 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Distributional Reinforcement Learning with Distributional Critic Regularization
Mar 18, 2026Federated reinforcement learning typically aggregates value functions or policies by parameter averaging, which emphasizes expected return and can obscure statistical multimodality and tail behavior that matter in safety-critical settings. We formalize federated distributional reinforcement learning (FedDistRL), where clients parametrize quantile value function critics and federate these networks only. We also propose TR-FedDistRL, which builds a per client, risk-aware Wasserstein barycenter over a temporal buffer. This local barycenter provides a reference region to constrain the parameter averaged critic, ensuring necessary distributional information is not averaged out during the federation process. The distributional trust region is implemented as a shrink-squash step around this reference. Under fixed-policy evaluation, the feasibility map is nonexpansive and the update is contractive in a probe-set Wasserstein metric under evaluation. Experiments on a bandit, multi-agent gridworld, and continuous highway environment show reduced mean-smearing, improved safety proxies (catastrophe/accident rate), and lower critic/policy drift versus mean-oriented and non-federated baselines.
Geometry-Aware Uncertainty Quantification via Conformal Prediction on Manifolds
Feb 17, 2026Conformal prediction provides distribution-free coverage guaranties for regression; yet existing methods assume Euclidean output spaces and produce prediction regions that are poorly calibrated when responses lie on Riemannian manifolds. We propose \emph{adaptive geodesic conformal prediction}, a framework that replaces Euclidean residuals with geodesic nonconformity scores and normalizes them by a cross-validated difficulty estimator to handle heteroscedastic noise. The resulting prediction regions, geodesic caps on the sphere, have position-independent area and adapt their size to local prediction difficulty, yielding substantially more uniform conditional coverage than non-adaptive alternatives. In a synthetic sphere experiment with strong heteroscedasticity and a real-world geomagnetic field forecasting task derived from IGRF-14 satellite data, the adaptive method markedly reduces conditional coverage variability and raises worst-case coverage much closer to the nominal level, while coordinate-based baselines waste a large fraction of coverage area due to chart distortion.
Logic-Guided Vector Fields for Constrained Generative Modeling
Feb 02, 2026Neuro-symbolic systems aim to combine the expressive structure of symbolic logic with the flexibility of neural learning; yet, generative models typically lack mechanisms to enforce declarative constraints at generation time. We propose Logic-Guided Vector Fields (LGVF), a neuro-symbolic framework that injects symbolic knowledge, specified as differentiable relaxations of logical constraints, into flow matching generative models. LGVF couples two complementary mechanisms: (1) a training-time logic loss that penalizes constraint violations along continuous flow trajectories, with weights that emphasize correctness near the target distribution; and (2) an inference-time adjustment that steers sampling using constraint gradients, acting as a lightweight, logic-informed correction to the learned dynamics. We evaluate LGVF on three constrained generation case studies spanning linear, nonlinear, and multi-region feasibility constraints. Across all settings, LGVF reduces constraint violations by 59-82% compared to standard flow matching and achieves the lowest violation rates in each case. In the linear and ring settings, LGVF also improves distributional fidelity as measured by MMD, while in the multi-obstacle setting, we observe a satisfaction-fidelity trade-off, with improved feasibility but increased MMD. Beyond quantitative gains, LGVF yields constraint-aware vector fields exhibiting emergent obstacle-avoidance behavior, routing samples around forbidden regions without explicit path planning.
