 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Model Predictive Control via Self-Supervised Initialization Learning
Aug 06, 2024



Optimization for robot control tasks, spanning various methodologies, includes Model Predictive Control (MPC). However, the complexity of the system, such as non-convex and non-differentiable cost functions and prolonged planning horizons often drastically increases the computation time, limiting MPC's real-world applicability. Prior works in speeding up the optimization have limitations on solving convex problem and generalizing to hold out domains. To overcome this challenge, we develop a novel framework aiming at expediting optimization processes. In our framework, we combine offline self-supervised learning and online fine-tuning through reinforcement learning to improve the control performance and reduce optimization time. We demonstrate the effectiveness of our method on a novel, challenging Formula-1-track driving task, achieving 3.9\% higher performance in optimization time and 3.6\% higher performance in tracking accuracy on challenging holdout tracks.
Interpretable Reinforcement Learning for Robotics and Continuous Control
Nov 16, 2023



Interpretability in machine learning is critical for the safe deployment of learned policies across legally-regulated and safety-critical domains. While gradient-based approaches in reinforcement learning have achieved tremendous success in learning policies for continuous control problems such as robotics and autonomous driving, the lack of interpretability is a fundamental barrier to adoption. We propose Interpretable Continuous Control Trees (ICCTs), a tree-based model that can be optimized via modern, gradient-based, reinforcement learning approaches to produce high-performing, interpretable policies. The key to our approach is a procedure for allowing direct optimization in a sparse decision-tree-like representation. We validate ICCTs against baselines across six domains, showing that ICCTs are capable of learning policies that parity or outperform baselines by up to 33% in autonomous driving scenarios while achieving a 300x-600x reduction in the number of parameters against deep learning baselines. We prove that ICCTs can serve as universal function approximators and display analytically that ICCTs can be verified in linear time. Furthermore, we deploy ICCTs in two realistic driving domains, based on interstate Highway-94 and 280 in the US. Finally, we verify ICCT's utility with end-users and find that ICCTs are rated easier to simulate, quicker to validate, and more interpretable than neural networks.
Robust AI Driving Strategy for Autonomous Vehicles
Jul 16, 2022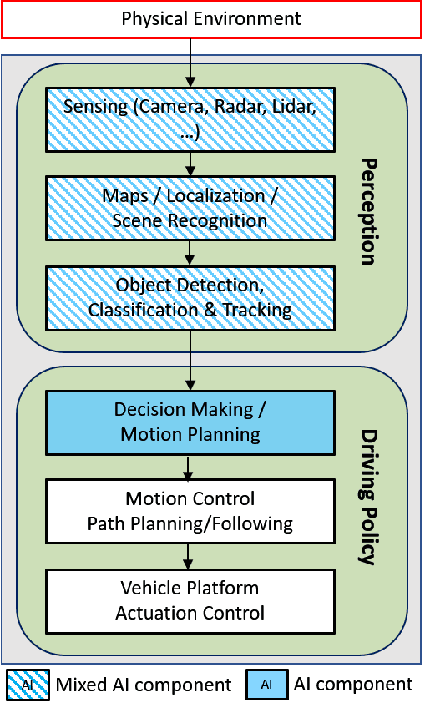

There has been significant progress in sensing, perception, and localization for automated driving, However, due to the wide spectrum of traffic/road structure scenarios and the long tail distribution of human driver behavior, it has remained an open challenge for an intelligent vehicle to always know how to make and execute the best decision on road given available sensing / perception / localization information. In this chapter, we talk about how artificial intelligence and more specifically, reinforcement learning, can take advantage of operational knowledge and safety reflex to make strategical and tactical decisions. We discuss some challenging problems related to the robustness of reinforcement learning solutions and their implications to the practical design of driving strategies for autonomous vehicles. We focus on automated driving on highway and the integration of reinforcement learning, vehicle motion control, and control barrier function, leading to a robust AI driving strategy that can learn and adapt safely.
Assured Learning-enabled Autonomy: A Metacognitive Reinforcement Learning Framework
Apr 17, 2021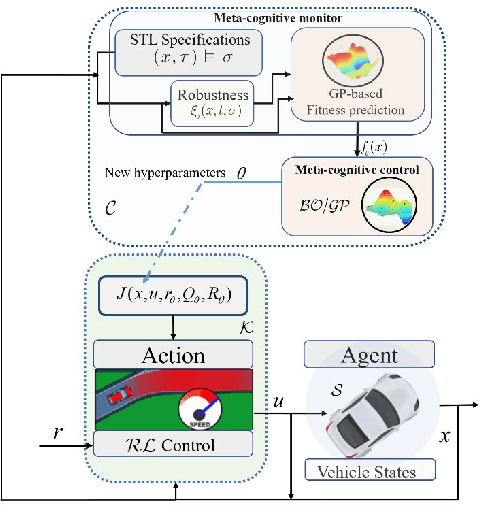


