 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Averse Reinforcement Learning: An Optimal Transport Perspective on Temporal Difference Learning
Paper and Code



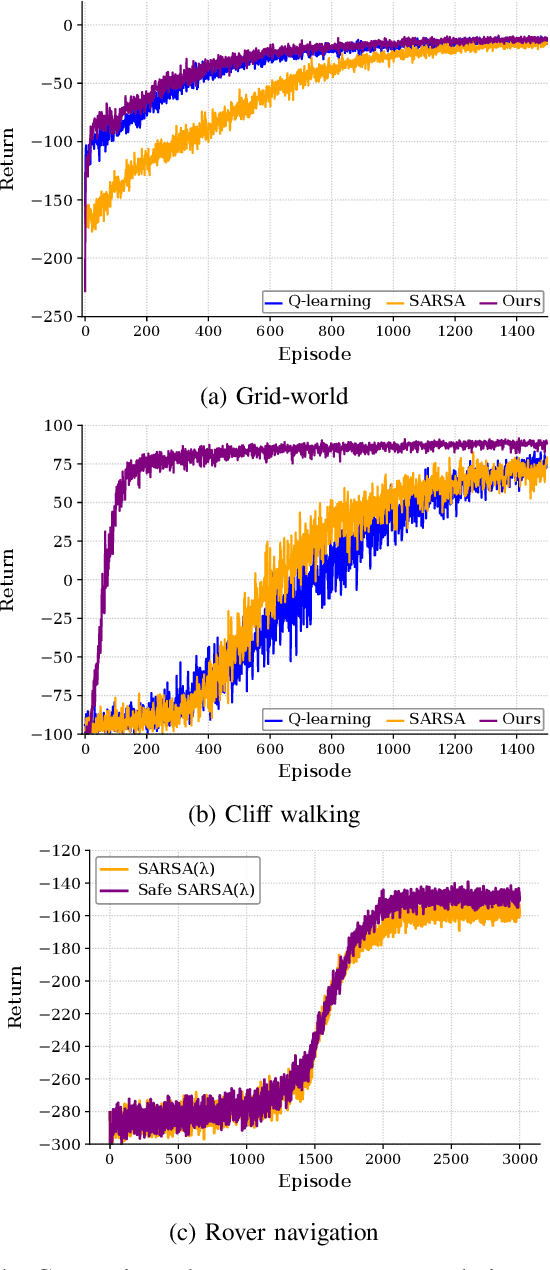
The primary goal of reinforcement learning is to develop decision-making policies that prioritize optimal performance, frequently without considering risk or safety. In contrast, safe reinforcement learning seeks to reduce or avoid unsafe states. This letter introduces a risk-averse temporal difference algorithm that uses optimal transport theory to direct the agent toward predictable behavior. By incorporating a risk indicator, the agent learns to favor actions with predictable consequences. We evaluate the proposed algorithm in several case studies and show its effectiveness in the presence of uncertainty. The results demonstrate that our method reduces the frequency of visits to risky states while preserving performance. A Python implementation of the algorithm is available at https:// github.com/SAILRIT/Risk-averse-TD-Learning.