Adaptive Conformal Prediction via Bayesian Uncertainty Weighting for Hierarchical Healthcare Data
Jan 03, 2026Clinical decision-making demands uncertainty quantification that provides both distribution-free coverage guarantees and risk-adaptive precision, requirements that existing methods fail to jointly satisfy. We present a hybrid Bayesian-conformal framework that addresses this fundamental limitation in healthcare predictions. Our approach integrates Bayesian hierarchical random forests with group-aware conformal calibration, using posterior uncertainties to weight conformity scores while maintaining rigorous coverage validity. Evaluated on 61,538 admissions across 3,793 U.S. hospitals and 4 regions, our method achieves target coverage (94.3% vs 95% target) with adaptive precision: 21% narrower intervals for low-uncertainty cases while appropriately widening for high-risk predictions. Critically, we demonstrate that well-calibrated Bayesian uncertainties alone severely under-cover (14.1%), highlighting the necessity of our hybrid approach. This framework enables risk-stratified clinical protocols, efficient resource planning for high-confidence predictions, and conservative allocation with enhanced oversight for uncertain cases, providing uncertainty-aware decision support across diverse healthcare settings.
Can Optimal Transport Improve Federated Inverse Reinforcement Learning?
Jan 01, 2026In robotics and multi-agent systems, fleets of autonomous agents often operate in subtly different environments while pursuing a common high-level objective. Directly pooling their data to learn a shared reward function is typically impractical due to differences in dynamics, privacy constraints, and limited communication bandwidth. This paper introduces an optimal transport-based approach to federated inverse reinforcement learning (IRL). Each client first performs lightweight Maximum Entropy IRL locally, adhering to its computational and privacy limitations. The resulting reward functions are then fused via a Wasserstein barycenter, which considers their underlying geometric structure. We further prove that this barycentric fusion yields a more faithful global reward estimate than conventional parameter averaging methods in federated learning. Overall, this work provides a principled and communication-efficient framework for deriving a shared reward that generalizes across heterogeneous agents and environments.
Density-Ratio Weighted Behavioral Cloning: Learning Control Policies from Corrupted Datasets
Oct 01, 2025Offline reinforcement learning (RL) enables policy optimization from fixed datasets, making it suitable for safety-critical applications where online exploration is infeasible. However, these datasets are often contaminated by adversarial poisoning, system errors, or low-quality samples, leading to degraded policy performance in standard behavioral cloning (BC) and offline RL methods. This paper introduces Density-Ratio Weighted Behavioral Cloning (Weighted BC), a robust imitation learning approach that uses a small, verified clean reference set to estimate trajectory-level density ratios via a binary discriminator. These ratios are clipped and used as weights in the BC objective to prioritize clean expert behavior while down-weighting or discarding corrupted data, without requiring knowledge of the contamination mechanism. We establish theoretical guarantees showing convergence to the clean expert policy with finite-sample bounds that are independent of the contamination rate. A comprehensive evaluation framework is established, which incorporates various poisoning protocols (reward, state, transition, and action) on continuous control benchmarks. Experiments demonstrate that Weighted BC maintains near-optimal performance even at high contamination ratios outperforming baselines such as traditional BC, batch-constrained Q-learning (BCQ) and behavior regularized actor-critic (BRAC).
Split Conformal Prediction in the Function Space with Neural Operators
Sep 04, 2025Uncertainty quantification for neural operators remains an open problem in the infinite-dimensional setting due to the lack of finite-sample coverage guarantees over functional outputs. While conformal prediction offers finite-sample guarantees in finite-dimensional spaces, it does not directly extend to function-valued outputs. Existing approaches (Gaussian processes, Bayesian neural networks, and quantile-based operators) require strong distributional assumptions or yield conservative coverage. This work extends split conformal prediction to function spaces following a two step method. We first establish finite-sample coverage guarantees in a finite-dimensional space using a discretization map in the output function space. Then these guarantees are lifted to the function-space by considering the asymptotic convergence as the discretization is refined. To characterize the effect of resolution, we decompose the conformal radius into discretization, calibration, and misspecification components. This decomposition motivates a regression-based correction to transfer calibration across resolutions. Additionally, we propose two diagnostic metrics (conformal ensemble score and internal agreement) to quantify forecast degradation in autoregressive settings. Empirical results show that our method maintains calibrated coverage with less variation under resolution shifts and achieves better coverage in super-resolution tasks.