Reinforcement learning (RL) agents with pre-specified reward functions cannot provide guaranteed safety across variety of circumstances that an uncertain system might encounter. To guarantee performance while assuring satisfaction of safety constraints across variety of circumstances, an assured autonomous control framework is presented in this paper by empowering RL algorithms with metacognitive learning capabilities. More specifically, adapting the reward function parameters of the RL agent is performed in a metacognitive decision-making layer to assure the feasibility of RL agent. That is, to assure that the learned policy by the RL agent satisfies safety constraints specified by signal temporal logic while achieving as much performance as possible. The metacognitive layer monitors any possible future safety violation under the actions of the RL agent and employs a higher-layer Bayesian RL algorithm to proactively adapt the reward function for the lower-layer RL agent. To minimize the higher-layer Bayesian RL intervention, a fitness function is leveraged by the metacognitive layer as a metric to evaluate success of the lower-layer RL agent in satisfaction of safety and liveness specifications, and the higher-layer Bayesian RL intervenes only if there is a risk of lower-layer RL failure. Finally, a simulation example is provided to validate the effectiveness of the proposed approach.
Interpretable-AI Policies using Evolutionary Nonlinear Decision Trees for Discrete Action Systems
Sep 20, 2020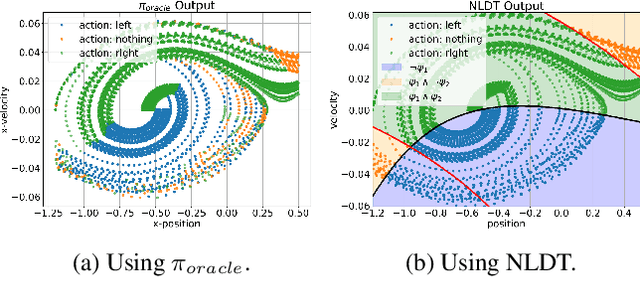

