essential for the development of autonomous vehicles to deal with mixed urban scenarios where interpersonal interaction and vehicle-crowd interaction (VCI) are significant. This usually requires a model that can describe individual pedestrian motion under the influence of nearby pedestrians and the vehicle. This study proposed two pedestrian trajectory dataset, CITR dataset and DUT dataset, so that the pedestrian motion models can be further calibrated and verified, especially when vehicle influence on pedestrians plays an important role. CITR dataset consists of experimentally designed fundamental VCI scenarios (front, back, and lateral VCIs) and provides unique ID for each pedestrian, which is suitable for exploring a specific aspect of VCI. DUT dataset gives two ordinary and natural VCI scenarios in crowded university campus, which can be used for more general purpose VCI exploration. The trajectories of pedestrians, as well as vehicles, were extracted by processing video frames that come from a down-facing camera mounted on a hovering drone as the recording equipment. The final trajectories were refined by a Kalman Filter, in which the pedestrian velocity was also estimated. The statistics of the velocity magnitude distribution demonstrated the validity of the proposed dataset. In total, there are approximate 340 pedestrian trajectories in CITR dataset and 1793 pedestrian trajectories in DUT dataset. The dataset is available at GitHub.