Wasserstein Barycenter Soft Actor-Critic
Jun 11, 2025Deep off-policy actor-critic algorithms have emerged as the leading framework for reinforcement learning in continuous control domains. However, most of these algorithms suffer from poor sample efficiency, especially in environments with sparse rewards. In this paper, we take a step towards addressing this issue by providing a principled directed exploration strategy. We propose Wasserstein Barycenter Soft Actor-Critic (WBSAC) algorithm, which benefits from a pessimistic actor for temporal difference learning and an optimistic actor to promote exploration. This is achieved by using the Wasserstein barycenter of the pessimistic and optimistic policies as the exploration policy and adjusting the degree of exploration throughout the learning process. We compare WBSAC with state-of-the-art off-policy actor-critic algorithms and show that WBSAC is more sample-efficient on MuJoCo continuous control tasks.
DEF: Diffusion-augmented Ensemble Forecasting
Jun 08, 2025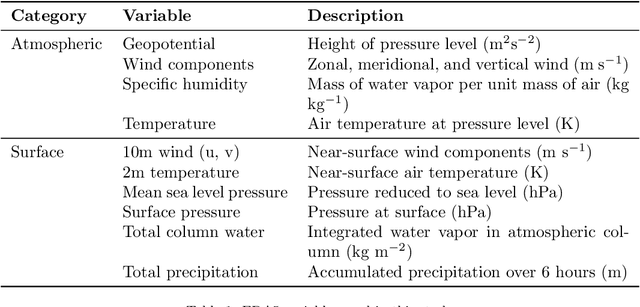

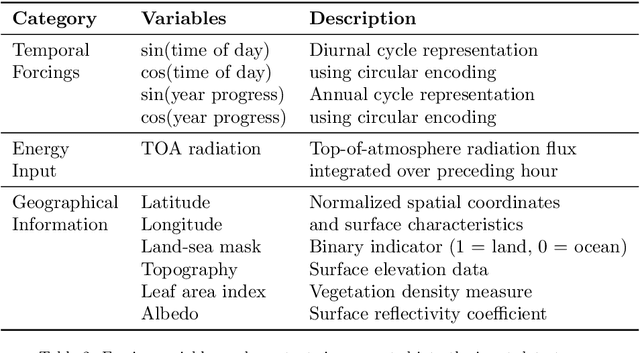

We present DEF (\textbf{\ul{D}}iffusion-augmented \textbf{\ul{E}}nsemble \textbf{\ul{F}}orecasting), a novel approach for generating initial condition perturbations. Modern approaches to initial condition perturbations are primarily designed for numerical weather prediction (NWP) solvers, limiting their applicability in the rapidly growing field of machine learning for weather prediction. Consequently, stochastic models in this domain are often developed on a case-by-case basis. We demonstrate that a simple conditional diffusion model can (1) generate meaningful structured perturbations, (2) be applied iteratively, and (3) utilize a guidance term to intuitivey control the level of perturbation. This method enables the transformation of any deterministic neural forecasting system into a stochastic one. With our stochastic extended systems, we show that the model accumulates less error over long-term forecasts while producing meaningful forecast distributions. We validate our approach on the 5.625$^\circ$ ERA5 reanalysis dataset, which comprises atmospheric and surface variables over a discretized global grid, spanning from the 1960s to the present. On this dataset, our method demonstrates improved predictive performance along with reasonable spread estimates.