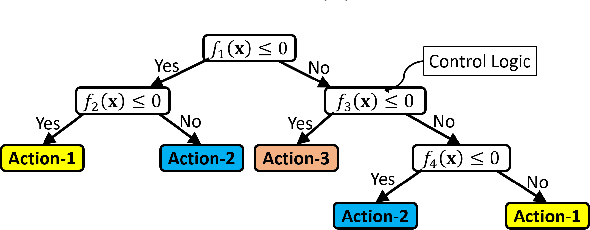

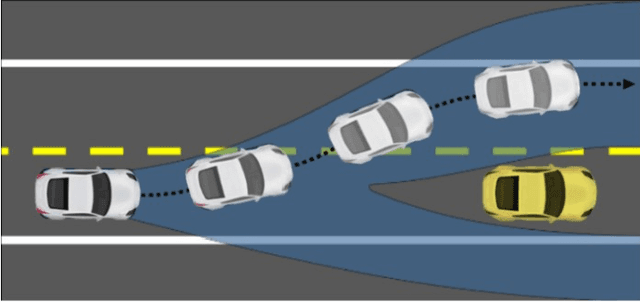
Black-box artificial intelligence (AI) induction methods such as deep reinforcement learning (DRL) are increasingly being used to find optimal policies for a given control task. Although policies represented using a black-box AI are capable of efficiently executing the underlying control task and achieving optimal closed-loop performance -- controlling the agent from initial time step until the successful termination of an episode, the developed control rules are often complex and neither interpretable nor explainable. In this paper, we use a recently proposed nonlinear decision-tree (NLDT) approach to find a hierarchical set of control rules in an attempt to maximize the open-loop performance for approximating and explaining the pre-trained black-box DRL (oracle) agent using the labelled state-action dataset. Recent advances in nonlinear optimization approaches using evolutionary computation facilitates finding a hierarchical set of nonlinear control rules as a function of state variables using a computationally fast bilevel optimization procedure at each node of the proposed NLDT. Additionally, we propose a re-optimization procedure for enhancing closed-loop performance of an already derived NLDT. We evaluate our proposed methodologies on four different control problems having two to four discrete actions. In all these problems our proposed approach is able to find simple and interpretable rules involving one to four non-linear terms per rule, while simultaneously achieving on par closed-loop performance when compared to a trained black-box DRL agent. The obtained results are inspiring as they suggest the replacement of complicated black-box DRL policies involving thousands of parameters (making them non-interpretable) with simple interpretable policies. Results are encouraging and motivating to pursue further applications of proposed approach in solving more complex control tasks.
An online evolving framework for advancing reinforcement-learning based automated vehicle control
Jun 16, 2020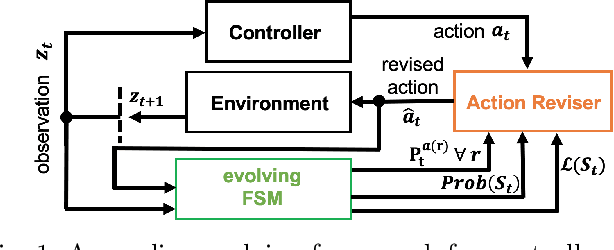

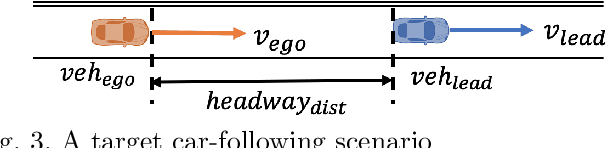
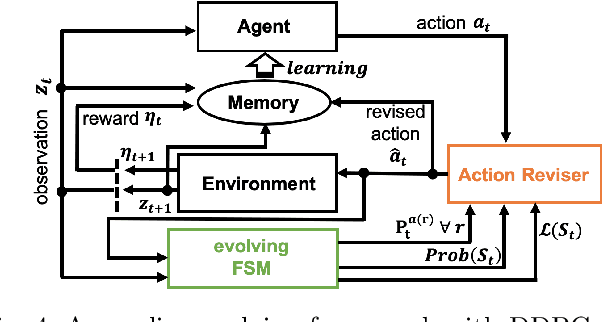
In this paper, an online evolving framework is proposed to detect and revise a controller's imperfect decision-making in advance. The framework consists of three modules: the evolving Finite State Machine (e-FSM), action-reviser, and controller modules. The e-FSM module evolves a stochastic model (e.g., Discrete-Time Markov Chain) from scratch by determining new states and identifying transition probabilities repeatedly. With the latest stochastic model and given criteria, the action-reviser module checks validity of the controller's chosen action by predicting future states. Then, if the chosen action is not appropriate, another action is inspected and selected. In order to show the advantage of the proposed framework, the Deep Deterministic Policy Gradient (DDPG) w/ and w/o the online evolving framework are applied to control an ego-vehicle in the car-following scenario where control criteria are set by speed and safety. Experimental results show that inappropriate actions chosen by the DDPG controller are detected and revised appropriately through our proposed framework, resulting in no control failures after a few iterations.
Generating Socially Acceptable Perturbations for Efficient Evaluation of Autonomous Vehicles
Mar 18, 2020


