 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein Barycenter Soft Actor-Critic
Jun 11, 2025Deep off-policy actor-critic algorithms have emerged as the leading framework for reinforcement learning in continuous control domains. However, most of these algorithms suffer from poor sample efficiency, especially in environments with sparse rewards. In this paper, we take a step towards addressing this issue by providing a principled directed exploration strategy. We propose Wasserstein Barycenter Soft Actor-Critic (WBSAC) algorithm, which benefits from a pessimistic actor for temporal difference learning and an optimistic actor to promote exploration. This is achieved by using the Wasserstein barycenter of the pessimistic and optimistic policies as the exploration policy and adjusting the degree of exploration throughout the learning process. We compare WBSAC with state-of-the-art off-policy actor-critic algorithms and show that WBSAC is more sample-efficient on MuJoCo continuous control tasks.
Risk-Averse Reinforcement Learning: An Optimal Transport Perspective on Temporal Difference Learning
Feb 22, 2025


The primary goal of reinforcement learning is to develop decision-making policies that prioritize optimal performance, frequently without considering risk or safety. In contrast, safe reinforcement learning seeks to reduce or avoid unsafe states. This letter introduces a risk-averse temporal difference algorithm that uses optimal transport theory to direct the agent toward predictable behavior. By incorporating a risk indicator, the agent learns to favor actions with predictable consequences. We evaluate the proposed algorithm in several case studies and show its effectiveness in the presence of uncertainty. The results demonstrate that our method reduces the frequency of visits to risky states while preserving performance. A Python implementation of the algorithm is available at https:// github.com/SAILRIT/Risk-averse-TD-Learning.
Optimizing Falsification for Learning-Based Control Systems: A Multi-Fidelity Bayesian Approach
Sep 12, 2024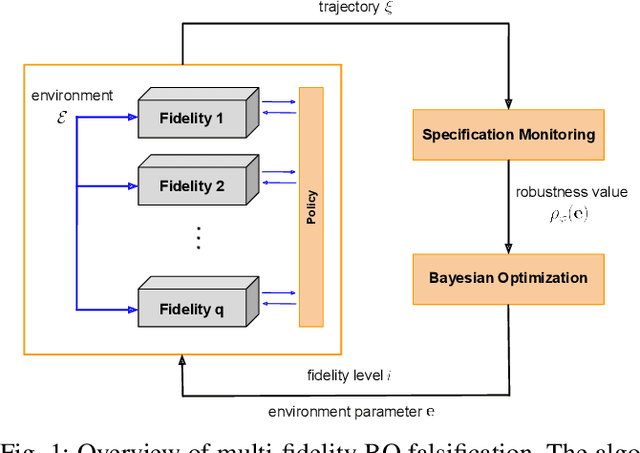
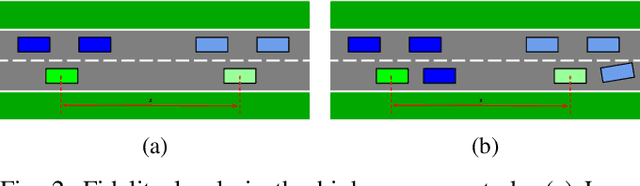
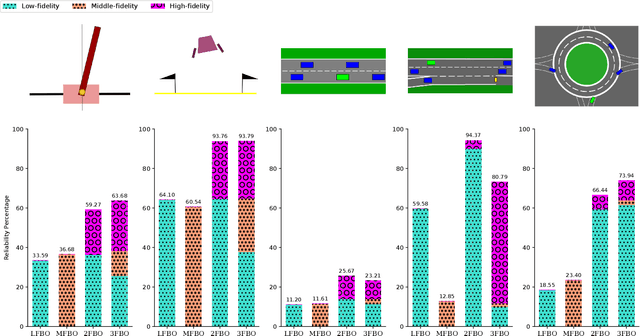
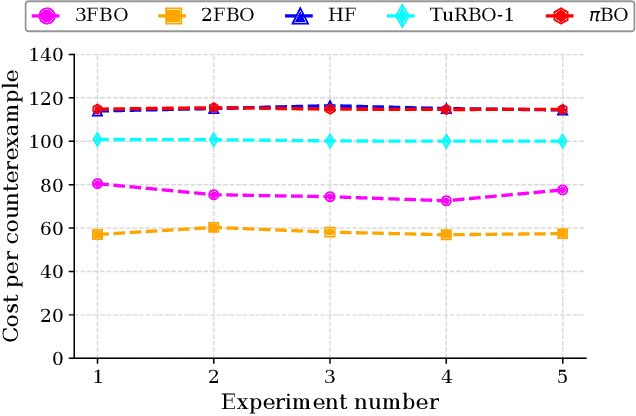
Testing controllers in safety-critical systems is vital for ensuring their safety and preventing failures. In this paper, we address the falsification problem within learning-based closed-loop control systems through simulation. This problem involves the identification of counterexamples that violate system safety requirements and can be formulated as an optimization task based on these requirements. Using full-fidelity simulator data in this optimization problem can be computationally expensive. To improve efficiency, we propose a multi-fidelity Bayesian optimization falsification framework that harnesses simulators with varying levels of accuracy. Our proposed framework can transition between different simulators and establish meaningful relationships between them. Through multi-fidelity Bayesian optimization, we determine both the optimal system input likely to be a counterexample and the appropriate fidelity level for assessment. We evaluated our approach across various Gym environments, each featuring different levels of fidelity. Our experiments demonstrate that multi-fidelity Bayesian optimization is more computationally efficient than full-fidelity Bayesian optimization and other baseline methods in detecting counterexamples. A Python implementation of the algorithm is available at https://github.com/SAILRIT/MFBO_Falsification.
Optimal Transport-Assisted Risk-Sensitive Q-Learning
Jun 17, 2024