Hierarchical Neuro-Symbolic Decision Transformer
Mar 10, 2025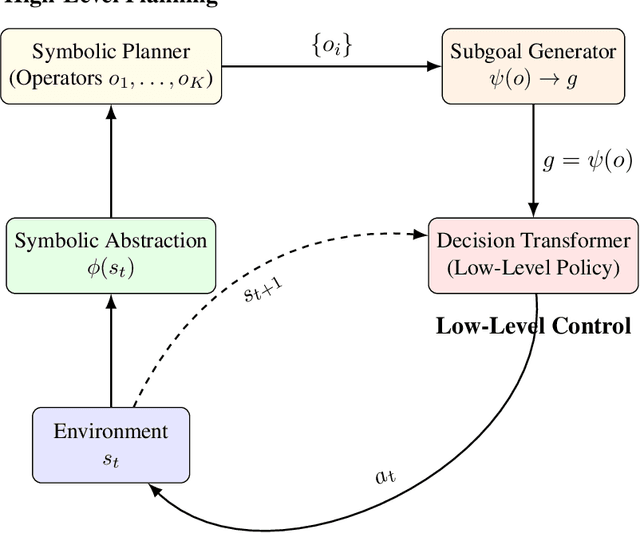
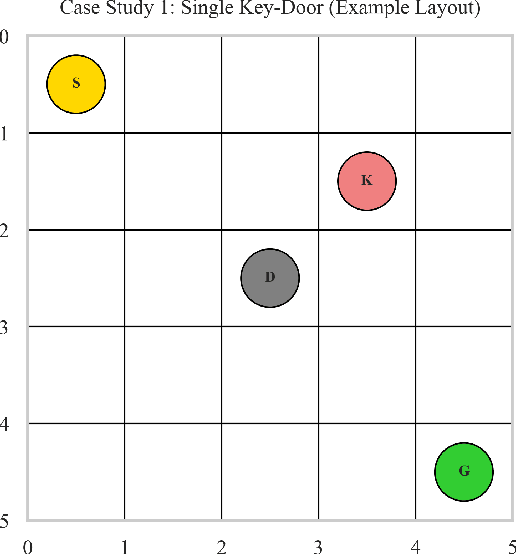
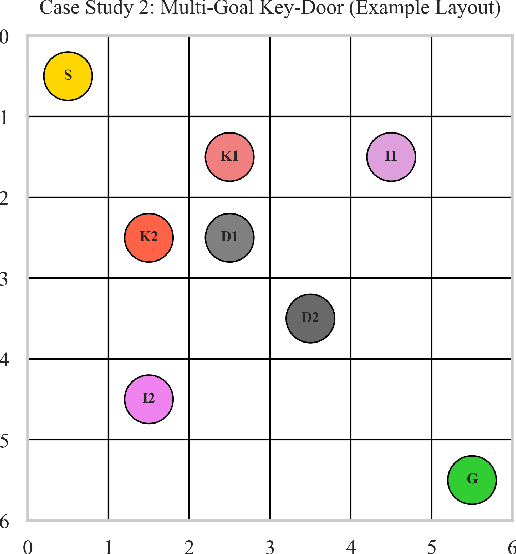
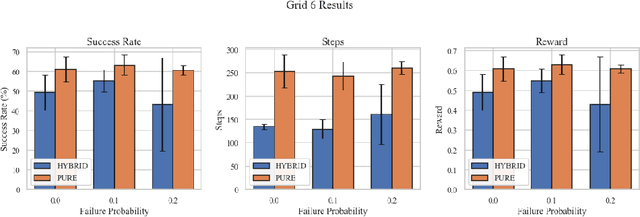
We present a hierarchical neuro-symbolic control framework that couples classical symbolic planning with transformer-based policies to address complex, long-horizon decision-making tasks. At the high level, a symbolic planner constructs an interpretable sequence of operators based on logical propositions, ensuring systematic adherence to global constraints and goals. At the low level, each symbolic operator is translated into a sub-goal token that conditions a decision transformer to generate a fine-grained sequence of actions in uncertain, high-dimensional environments. We provide theoretical analysis showing how approximation errors from both the symbolic planner and the neural execution layer accumulate. Empirical evaluations in grid-worlds with multiple keys, locked doors, and item-collection tasks show that our hierarchical approach outperforms purely end-to-end neural approach in success rates and policy efficiency.