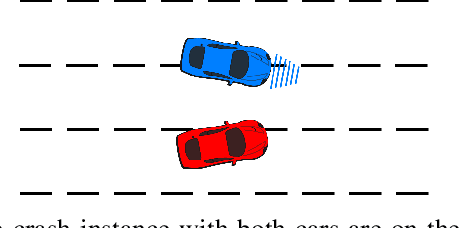
Deep reinforcement learning methods have been widely used in recent years for autonomous vehicle's decision-making. A key issue is that deep neural networks can be fragile to adversarial attacks or other unseen inputs. In this paper, we address the latter issue: we focus on generating socially acceptable perturbations (SAP), so that the autonomous vehicle (AV agent), instead of the challenging vehicle (attacker), is primarily responsible for the crash. In our process, one attacker is added to the environment and trained by deep reinforcement learning to generate the desired perturbation. The reward is designed so that the attacker aims to fail the AV agent in a socially acceptable way. After training the attacker, the agent policy is evaluated in both the original naturalistic environment and the environment with one attacker. The results show that the agent policy which is safe in the naturalistic environment has many crashes in the perturbed environment.
Deep Reinforcement Learning with Enhanced Safety for Autonomous Highway Driving
Oct 28, 2019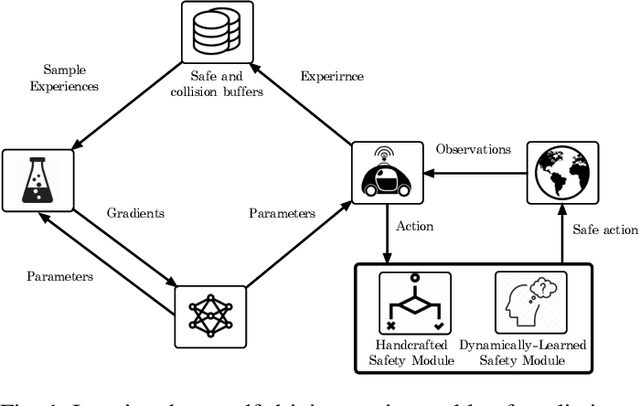

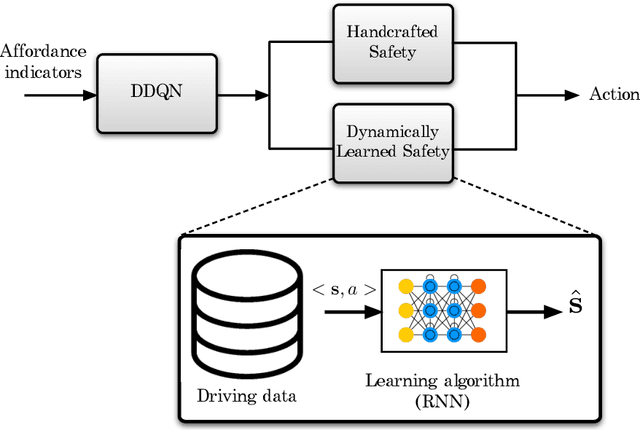
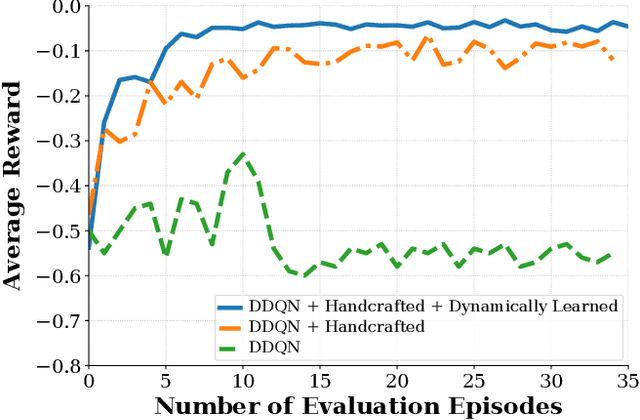
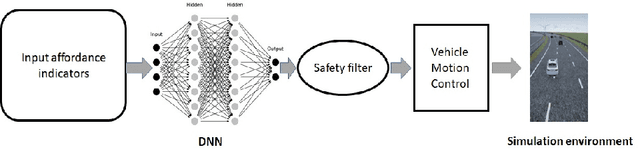
In this paper, we present a safe deep reinforcement learning system for automated driving. The proposed framework leverages merits of both rule-based and learning-based approaches for safety assurance. Our safety system consists of two modules namely handcrafted safety and dynamically-learned safety. The handcrafted safety module is a heuristic safety rule based on common driving practice that ensure a minimum relative gap to a traffic vehicle. On the other hand, the dynamically-learned safety module is a data-driven safety rule that learns safety patterns from driving data. Specifically, the dynamically-leaned safety module incorporates a model lookahead beyond the immediate reward of reinforcement learning to predict safety longer into the future. If one of the future states leads to a near-miss or collision, then a negative reward will be assigned to the reward function to avoid collision and accelerate the learning process. We demonstrate the capability of the proposed framework in a simulation environment with varying traffic density. Our results show the superior capabilities of the policy enhanced with dynamically-learned safety module.
Autonomous Highway Driving using Deep Reinforcement Learning
Mar 29, 2019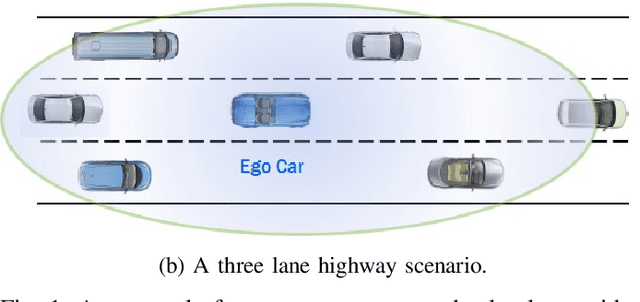
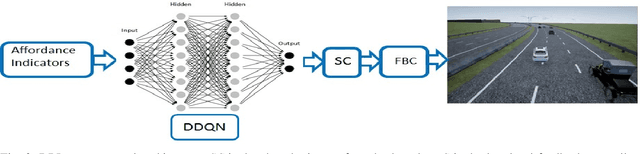