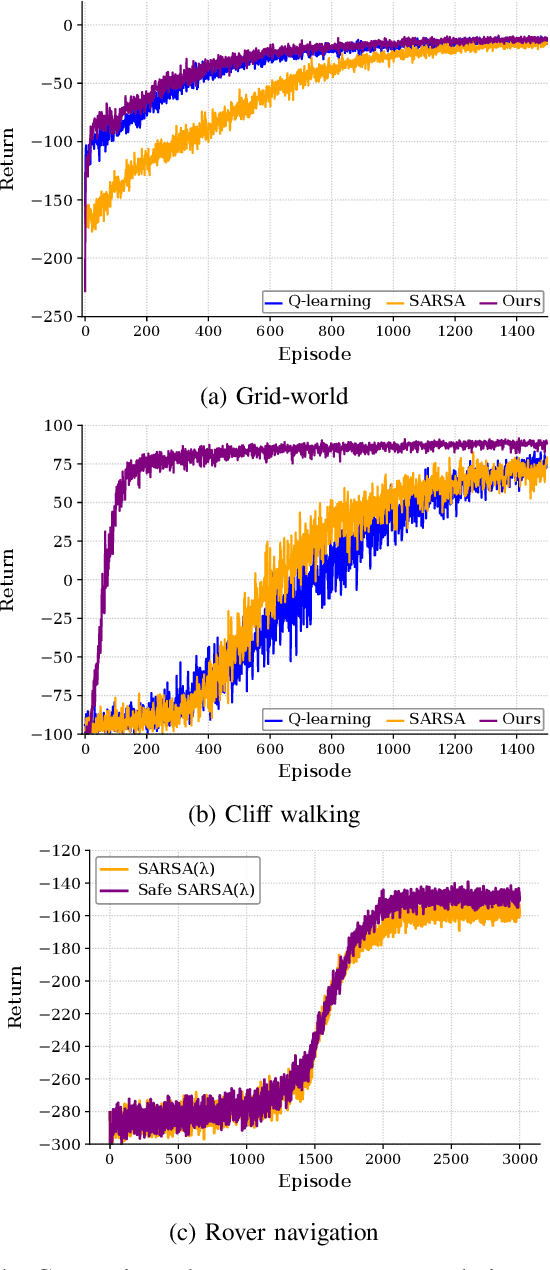
The primary goal of reinforcement learning is to develop decision-making policies that prioritize optimal performance without considering risk or safety. In contrast, safe reinforcement learning aims to mitigate or avoid unsafe states. This paper presents a risk-sensitive Q-learning algorithm that leverages optimal transport theory to enhance the agent safety. By integrating optimal transport into the Q-learning framework, our approach seeks to optimize the policy's expected return while minimizing the Wasserstein distance between the policy's stationary distribution and a predefined risk distribution, which encapsulates safety preferences from domain experts. We validate the proposed algorithm in a Gridworld environment. The results indicate that our method significantly reduces the frequency of visits to risky states and achieves faster convergence to a stable policy compared to the traditional Q-learning algorithm.
Falsification of Learning-Based Controllers through Multi-Fidelity Bayesian Optimization
Jan 04, 2023
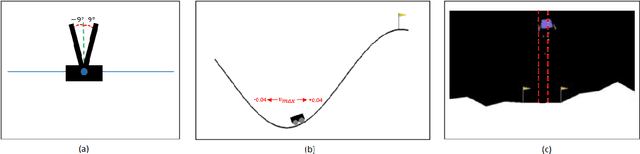

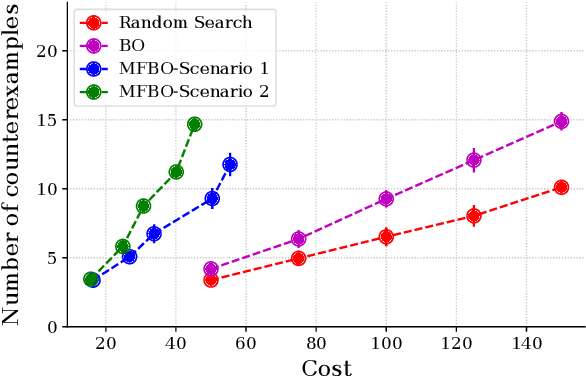
Simulation-based falsification is a practical testing method to increase confidence that the system will meet safety requirements. Because full-fidelity simulations can be computationally demanding, we investigate the use of simulators with different levels of fidelity. As a first step, we express the overall safety specification in terms of environmental parameters and structure this safety specification as an optimization problem. We propose a multi-fidelity falsification framework using Bayesian optimization, which is able to determine at which level of fidelity we should conduct a safety evaluation in addition to finding possible instances from the environment that cause the system to fail. This method allows us to automatically switch between inexpensive, inaccurate information from a low-fidelity simulator and expensive, accurate information from a high-fidelity simulator in a cost-effective way. Our experiments on various environments in simulation demonstrate that multi-fidelity Bayesian optimization has falsification performance comparable to single-fidelity Bayesian optimization but with much lower cost.