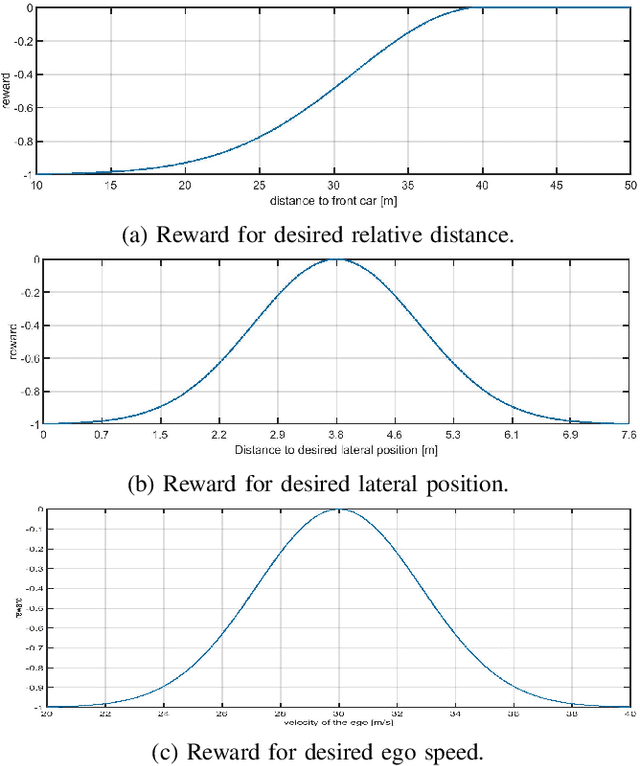
The operational space of an autonomous vehicle (AV) can be diverse and vary significantly. This may lead to a scenario that was not postulated in the design phase. Due to this, formulating a rule based decision maker for selecting maneuvers may not be ideal. Similarly, it may not be effective to design an a-priori cost function and then solve the optimal control problem in real-time. In order to address these issues and to avoid peculiar behaviors when encountering unforeseen scenario, we propose a reinforcement learning (RL) based method, where the ego car, i.e., an autonomous vehicle, learns to make decisions by directly interacting with simulated traffic. The decision maker for AV is implemented as a deep neural network providing an action choice for a given system state. In a critical application such as driving, an RL agent without explicit notion of safety may not converge or it may need extremely large number of samples before finding a reliable policy. To best address the issue, this paper incorporates reinforcement learning with an additional short horizon safety check (SC). In a critical scenario, the safety check will also provide an alternate safe action to the agent provided if it exists. This leads to two novel contributions. First, it generalizes the states that could lead to undesirable "near-misses" or "collisions ". Second, inclusion of safety check can provide a safe and stable training environment. This significantly enhances learning efficiency without inhibiting meaningful exploration to ensure safe and optimal learned behavior. We demonstrate the performance of the developed algorithm in highway driving scenario where the trained AV encounters varying traffic density in a highway setting.